


I liked it so much, I bought the company. – Victor Kiam
On July 17, Xilinx announced that it had acquired DeePhi Technology Co., Ltd. DeePhi is a privately held, machine-learning startup company based in Beijing that has developed deep-compression and pruning algorithms and system-level optimization for neural networks aimed at many types of AI work. Xilinx announced an investment in DeePhi a little over a year ago, and the company apparently liked DeePhi so much, they bought the company. (Cue the old TV ad with investor/entrepreneur Victor Kiam describing his acquisition of Remington Products, the electric shaver company, because he liked the Remington Micro Screen Rechargeable shaver so much.)
According to Xilinx’s recent press release announcing the acquisition:
“…the two companies have worked closely together since DeePhi Tech’s inception in 2016. DeePhi Tech’s neural network pruning technology has been optimized to run on Xilinx FPGAs.”
Way back in 2016 at the Hot Chips show in held in Cupertino, California, DeePhi rolled out a convolutional neural network (CNN) acceleration processor named Aristotle. It was based on a Xilinx Zynq-7000 All Programmable SoC. That’s a 28nm, monolithic device that combines a couple of 32-bit Arm Cortex-A9 processors and a chunk of Xilinx’s FPGA fabric.
A year later, Xilinx posted a “Powered by Xilinx” video showing Zerotech’s pocket-sized Dobby AI drone using DeePhi’s deep-learning algorithms to execute ML (machine learning) tasks including pedestrian detection, tracking, and gesture recognition. The drone runs DeePhi’s algorithms on its Xilinx Zynq Z-7020 SoC, which executes 230 GOPS while consuming only 3W.
That same year, at FPGA 2017 held in Monterey, California, DeePhi published a paper titled “ESE: Efficient Speech Recognition Engine with Sparse LSTM on FPGA” that described a speech-recognition algorithm, later dubbed “Descartes,” using LSTM (Long Short-Term Memory) models with load-balance-aware pruning implemented on a 20nm Xilinx Kintex UltraScale+ KU060 FPGA. DeePhi’s implementations ran at 200MHz and consumed 41W while delivering 43x more performance than an Intel Core i7 CPU and 3x more performance than an Nvidia Titan X GPU. Energy efficiency for the DeePhi design in terms of performance-per-watt was an order of magnitude better than the GPU and 40x better than the CPU.
You can now hire DeePhi’s Descartes speech-recognition engine for about $1.65 an hour. No, Descartes is not hanging out in the local Home Depot parking lot. Instead, you’ll find DeePhi’s Descartes in the AWS marketplace, accelerated by the FPGA-accelerated AWS EC2 F1 instance—which is based on 16nm Xilinx Virtex UltraScale+ FPGAs.
So you see, DeePhi’s been hanging with Xilinx for at least three device generations, and DeePhi’s ML expertise hits Xilinx right in its new sweet spot.
In March, Xilinx’s CEO Victor Peng announced a three-pronged go-to-market strategy (see Kevin Morris’ March 20 article “Xilinx Previews Next Generation”) that included:
- Data Center First
- Accelerate Growth in Core Markets
- Drive Adaptive Computing with ACAP (Adaptive Compute Acceleration Platforms, code name: Project Everest)
The DeePhi acquisition snags at least the first and third prongs of Peng’s strategy. Frankly, this is a more integrated approach to providing solutions—one that’s far superior to Xilinx’s old strategy of letting 3rd parties supply software for critical, strategic markets. Now, if finger pointing is needed when something doesn’t work—and that happens more often than not—there’s only one vendor to point at. That’s a much better situation for customer and vendor alike.
The DeePhi acquisition’s connection to Peng’s data-center strategy prong should be apparent from the inexpensive availability of DeePhi’s Descartes speech-recognition engine for the AWS EC2 F1 instance in the AWS Marketplace.
In his article about Peng’s three-pronged strategy for Xilinx, Kevin Morris wrote:
“Clearly what Xilinx needs, and what this new vision seems meant to convey, is a new weapon to accelerate their participation in the current trend of explosive data-center accelerator market growth.”
Cue DeePhi, even though Kevin Morris was clearly thinking about something other than DeePhi when he wrote that sentence—because he said so. What was Morris thinking about? Prong three: ACAP.
What’s ACAP? It’s the 7nm chip that Xilinx has been working on that has everything the Zynq SoC and Zynq UltraScale+ MPSoC have including:
- Application processor(s)
- Real-time processor(s)
- Programmable logic (the stuff of FPGAs)
- On-chip memory (lots of it, considering that some of it’s made from HBM)
- RF ADCs and DACs
- High-speed 33Gbps and 58Gbps PAM4 programmable SerDes ports
All of these major on-chip elements are interconnected with a new-to-ACAP NOC (network on chip).
Figure 1 shows a block diagram of a Xilinx ACAP device.
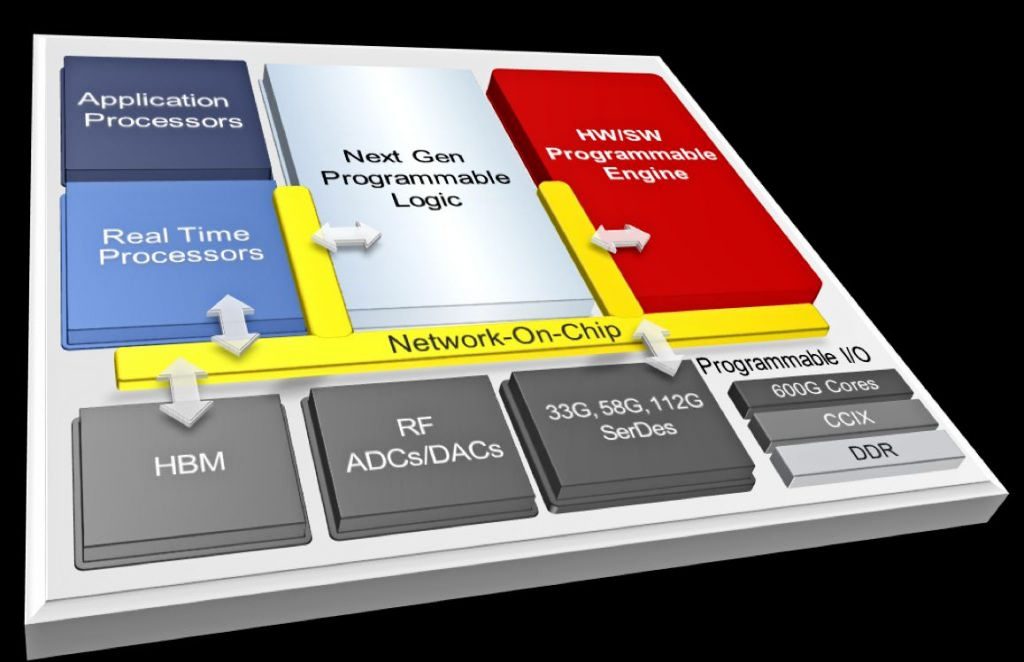
Figure 1: Xilinx’s 7nm ACAP device includes all of the previous elements of the previous-generation 28nm Zynq SoCs and 16nm Zynq UltraScale+ MPSoCs, plus a couple of new ones. (Image source: Xilinx)
Note: I really don’t expect to see every one of these blocks appear on every single ACAP variant. For example, there are plenty of applications that don’t need RF ADCs and DACs or high-performance HBM DRAM, and these features are expensive. However, there’s one more, as-of-yet-unannounced block in Figure 1 called the “Hardware/Software Programmable Engine.” As Morris wrote in his March 20 article:
“Well, it all comes down to this. We’ve been through the entire ACAP block diagram, and the only thing that isn’t just a natural evolution of Zynq UltraScale+ is this new block. What is it? Peng says they are not ready to share details yet.”
It’s clear that DeePhi’s machine-learning algorithms should run better on the ACAP device, just as they’ve run better with each new Xilinx device generation starting with the 28nm node. When Xilinx initially revealed the ACAP concept on March 19, the company’s press release said:
“An ACAP is ideally suited to accelerate a broad set of applications in the emerging era of big data and artificial intelligence. These include: video transcoding, database, data compression, search, AI inference, genomics, machine vision, computational storage, and network acceleration.”
This statement ticks at least three of DeePhi’s boxes: data compression, AI inference, and machine vision.
Just last month, Xilinx announced that it and Daimler AG were collaborating on an AI application for automotive use. Will DeePhi’s (now Xilinx’s) technology find its way into a future Mercedes automobile? We don’t really know, because the press release doesn’t say, but the press release does say this:
“Mercedes-Benz will productize Xilinx’s AI processor technology, enabling the most efficient execution of their neural networks.”
Well, that’s certainly a tantalizing coincidence.
Meanwhile, the headline of Asia Times’ article about Xilinx’s acquisition of DeePhi calls Xilinx an “AI giant.”
Mission accomplished.



Wow!