


We’ve looked at several AI IP offerings over the last year or so, from Cadence (more than once), Synopsys, and Imagination Technologies. All of them, in one way or another, rely on computing units like DSPs or GPUs to handle the many computations it takes to make an inference.
As all of this IP evolves, there’s a key trend: move neural-net inference out of the cloud and into the “edge” devices that currently rely on the cloud. Latency and privacy can be improved, and devices that have poor cloud connections can be more self-sufficient.
But today, we’re going to talk about two different neural-net applications: vision and speech recognition. We have IP for both from Cadence: their announcement a couple of months ago of the Tensilica DNA 100 accelerator and their much more recent announcement of their Tensilica HiFi 5 audio platform.
Looking at them illustrates some of the drivers of the evolution that we’re seeing – and the two applications are not the same in terms of what they require, so the IP design decisions and tradeoffs have been different.
Generic Processing
The first stage of neural processing has taken place amidst seas of processing elements – typically DSPs or GPUs. At this early stage of things, algorithms and applications and performance and power are all in the experimental phase. It’s about getting it to work, not necessarily getting it to work optimally.
Vision left this stage of evolution a while ago, but not so much audio. In a conversation with Cadence about their HiFi 5 IP, it was clear that their prior HiFi 4 edition was handling neural nets, but doing so using the same DSPs that were being used for everything else. That has changed with HiFi 5.
Tighter DSPs
The next evolutionary stage comes when you have a better handle on how much processing is required – in other words, how many DSPs you’re likely to need access to. Here we take note of two key facts about neural-net processing:
- You’re going to be working with smaller data units. The big data loads consist of the weights or coefficients for the nodes of the network and for what they call the activation – the input data (a visual image or frame or an audio sound-stream). These tend to involve integers of at most 16 bits – sometimes down to 4 bits or smaller. None of the 32-bit behemoths that float around for other DSP applications.
- You’re dealing with integer multiplication. A general-purpose DSP will have lots of multiply-accumulation units (MACs), but, because it’s general purpose, those units can be configured into a number of different modes. You don’t need most of those modes for neural-net operations. You can use a simpler integer unit.
So one of the big differences between Cadence’s HiFi 4 and HiFi 5 is that the latest one has a series of simplified DSPs optimized for neural-net use. You no longer need general-purpose DSPs.
Data in the Way
The next evolutionary step involves the surprising fact that performance may not be limited by all of those MAC calculations. The bottleneck may be something far more pedestrian: moving data around.
As you re-use a set of MACs for different parts of the calculation, you end up moving matrices of weights in and out of use. And, of course, you’re moving the input data around as you receive it and deliver it to different parts of the engine. Moving all of those matrices takes time.
So the first thing that you can do is to optimize the architecture in a way that reduces the required number of data moves, getting that movement out of the way of actual work done by the MACs. This is a typical change that’s been made for accelerators, and you see that in the vision stuff. Notably, that hasn’t happened yet with HiFi 5 for reasons we’ll come back to in a moment.
The other key characteristic of these matrices is that they tend to be sparse. That means that most of their entries are 0, with a few having useful non-zero data elements. This gives rise to a couple of opportunities (one of which we’ll defer for a moment).
When you have big chunks of data that are zero, what technique beckons for reducing the amount of data? Compression, of course. So the weights and inputs can be compressed before being stored, making it much faster to move them around when needed. When pressed into service, the matrices are decompressed first. Key here, of course, is the requirement that the time you save moving data doesn’t get eaten back up due to compression and decompression time. Which, given that this is a touted feature in both the DNA 100 and the HiFi 5, appears to be the case.
Ignore the Zeros
Finally, those sparse matrices, once decompressed, can result in lots of calculations on those zero-valued elements. Cadence created an optimized neural-net engine in their DNA 100 that works only on non-zero elements. They skip the zero-valued ones, gaining yet more performance.
This and the optimized architecture are steps that the HiFi 5 has not taken yet, both for the reason that we need to dig into next.
Soft or Hard?
We now have a completely separate set of decisions to make, depending on how mature our algorithms are and how much performance we need to squeeze out of a device: do we execute the algorithm in software or in hardware (or in some combination thereof)?
There’s been a consistent trajectory in the industry: do things in software as much as possible, since there’s pretty much nothing more flexible than software. If you are on a steep learning curve and have to make frequent changes, then software is your safest bet. As long as you don’t overstep your memory footprint, you can make all the changes you want without affecting the hardware design at all.
But, at some point, many applications start to cry out for hardware implementation. It might be for cost reasons or speed reasons or power reasons, but any of those reasons can drive the move to harden some, if not all, of the algorithm.
Vision and audio processing have very different performance requirements. Even analysis of a still picture involves a starting data set of megapixels (meaning many megabits). Yes, as you move through the neural-net pipeline, that set of bits shrinks due to convolution and pooling, but it starts out big. If you’re processing video, then you have to process the frames at the frame rate in order to keep up with real-time performance. That’s a lot of data to push around.
Audio, meanwhile, has a couple of characteristic differences as compared to visual processing. With a still image, you have all the pixels at once. Convolution is used because it resembles how we think our brains process vision. But audio works differently. First of all, instead of a pile of bits that are concurrently valid, you have a time sequence of bits from the audio stream. So you’re not just processing data that was captured at the same time; you’re capturing a data set acquired over time. This is where recurrent neural nets (RNNs) tend to be used rather than convolutional neural nets (CNNs).
Audio also processes relatively low-frequency vibrations – those in the audible range. This limits us to a couple tens of kilohertz – resulting in processing of a few megaMACs/cycle – rather than hundreds of megaMACs/cycle or even teraMACs/cycle for video. In other words, all in all, audio processing requires far less performance.
So, given the tradeoff between performance and the flexibility of software, audio can still stay with an all-software implementation. This is why Cadence went as far as to use optimized DSPs for audio, but they didn’t use an optimized architecture or a hardened circuit. They can still get the performance they need without giving up any of the software flexibility.
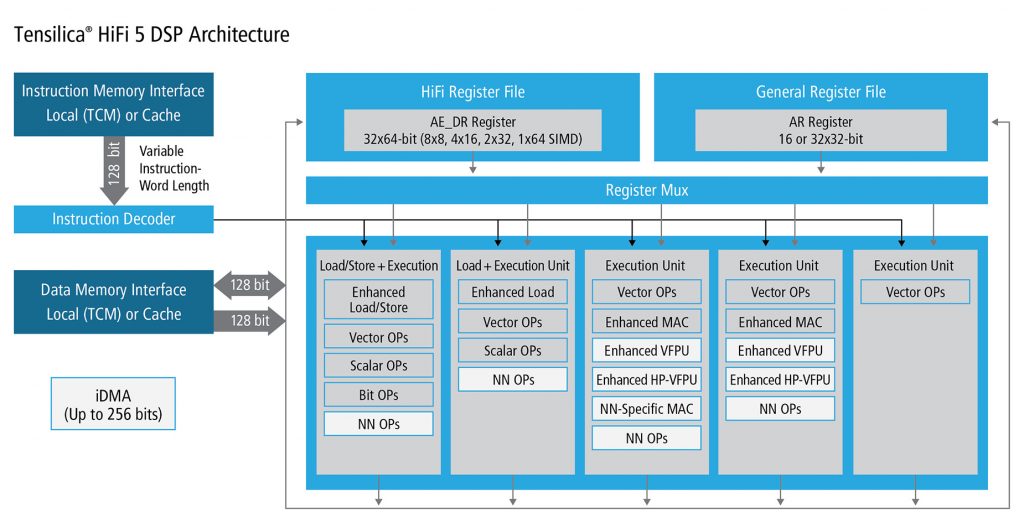
(Click to enlarge. Image courtesy Cadence)
The DNA 100, by comparison, went farther down that hardening path, with a dedicated architecture and the non-zero-value-only MAC.
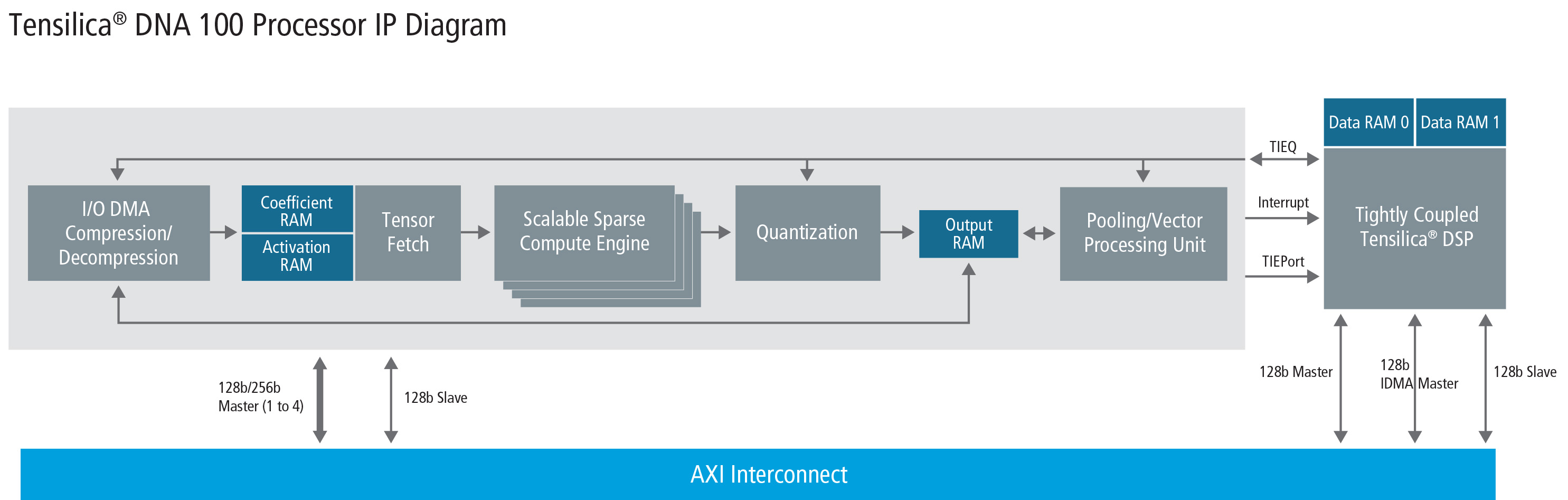
(Click to enlarge. Image courtesy Cadence)
So there you have it. The xNN evolution pipeline – from all generic DSPs to optimized hardware – and how vision and audio processing have traveled down that path, giving proof that not all neural nets are the same. Are we at the end of that pipeline for vision? Not likely. But we won’t know what the next stages are until we get there.
More info:



What do you think about how AI implementations are evolving, and about Cadence’s vision and audio neural-net solutions?
Hi, Bryon. I am a system and hardware designer new to AI. You wrote:
“You’re going to be working with smaller data units. The big data loads consist of the weights or coefficients for the nodes of the network and for what they call the activation – the input data (a visual image or frame or an audio sound-stream). These tend to involve integers of at most 16 bits – sometimes down to 4 bits or smaller. None of the 32-bit behemoths that float around for other DSP applications.
You’re dealing with integer multiplication. A general-purpose DSP will have lots of multiply-accumulation units (MACs), but, because it’s general purpose, those units can be configured into a number of different modes. You don’t need most of those modes for neural-net operations. You can use a simpler integer unit.”
Using embedded block memory for these MACs is a natural fit for FPGAs because there are so many blocks available.
Typical FPGA designs use LUTs grouped together to form 4, 8, 16 bit integers and LUTs for combo logic. LUTs are one bit wide memories, pure and simple that can do any Boolean combination of up to 6 Boolean variables.
A MAC can use 1 or 2 inputs of control to evaluate 2 two-bit operands–4 inputs. So 2 LUTs can do a 4 bit MAC, 8 by 256 can decode an 8 bit input to 8 outputs, and so on. There are hundreds and even thousands of memory blocks available on FPGAs and designs can get both performance and flexibility in this way.
I have not tried matrix multiplication, but intuitively feel that dual 2 port memories can deliver the matrix elements for each operation in one clock cycle.
This approach could blend in very well with the evolution.