


Another day, another neural network solution. Seems to be the flavor of the year, not surprisingly, given that machine learning is on the ascendant. Earlier this year, we wrote about Cadence’s solution. Then we wrote about Synopsys’s solution. Well, today we look at yet another, this time from Imagination Technologies (IMG) – their PowerVR 2NX. And this discussion forces us to review some of the pros and cons of different configurations that we’ve looked at.
We talked before about accelerators for the convolution layers of a convolutional neural network (CNN). Today, we also discuss an accelerator – but for the entire neural network, not just convolution. And it can do types of neural nets besides CNNs.
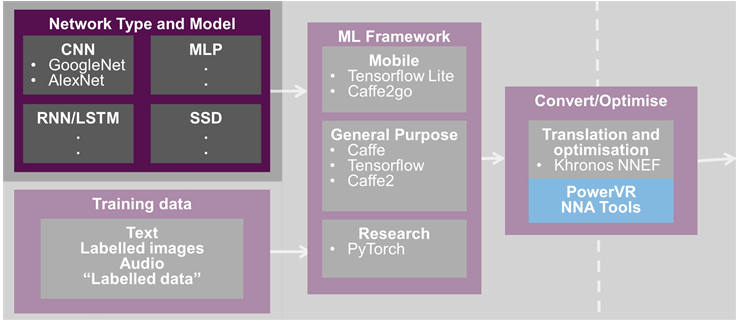
(Image courtesy Imagination Technologies; highlighting added)
The image above shows not just the types of neural nets that can be built (highlighted), but also the offline flow for training them. This then feeds into the platform for execution, as shown below.
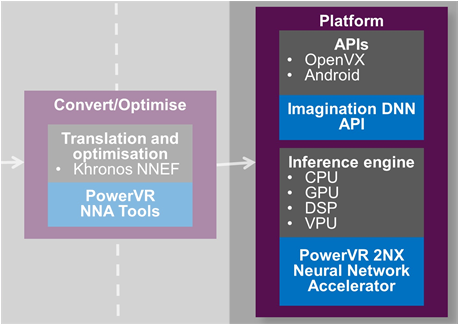
(Image courtesy Imagination Technologies; highlighting added)
While they favor their own just-announced GPU for implementation, saying that it’s comparatively small, they say that this accelerator can work with the processors shown of any brand, not just the IMG brand.
Platform architecture
The architecture of this acceleration platform is shown below.
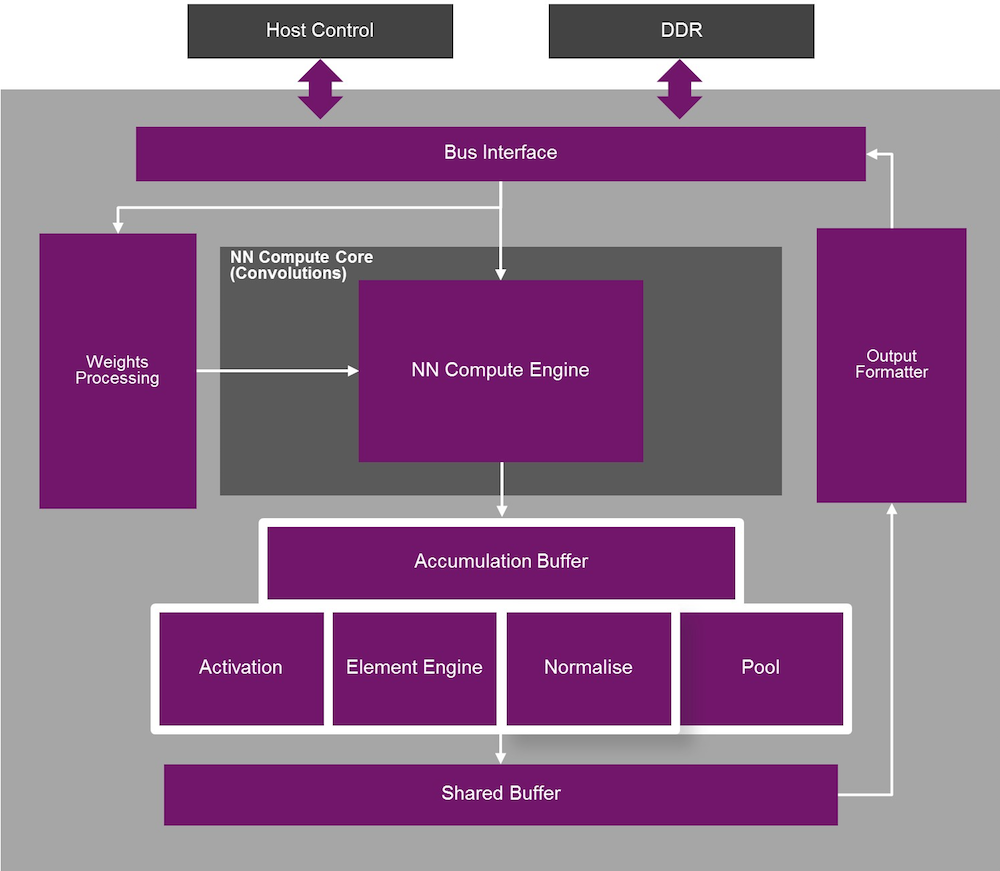 (Click to enlarge; Image courtesy Imagination Technologies)
(Click to enlarge; Image courtesy Imagination Technologies)
The main bit has a generic engine for those layers that are doing neural processing – that is, using a set of trained weights to generate one stage of the net. There are other built-in blocks for handling some of the other more administrative layers like pooling. Like Cadence, but unlike Synopsys, the block attaches to a separate host processor. We’ll talk more in a minute about who does and doesn’t think that’s a good idea. (Yeah, probably not hard to guess.)
One of the unique features of this engine is the ability to use arbitrary bit widths for both weights and data. This is as contrasted with Cadence supporting 8- and 16-bit fields and Synopsys supporting 12-bit fields. In addition, it would seem out of sync with training, which typically results in either 8- or 16-bit fields.
That latter point is one reason that Cadence prefers the canonical bit widths. But they also express concern that using weird bit widths makes the data inefficient to process for CPUs and such that work much better with byte- or word-aligned data.
The reason for optimizing the bit width is so that you can get the results you want for the fewest possible bits. Fewer bits means less bandwidth required when passing weights and data around, not to mention lower power. This is shown in the following image, where you get significant savings for a 1% change in accuracy (a relative number taken from a collection of images; it can vary by type of image and desired classification specificity).

(Image courtesy Imagination Technologies)
So are you losing the efficiency you think you’re gaining by having non-aligned field sizes? IMG says, “No.” They pad the data to give units that are aligned. Now… if you’re picturing using, say, 3-bit fields and then padding them to 8 bits, well, you’d have more padding than data. That also doesn’t sound efficient. (Although it appears that it’s really 4-bit alignment, not necessarily 8-bit, since they say that 4-bit fields don’t need padding). As it turns out, however, when communicating these fields, they pack them into 128-bit or even 256-bit chunks – and only the chunk needs padding. That drastically reduces the number of “wasted” padding bits.
They further added that, “Note that weights are only used internally by the NNA and thus alignment doesn’t really matter. … For data, the format used depends on who uses it. If it’s NNA we can pack again for memory burst efficiency and bandwidth. If it’s data, the CPU or GPU or something else needs to process it, then we can pack to different formats as the alignment and data type will impact the efficiency of the other IP blocks. So basically, as with all of our IP, we are very aware of system efficiency and optimisation and offer plenty of data format flexibility to ensure there no issues with byte alignments.”
As to the training, it usually starts with floating point numbers. So you then have to discretize to a bit width, and if you use an irregular number, then you may have to go back and retrain to tweak the weights. There are a number of ways both to retrain and to reduce the overall size of the solution; it’s typically an iterative process. So it can be more work than simply using 8 or 16 bits, but they see the benefits as being worth it for applications that don’t have unlimited resources. (You can find out more about retraining from a presentation linked at the bottom.)
Note also that not all layers need the same bit width. You may start with wider widths of data, shrinking them as you move through the network layers, as illustrated below.
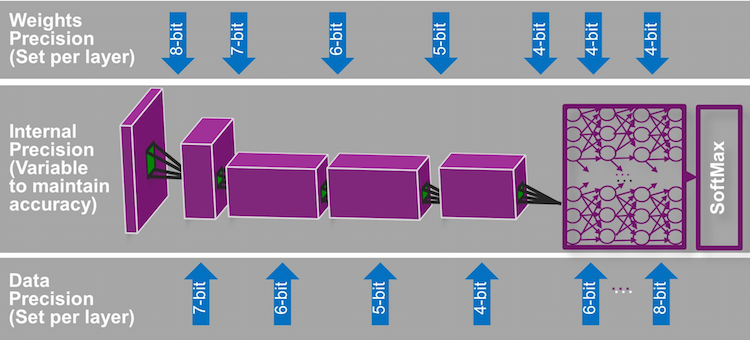
(Image courtesy Imagination Technologies)
How Does It Scale?
Scalability is another point of contention between the offerings we’ve seen. Cadence makes the point that, because their accelerator is decoupled from the host processors, you can scale the CNN portion and the host portion independently of each other, noting that, with the Synopsys block, if you need more CNN resources than are available in a single block, you have to replicate the host processors as well.
So I had a conversation with Synopsys to get their take on it. And it sounds like comparisons aren’t quite as easy as I was thinking. It gets a bit wonky here, so bear with me.
First, I really shouldn’t be using the word “host”: with any of these three solutions, there will presumably be another processor in the system that’s a “main” CPU, and that will invoke the vision acceleration (or whatever neural net is needed, in the IMG case). That would be the host; none of these integrates a host.
It also turns out that calling the processor in the Synopsys EV61+CNN block a “CPU” may set the wrong expectation of it being either a host or analogous to Cadence’s P6 vision processor. When I covered the Synopsys version, I compared the Synopsys block to a combination of the P6 and a C5 CNN accelerator. It may not be that straightforward.
Here’s what I think I’m understanding:
- Convolutional layers need lots of multiply-accumulate (MAC) instances. A pure convolution accelerator would consist mostly of these.
- Other layers may need other functions – like vector- and scalar-processing resources.
- Pre- and post-processing also will make use of vectors and scalars.
The question is where these blocks are put. The P5 and the EV61 (which, with its surrounding goodies, is the “CPU” portion of the EV61+CNN) are weighted more towards vectors and scalars. The C5 has lots of MACs and some vector and scalar, and can call on the P6 for more of the latter. The CNN part of the Synopsys block is more heavily weighted towards MACs. So that makes the EV61+CNN somewhere between a C5 and a C5+P6 in terms of functionality. But they believe that their EV61+CNN combined has roughly the same silicon area as a P6, and less than a C5.
What about IMG? From the image above, you can see that they have blocks for non-CNN layers as well as the convolution engine itself – some of which is done in hardware, further complicating comparisons. The intent is that all layers can be done within this block. They see an external processor handling pre- and post-processing.
Coming back to the scaling question, then, Cadence is relying on your ability to scale C5s and P6s independently of each other. Synopsys says they have two scaling levels. The first varies the number of CNN resources per pre-post-processor, although that scaling they do themselves, with two different products having two different amounts of CNN resources. The second scaling method involves simply replicating multiple blocks on the bus.
Synopsys’s vector and scalar resources are in that “CPU,” so that element is needed to implement all layers – meaning that you couldn’t really add only more CNN resources without also adding more of the “CPU” resources; both are needed. Because the EV61+CNN lies between a C5 and P6+C5, scaling Synopsys blocks isn’t necessarily like adding a P6 with every instance. You can think of the Synopsys processor’s vector and scalar resources as being divided between a P6 and a C5 in the Cadence version.
Scaling IMG means strictly scaling neural-net resources. Since pre- and post-processing is handled by a different, external CPU, the neural-net resources and pre-/post-processing resources can be independently scaled. There is, however, non-MAC logic in their block that gets replicated with each instance.
When it comes to performance, power, and area (PPA), IMG put together the following graph. Not surprisingly, it positions their new offering rather favorably as compared to a number of other solutions – both from them and from competitors (unnamed).
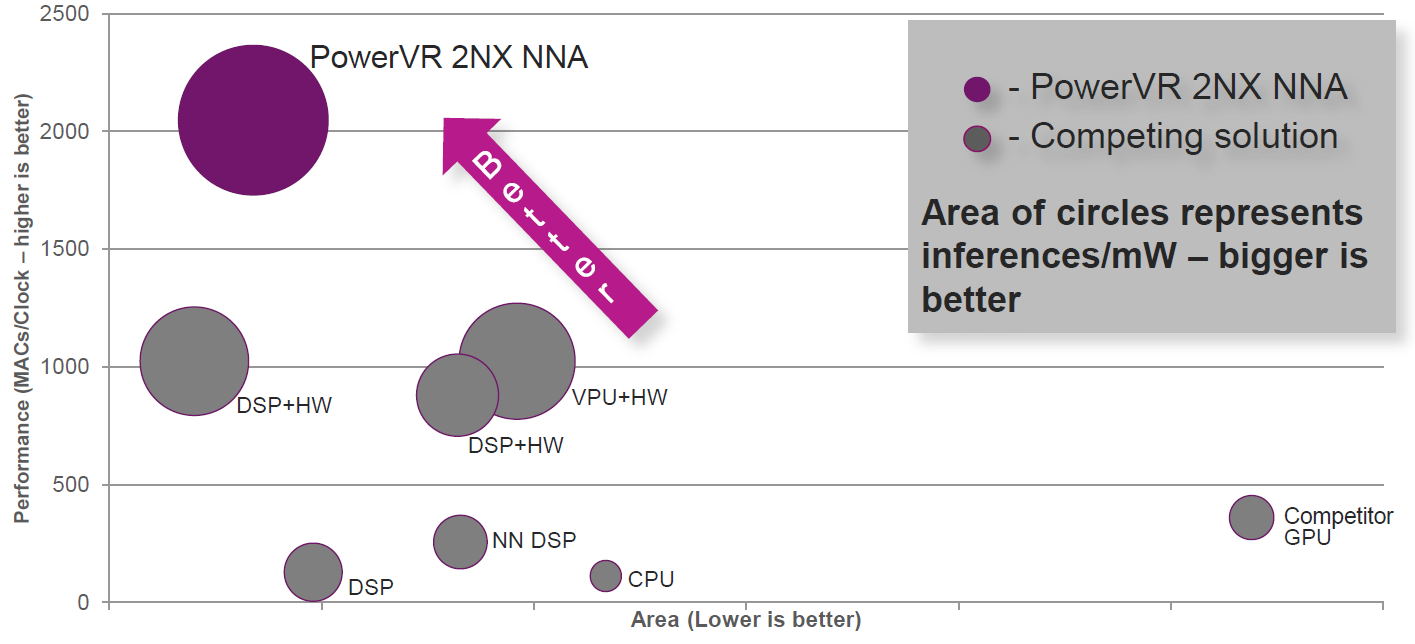
(Image courtesy Imagination Technologies)
Adaptability and Flow
The way they manage to get applications to work on so many different platforms is through a generic DNN (Deep Neural Net) API. Applications are written to the API; that API is then bound to the underlying hardware through a driver. This layer of abstraction makes for better porting – or even experimentation to see what the best platform solution might be.
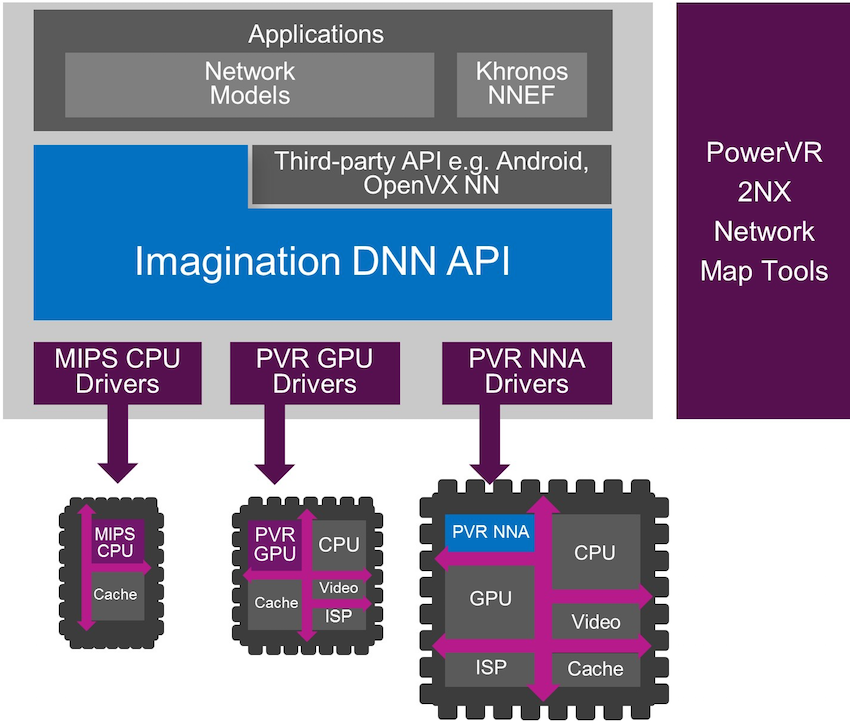
(Image courtesy Imagination Technologies)
As to the design flow itself, it’s illustrated in the figure below. There are three basic steps: training, optimization, and implementation. The first steps are all about figuring out the network, without worrying about where it’s going to run. It’s not about speed; it’s about accuracy.
The middle section would be where any retraining might happen. The iterative nature isn’t really shown; there’s a loop there somewhere between the first and second steps.
Only in the final step do you start figuring out what platform performance you’ll need to keep up with the flow of whatever input data you’re processing. If you’re constrained as to which platform you can use (or afford to use), then, if you can’t manage it with the network you’ve designed, you may have to go back and re-optimize to reduce the complexity of the network.
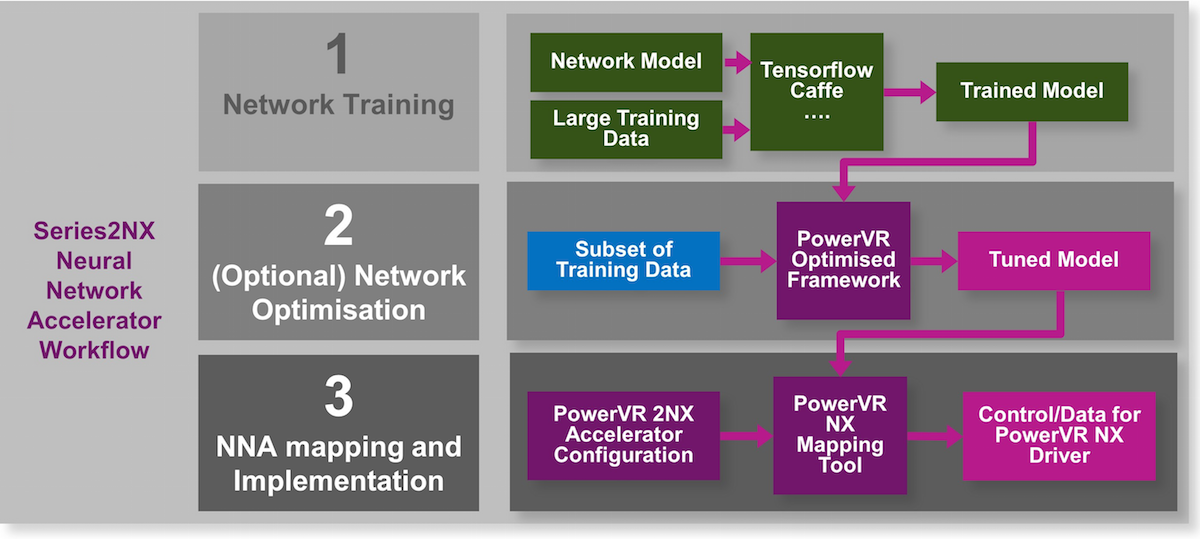
(Image courtesy Imagination Technologies)
So that’s the condensed version of this latest DNN accelerator. Lots more details in the reference below.
More info:
Imagination Technologies PowerVR 2NX neural network accelerator



What do you think of Imagination Technologies’ approach to neural net acceleration?
Imagination have had many years to get good at something, seems unlikely they can do any better in this particular sector given the high level of competition.
From my perspective NN acceleration looks a lot like circuit simulation, and people have been working on speeding that up for years. I’m expecting technology to bleed one way or the other, but I suspect it will probably be from the new AI guys into EDA, with chips from folk like Mythic AI being reused for high-speed real-number modeling. That will be problematic for EDA companies, since the volume pricing for AI chips make the emulator market a target for disruption.