

Captain’s log, stardate 22276.3: I’m happy and sad, baffled and bewildered, and dazed and confused. The day is yet young, so everything is pretty much par for the course. One reason I’m happy is that the SyFy channel recently started a new series called Reginald the Vampire. Although this may not be the best vampire show ever, it’s an interesting take on things, and I’m looking forward to seeing how it pans out.
One reason I’m sad is that I just discovered the 2022 incarnation of the Salem’s Lot movie, which was originally scheduled to be released on 9 September 2022, but which was later bumped out to 21 April 2023, now has no defined release date whatsoever. The 1975 book by Stephen King was awesome. The 1979 TV miniseries (which is now available as a film) was awful, with David Soul plumbing previously unplumbed depths of bad acting. The 2004 TV miniseries (which is also now available as a film) starring Rob Lowe wasn’t much better. Having said this, as bad as both films are, they are better than nothing at all. Earlier this year, my wife (Gina the Gorgeous) and I binge-watched both of them, just to warm us up for the 2022 release, which promised so much before it was so cruelly snatched from under our noses.
I’m also sad that Apple TV+ made such a “pig’s ear” out of their TV production of Isaac Asimov’s Foundation. I was so looking forward to this (see Apple TV+ Foundation: First Impressions), which led to my being baffled and bewildered when the writers completely lost the plot. Did they actually read the original book? Why didn’t they ask me to be their technical advisor? On the happy side, Dune 2021 (which covered the first half of the book) was a tribute to Frank Herbert’s masterpiece (see Dune 2021: First Impressions) and I cannot wait to see the sequel, which will cover the second half of the book and which is currently scheduled to be released in November 2023.
My state of being dazed and confused can be largely attributed to my recently being introduced to some amazing kids who have left my head spinning like a top. You already know about 11-year-old Zeke who is building a radio with a 10-foot helical antenna to allow him to talk with the astronauts and cosmonauts on the International Space Station (ISS) (see O-M-Gosh, I’ve Been Zeked! Part 1 and Part 2). Well, sometime after posting those columns, I was contacted by a distraught mother whose 6-year-old son called Alfie was asking for a Nanobot Kit for Christmas (see What’s It All About, Alfie?). Alfie informed his mom that all he would have to do was add the nanobots to a mixture of chemicals in a barrel, stir them with a wooden spoon, and leave them to build a supercomputer. When she protested, he showed her the relevant passage in my book Bebop to the Boolean Boogie: An Unconventional Guide to Electronics. To be fair, Alfie had missed the part where I said this was something we might expect to see described in the 2050 edition of the book. The thing is that, although I’d always intended Bebop to be accessible to a wide audience, I never expected to find it on a first grader’s “must read” list.
Another reason my head is spinning like a top is that I’ve just been chatting with Dave Tokic, who is VP of Marketing and Business Development at Algolux. Every time Dave and I talk, I end up with my poor old noggin jam-packed with more nuggets of knowledge and tidbits of trivia than I know what to do with.
As you may recall from previous columns, a machine vision system includes a lens assembly, a sensor, and image signal processing (ISP)—where the ISP is implemented using hardware and/or software—all of which feeds an artificial neural network (ANN) that performs artificial intelligence (AI) and machine learning (ML) tasks to understand the scene and to detect and identify objects in that scene. The ISP portion of the pipeline performs tasks like debayering, color correction, denoising, sharpening, and so forth (debayering, a.k.a. demosaicing, is a digital process used to reconstruct a full color image from the incomplete color samples output from an image sensor overlaid with a color filter array). The problem is that these pipelines are traditionally created and tuned by humans for human viewing, which may not, in fact, be optimal when it comes to machine vision applications.
As I discussed in my column, When Genetic Algorithms Meet Artificial Intelligence, Atlas is an evolutionary algorithm-driven tool that can be used to optimize the ISP to get better images for use with the customer’s own perception stack. At that time, the guys and gals from Algolux described Atlas as “The industry’s first set of machine-learning tools and workflows that can automatically optimize camera architectures intended for computer vision applications.”
A brief introduction from the Atlas landing page summarizes things as follows: “Atlas automates manual camera ISP tuning. The Atlas Camera Optimization Suite is the industry’s first set of machine learning tools and workflows that automatically optimizes camera architectures for optimal image quality or for computer vision. Through a secure cloud-enabled interface, Atlas significantly improves computer vision results in days vs. traditional approaches that deliver suboptimal results even after many months of manual ISP tuning.”
But wait, there’s more, because as I discussed in my column, Eos Embedded Perception Software Sees All, Eos takes things to the next level by combining image processing with scene understanding and object detection and recognition. Basically, Eos covers the entire machine vision pipeline. A brief introduction from the Eos landing page summarizes things as follows: “Eos is an award-winning embedded perception solution that massively improves vision system robustness in all conditions. Our efficient end-to-end deep learning architecture can be quickly personalized to any camera lens/sensor configuration or for multi-sensor fusion. Combined with stereo or depth-sensing cameras, Eos offers an alternative to Lidar at a fraction of the cost.”
The reason I’m re-waffling on about all of this here is that the chaps and chapesses at Algolux have taken the existing Eos and made it even better by augmenting it with robust depth perception. I don’t know about you, but I think a diagram might make things clearer.
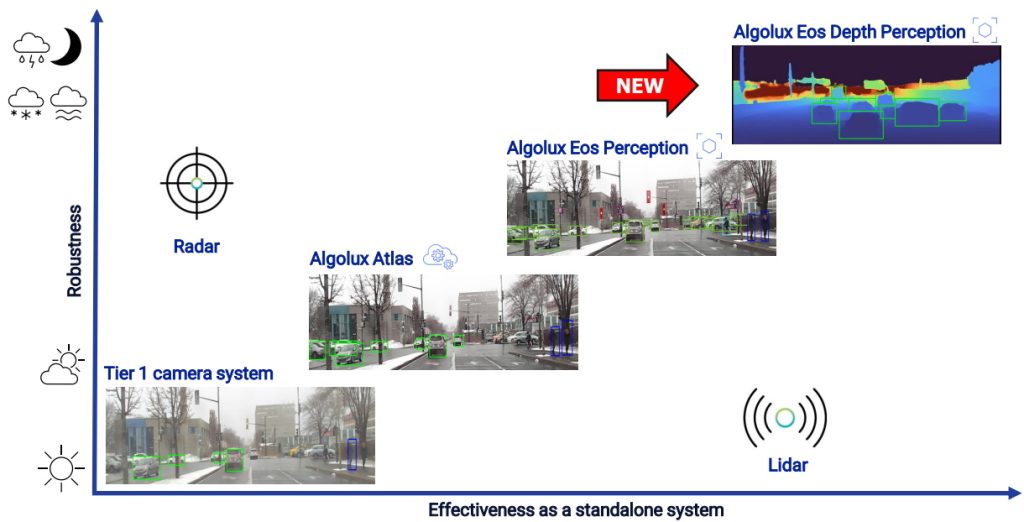
The path to next-level safety for ADAS/AV (Source: Algolux)
In this case, the vertical axis reflects robustness in terms of a sensor’s ability to operate under different environmental conditions, while the horizontal axis reflects effectiveness as a standalone system. Using these criteria, radar is positioned as being reasonably robust, but you wouldn’t want to rely on it as a standalone sensor. By comparison, lidar is reasonably effective as a standalone system, but not as robust as you might hope for.
A current Tier 1 automotive camera-based machine vision system is shown in the lower-left hand corner. On the one hand, its object detection and recognition capabilities are impressive; on the other hand, it lacks in both robustness and effectiveness. Both metrics are improved when Atlas is used to tune the ISP, and things are further improved when Eos is used to tune both the ISP and the perception stack.
At this point, it’s important to note two things (while I remember them). First, Algolux isn’t looking to replace radar or lidar, but rather to augment these technologies. Second, Algolux doesn’t sell systems; instead, they sell the Atlas and Eos products and related services to help the designers of machine vision systems create awesomely better systems.
Where things really start to get exciting is the recent announcement of robust depth perception, as indicated by the “NEW” arrow in the image above and as reflected in the image below.
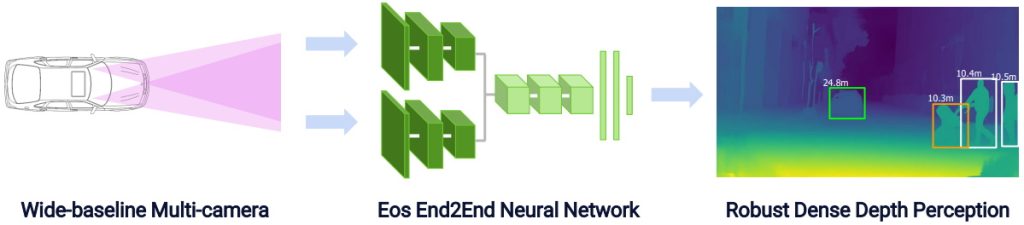
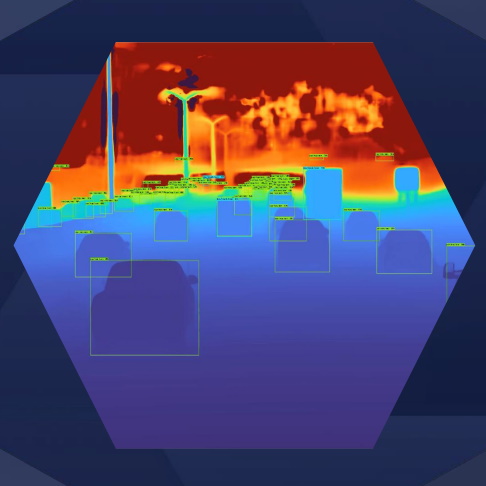
Eos robust depth perception software (Source: Algolux)
There’s more to this diagram than meets the eye (no pun intended). First, there are multiple ways in which humans and machines can perceive depth. The one we usually think of is to use binocular sensors: two eyes in the case of people and two cameras in the case of machines. Using the differences between the images detected by the two sensors allows us to extrapolate all sorts of information, like the depth (distance) of the various elements and—when comparing multiple frames over time–whether things are approaching (getting bigger) or receding (getting smaller). Of course, humans can also extrapolate depth information from a single image and/or using only one eye based on their understanding of the scene and their knowledge of things like the typical sizes of things like cars, trucks, trees, people, etc.
Well, the latest generation of Eos employs all of these techniques. One way to improve depth perception using two sensors is to increase their baseline (the horizontal distance between them). The reason existing systems typically have a baseline of only 20 to 30 cm is that the cameras vibrate in a moving vehicle, and differences in their respective motions increase the farther they are apart. Much like the automatic camera stabilization in your smartphone, Eos employs sophisticated real-time adaptive auto-calibration, thereby allowing for much larger baselines (2 meters in the case of one truck implementation they are currently working on).
Another really important point to understand from the above image is that Eos does not employ an external ISP. If the camera includes an SoC that performs ISP, for example, then Eos bypasses that ISP and accepts only the raw images from the camera. The reason for this is that Eos performs all of the ISP functions in the front-end layers of its ANN, and it performs all of the scene understanding and object detection and recognition functions in the back-end layers of its ANN. It’s the ability to train all of these functions and neural layers together that allows Eos to deliver such outstanding results compared to traditional image processing pipelines.
The following image shows an OEM example of Eos robust depth and object detection in daylight conditions (you can also watch this video on YouTube).
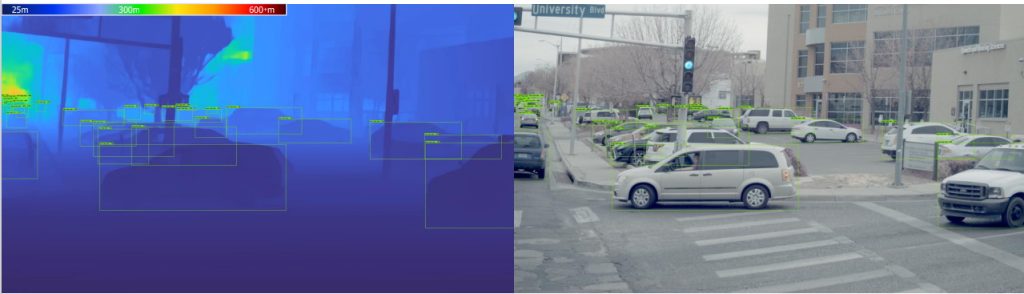
Eos-enabled system in daylight conditions: Detection based on camera imagery (right) and detection combined with a depth disparity map (left)
(Source: Algolux)
Similarly, the following image shows an OEM example of Eos robust depth and object detection in low-light conditions (you can also watch this video on YouTube).

Eos-enabled system in low-light conditions: Detection based on camera imagery (right) and detection combined with a depth disparity map (left)
(Source: Algolux)
Pretty impressive, eh? OK, let’s wrap up with a quick summary. Radar and lidar systems are great, but each technology has limitations that hamper safe operation in every condition. Lidar has limited effective range due to decreasing point density the further away an object is, resulting in poor object detection capabilities and low robustness in harsh weather conditions such as fog or rain due to backscatter of the laser. It’s also costly, with current systems costing hundreds to thousands of dollars per sensor.
Radar has good range and robustness but poor resolution, which limits its ability to detect and classify objects. Last, but not least, today’s stereo camera approaches can do a good job of object detection but are hard to keep calibrated and have low robustness. Meanwhile, mono camera systems have many issues resulting in poor depth estimation.
Eos robust depth perception software addresses these limitations by robustly providing dense depth detection combined with accurate perception capabilities to determine distance and elevation even out to long distances (e.g., 1 kilometer). Eos also provides the ability to identify objects, pedestrians, or bicyclists, and even lost cargo or other hazardous road debris to further improve driving safety. These modular capabilities provide rich 3D scene reconstruction and provide a highly capable and cost-effective alternative to lidar, radar, and today’s existing stereo camera approaches.
I don’t know about you, but I for one am jolly enthused. The sort of machine vision technologies we are seeing today (again, no pun intended) would have been unimaginable just a few short years ago. I can’t wait to see how all of this stuff evolves in the years to come. What say you?


