


Cadence is a pivotal leader in electronic design, building upon more than 30 years of computational software expertise. The company applies its underlying Intelligent System Design strategy to deliver software, hardware and IP that turn design concepts into reality.
Cadence Blog – Latest Posts

喜讯 | Cadence Palladium Z3 与 Protium X3 系统荣膺 2025 全球电子成就奖
在全球电子设计加速演进的浪潮中,Cadence 楷登电子再度以卓越的创新实力赢得行业瞩目。 由全球电子技术领域知名媒体集团 ASPENCORE 举办的全球电子成就奖颁奖典礼于 2025 年 11 月 25 日 在深圳盛大举行。 Cadenc...

Cadence Tensilica Vision DSP 助力爱芯元智,提升人形机器人与物联网应用性能
近日,楷登电子Cadence与边缘 SoC 领军企业爱芯元智共同宣布,爱芯元智在其最新的 AX8850N 平台上集成了 Cadence ® Tensilica ® Vision 230 DSP,以共同推动人形机器人、智慧城市与边缘应用的发展。此举标志着双�...

快讯 | Cadence Conformal AI Studio 升级 AI 驱动的 SoC 逻辑验证流程
Cadence 以 Conformal AI Studio 结合强化学习与分布式架构,全面升级 LEC、低功耗验证和 ECO,在 AI 设计时代开创新范式。 随着人工智能(AI)浪潮席卷半导体设计,验证技术正处于关键转折点。由 ASPENCORE 出版集团�...

Unifying Electronic and Photonic Circuit Simulation
The Need For Photonics The proliferation of artificial intelligence, the rollout of faster mobile networks, and the corresponding demand for vast data storage all require unprecedented processing power and data transfer capacity. To meet these bandwidth requirements, designer...

Accelerating the AI Factory: Switch and Cadence Redefine High-Density Design
"We are redefining what is possible for next-gen AI factories with our patent-pending EVO Chamber solution—delivering up to 2MW per cabinet through advanced hybrid cooling in a modular, future-proof design. Using the Cadence Reality Digital Twin Platform, built with NV...

The Engineering Workforce Multiplier: How Agentic AI Is Shaping Silicon Design
A virtual engineering organization coordinates reasoning and intent across design and verification, while accelerated, AI‑driven EDA tools—and working with NVIDIA—translate that intelligence into trusted, scalable silicon outcomes. Engineering demand is accelerating fas...

Digital Twins Enable the Next Era of AI Infrastructure
Artificial intelligence (AI) is reshaping the data center. As AI workloads scale in size and complexity, traditional hyperscale designs are giving way to AI factories—purpose-built environments engineered to manufacture intelligence efficiently, reliably, and at scale. In a...

The Nexus of Passion and Profession
Whether you're choosing a college major or shifting direction in an established career, a compass might be found in the Purpose Venn Diagram. At the intersection of these questions lies Purpose. On a recent high school STEM Day at the Cadence Austin office, engineers dis...
Chalk Talks Featuring Cadence

Faster, More Predictable Path to Multi-Chiplet Design Closure
The challenges for 3D IC design are greater than standard chip design - but they are not insurmountable. In this episode of Chalk Talk, Amelia Dalton chats with Vinay Patwardhan from Cadence Design Systems about the variety of challenges faced by 3D IC designers today and how Cadence’s integrated, high-capacity Integrity 3D IC Platform, with its 3D design planning and implementation cockpit, flow manager and co-design capabilities will not only help you with your next 3D IC design.

Enabling Digital Transformation in Electronic Design with Cadence Cloud
With increasing design sizes, complexity of advanced nodes, and faster time to market requirements - design teams are looking for scalability, simplicity, flexibility and agility. In today’s Chalk Talk, Amelia Dalton chats with Mahesh Turaga about the details of Cadence’s end to end cloud portfolio, how you can extend your on-prem environment with the push of a button with Cadence’s new hybrid cloud and Cadence’s Cloud solutions you can help you from design creation to systems design and more.

Machine-Learning Optimized Chip Design -- Cadence Design Systems
New applications and technology are driving demand for even more compute and functionality in the devices we use every day. System on chip (SoC) designs are quickly migrating to new process nodes, and rapidly growing in size and complexity. In this episode of Chalk Talk, Amelia Dalton chats with Rod Metcalfe about how machine learning combined with distributed computing offers new capabilities to automate and scale RTL to GDS chip implementation flows, enabling design teams to support more, and increasingly complex, SoC projects.
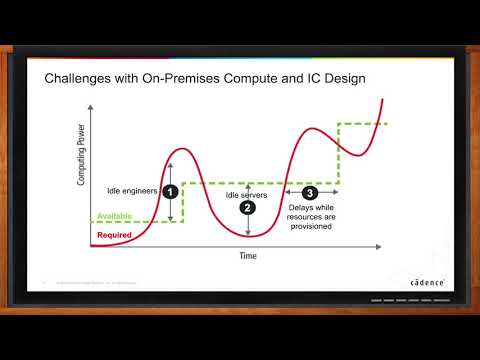
Cloud Computing for Electronic Design (Are We There Yet?)
When your project is at crunch time, a shortage of server capacity can bring your schedule to a crawl. But, the rest of the year, having a bunch of extra servers sitting around idle can be extremely expensive. Cloud-based EDA lets you have exactly the compute resources you need, when you need them. In this episode of Chalk Talk, Amelia Dalton chats with Craig Johnson of Cadence Design Systems about Cadence’s cloud-based EDA solutions.
Featured Content from Cadence
featured video

Cadence Chiplets Solutions | Helping you realize your chiplet ambitions
In this webinar, David Glasco, VP of Compute Solutions at Cadence, discusses how Cadence enables customers to transition from traditional monolithic SoC architectures to modular, scalable chiplet-based solutions, essential for meeting the growing demands of physical AI applications and high-performance computing.
featured video

How Switch Provides Unparalleled Exascale Data Center Solutions with Cadence and NVIDIA
Learn how Switch, a leading designer, builder, and operator of U.S. exascale data centers, is taking their data center’s cooling capabilities even further. In the past 20 years, Switch has built some of the densest air-cooled data center environments. With AI taking off in the last couple of years, see how they were able to deploy many of the first NVIDIA H100 clusters inside using Cadence’s Reality Digital Twin Platform for pre-modeling, design, and validation.facilities.
featured video

How NV5, NVIDIA, and Cadence Collaboration Optimizes Data Center Efficiency, Performance, and Reliability
Deploying data centers with AI high-density workloads and ensuring they are capable for anticipated power trends requires insight. Creating a digital twin using the Cadence Reality Digital Twin Platform helped plan the deployment of current workloads and future-proof the investment. Learn about the collaboration between NV5, NVIDIA, and Cadence to optimize data center efficiency, performance, and reliability.
featured video

Larsen & Toubro Builds Data Centers with Effective Cooling Using Cadence Reality DC Design
Larsen & Toubro built the world’s largest FIFA stadium in Qatar, the world’s tallest statue, and one of the world’s most sophisticated cricket stadiums. Their latest business venture? Designing data centers. Since IT equipment in data centers generates a lot of heat, it’s important to have an efficient and effective cooling system. Learn why, Larsen & Toubro use Cadence Reality DC Design Software for simulation and analysis of the cooling system.