


We’ve been watching new ways of handling data emerge in EDA-land for a while now. One of the earliest we discussed was IC Manage’s Envision product, which used big-data techniques to help manage design progress and resources like people, servers, and licenses. Then came Ansys with their big-data platform. And then Solido with a machine-learning labs offering. And now IC Manage is rolling out a big-data labs capability.
Each of these announcements bears similarity to the others, but they’re not necessarily the same. So let’s dig in to see where some of the nuance lies.
Big Data vs. Machine Learning
A few years back, “big data” was all the rage. Today, it’s somewhat passé, having been replaced by machine learning or deep learning as the new kid in town. (And it’s not even that new anymore.) And yet somehow it’s easy to conflate these two notions – big data and machine learning – when, in fact, they’re different.
Big data seems to have arisen out of the general desire to hoover up all the internet data and then learn something from it. The problem is… well… a couple things. First, there’s an enormous amount of data out there, and it’s growing at an enormous pace. So one challenge is simply getting stuff out faster than it’s going in.
The second challenge is that what’s out there is something of a jumble of data types and formats. Text files; video files; audio files; scripts; pictures of all types… You just have to haul it over the transom and do something quick with it so you can go get the next things.
What you do with the data afterwards isn’t really defined. There are definitely tools that have emerged to help view databases of unstructured data that likely aren’t classical relational databases relying on SQL for running queries. But, other than that, it’s up to the data analyst to cobble together open-source tools and perhaps script some of his or her own.
And that’s one of the keys to this notion: doing something with the data is a manual thing. Yeah, you may script it to make it quicker, but whatever you’re doing in the script is something that you (or some other human) came up with.
That’s as contrasted with machine learning, or ML. When rummaging through data to build some useful model or something, the analyst is in control with big data. With ML, the machine is in control. The analyst feeds the machine learning examples (at least in the case of supervised learning), but the machine-learning algorithm then builds the model. And that model will depend specifically on the examples fed in – and even on the order in which they’re fed in.
So the analyst has some ability to influence the ML-generated model, but not in a direct way. And if the analyst tries to actually look at the model, it’s not going to be recognizable. It’s a matrix (or several matrices) of numbers – weights and such. It will look very abstract.
Make Mine a Labs, Please
So that’s the distinction between big data and machine learning. But there’s an orthogonal notion running through this EDA history as well. In some cases – ok, in one case – IC Manage announces (a couple of years ago, not lately) a tool that makes use of big data notions and engines and such, but the offering to the customer, in the end, is a tool.
The other two stories we saw in the past took things one step further. They realized that, if they got their infrastructure in order, then they’d have this generic capability of playing with data for a solving a number of different problems that their customers might have. And so the customers work with the vendor to get the tool they want. And that tool can also be sold on the market, leveraging the work done.
We saw another story about Invionics – not necessarily a big-data or a machine-learning story, but rather one where they were making bespoke EDA apps for customers. In that case, customers were going to them to get a tool that gave them a competitive advantage. If that tool were then available to the competitors, then that advantage would be lost. So, in that case, the tools remained only with the original customer.
That doesn’t seem to be the case with these labs situations, whether big data or ML. You routinely hear that their customers aren’t asking for exclusivity – not even for some period of time. And so the resulting tools become part of the overall EDA offering of whichever company built the tool. And the advertised basis for this effort is a “platform,” and the tool-factory part of it is often marketed as being “labs.”
What’s new for this story is that IC Manage – the earliest player I’m aware of in our big-data game – has now gone from simply having their Envision tool, which is based on big-data concepts, to having a big-data labs platform from which they can generate new tools. They take structured and unstructured data and create relationships and models from it. This work is done by humans, so it’s not a machine-learning exercise.
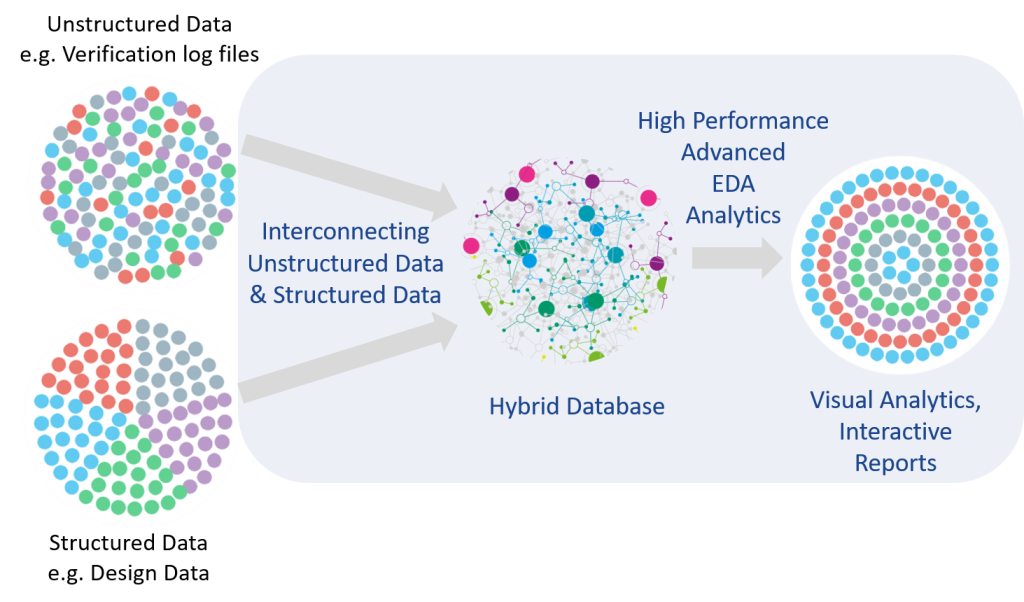
(Image courtesy IC Manage)
Of course, just analyzing data isn’t enough. You have to be able to present it in a relatable way. So GUI tools are a necessary part of any labs offering. Data visualization is paramount if anyone is going to make sense out of this stuff.
IC Manage has also announced their first new tool generated through the labs and the collaborative process that accompanies it. It’s called Envision Verification Analytics, or Envision-VA. Unlike Envision, which focuses on resources, this tool focuses on verification results – regressions and tests.
Part of the challenge is that, overall, an SoC is going to be verified by teams around the world, and there will be different data from different places that somehow has to come together in a cogent, understandable view that lets anyone – but particularly managers – see at a blink how things are going. That’s what Envision-VA is all about.
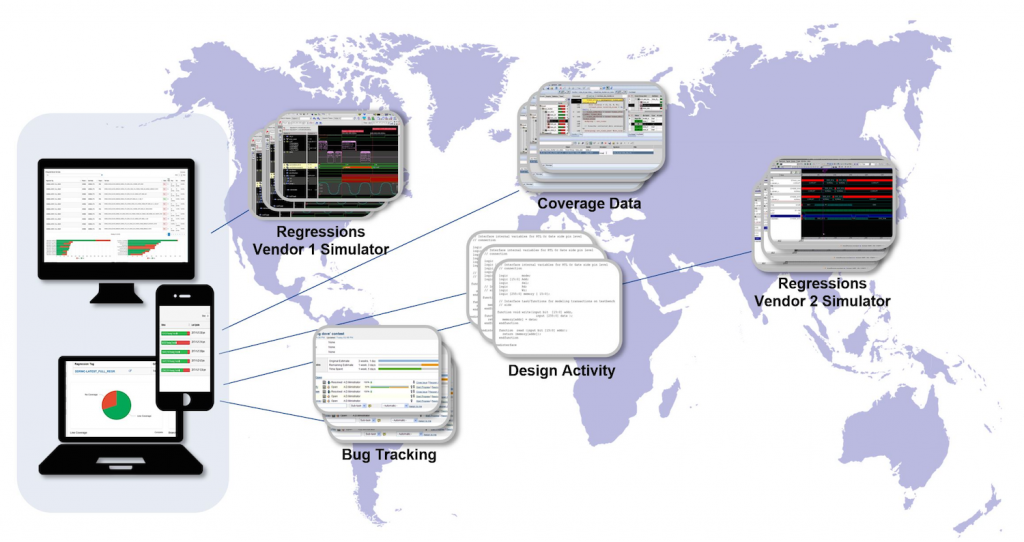
(Image courtesy IC Manage)
This labs capability somehow feels freeing. Whereas point tools in the past might take an enormous amount of custom coding and work on data types and organization, now big-data (or ML) infrastructure makes possible tools that both leverage the ability for customers to handle huge volumes of data in a reasonable manner and are more quickly created and launched.
Expect to be seeing more of this from IC Manage. And perhaps others.
More info:



What do you think of the Labs approach to data that IC Manage and others are using?