


Vision in living beings is a pretty incredible thing. The eyeball hardware and the brain software seem effortlessly to do what we struggle to do in inorganic hardware and software. But we’re making progress. And, today, we take on two vision topics – but, unlike in the past, they’re not closely related. They’re about two very different aspects of vision. And we’ll take them in the order of announcement.
Ps and Qs
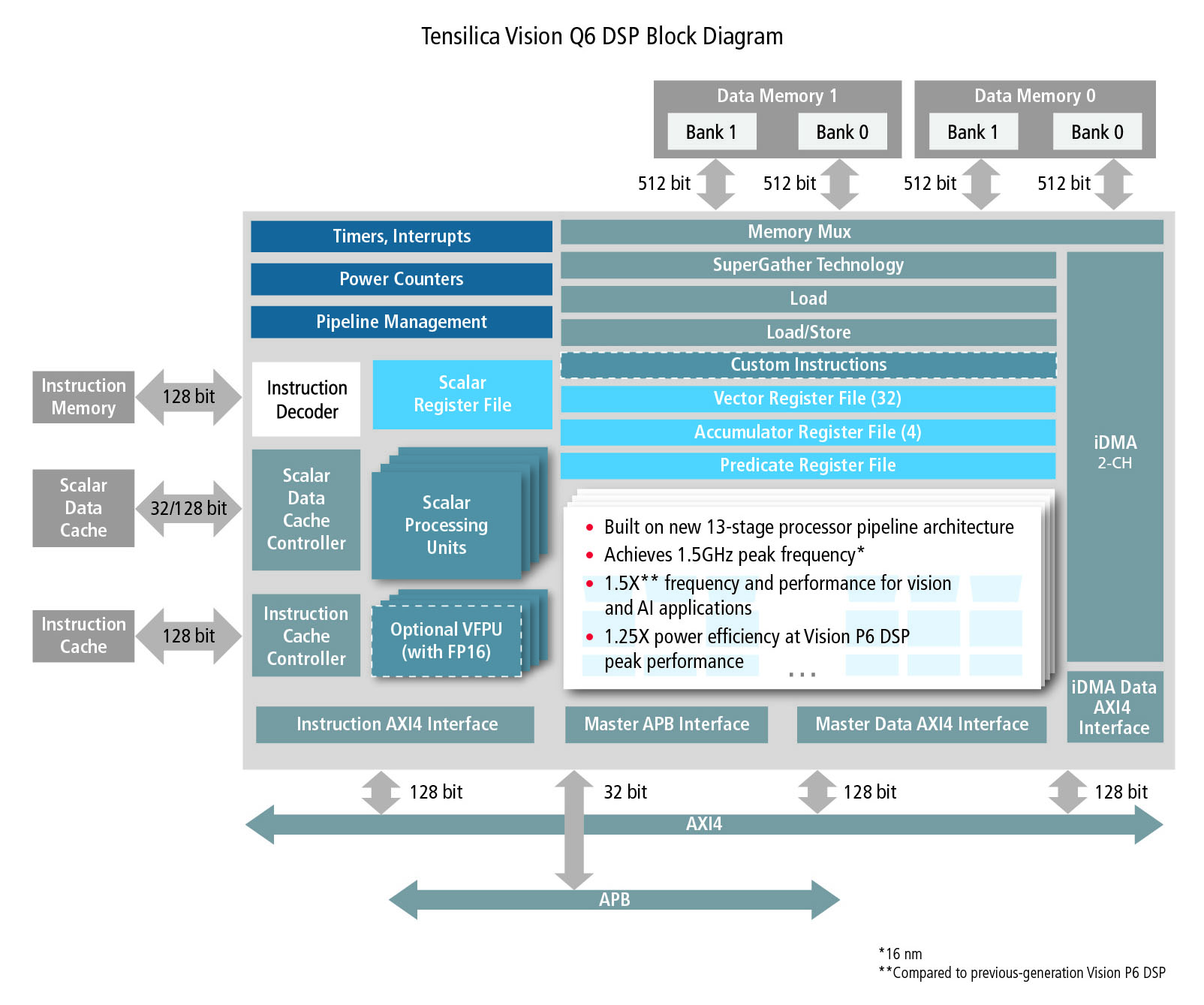
We’ll start with a new revision of Cadence’s (and Tensilica’s) P6 IP block. What do you call the next rev that’s been started with the series P5/P6? P7? Nope: this is the Q6. It’s a superset of the P6, and it’s source-code backwards compatible with the P6 (but not object code – more on that in a sec). They say that it’s 50% faster and has 25% better power efficiency than the P6.
(Click to enlarge; image courtesy Cadence)
Adding three more stages to the pipeline, of course, introduces three more cycles of latency. That’s at least one reason why P6 object code won’t work as expected on a Q6. But the compiler is aware of this – which is why P6 source code can be compiled to run correctly on a Q6.
On the software side of things:
- hey now support Android neural networks
- They’ve added support for TensorFlow and TensorFlow Lite (before, it was just Caffe)
- You can now create or modify your own neural net layers
- They’ve broadened their support of different kinds of neural networks.
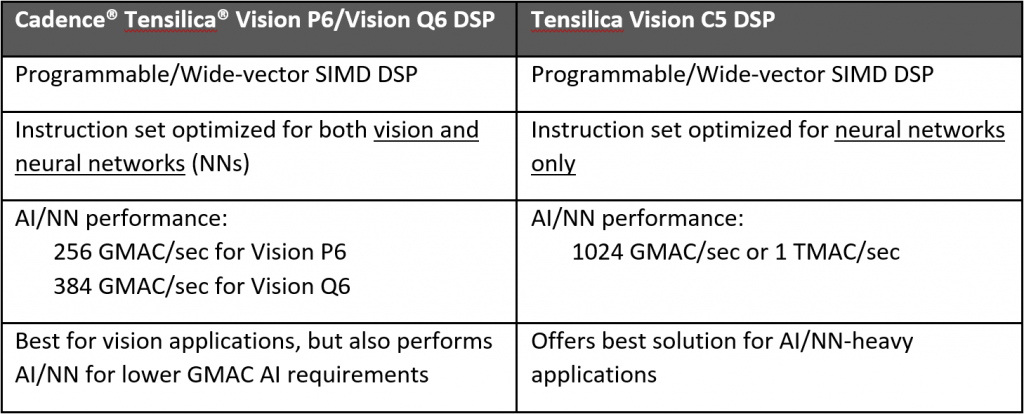
I have to confess that I get a bit confused at times between the P/Q series and the C5. The C5 does CNNs; the P/Q devices do other vision functions plus CNNs (the C5’s CNNs are faster than the P/Q ones).
When I checked in with them about this, they sent this helpful table. At least, helpful to me… hopefully to you as well.
Eyes On You
Meanwhile, there’s a completely different vision-oriented story from Micron: a larger memory intended for use in a video surveillance system. In order to add some context to this announcement, we need to review some basic Internet-of-Things (IoT) challenges.
What makes a device officially an IoT device? Ah, now, if we had an undisputed answer to that question, well, the world would be a simpler place. But we don’t, so I’ll go into my view – which could easily be contested.
I view a device as IoT if:
- It’s network-connected
- It can talk to other devices
- Optionally, it can talk to the cloud (but, practically speaking, this is almost a requirement)
The reason that I’m wishy-washy on that last one is that there is some debate as to how much – if any – data needsto be sent to the cloud. If the cloud is used for some computational element – say, face recognition – then the cloud connection is necessary. If, however, the cloud connection is used simply for analytics, then it’s something that the data collector would like to have (would probably like very much to have), but it’s not essential to the operation of the device.
The first and second ones work together; this captures devices that can talk to each other locally. Many smart-home devices might be able to operate like this, without having to go all the way to the cloud to have that conversation. Now… you might say that this takes the Internet out of the IoT, and you’d be right. To be really technical, if your definition of an IoT device requires connection to the cloud, then you could theoretically have smart-home devices that aren’t IoT.
I see that as a possible point of technical debate, but, for practical reasons, I’m defining a device as IoT if it’s on a network – whether or not that network happens to be (or include) the Internet.
What does this have to do with a new memory? This is a 3D-NAND memory, using a stack 64 layers high, with 8 bits per cell (three-level cell). So that makes for versions with capacity 128 GB and 256 GB. And it’s intended for use in one of the more popular IoT application spaces: security – and, specifically, surveillance video.
Video is an area where you can debate what data should go to the cloud. With many IoT devices, data traffic is pretty sparse. A few bytes here or there (at least for now – connected self-driving cars will exchange torrents of data in the future). It’s because of this sparsity that networks like Sigfox and LoRa can make use of the ISM (industrial-scientific-medical) radio bands, which limit power and traffic.
With video, by contrast, you’re creating tons of data. Do you send that to the cloud or to a local hard drive? The answer, of course, depends on what you want to do with the data. If your camera is outside, nowhere near a building with computer storage, then the cloud is pretty much your only choice. If you want to do fancy processing, then that likely needs to happen in the cloud. And if you want a permanent store of everything seen, then the cloud is also a good choice there.
But the thing is, you’ll be sending up tons of data. What if you want to store the video only for some short time, in case you need to go back and review? The hard disk thing works – if there’s one available for that. It would be easier, however, if the video camera itself could store that data. If kept in non-volatile memory, then the data would survive the loss of power.
And that is, in fact, what this Micron announcement is about. With a memory this large, they say that you can store an entire month’s worth of video on it. You can then start overwriting the oldest stuff in something resembling a circular buffer. They provide firmware for doing this in a way that avoids frame drops and loss of video.
The video system can also be self-monitoring, reporting use and remaining life. And since this memory would need to be reliable, it comes with a 2-million-hour mean time to failure (MTTF*), which amounts to a 0.44% annualized failure rate – a number that they say is better than a hard drive.
When surveillance cameras take on AI capabilities such as those supported by the Cadence (and other similar) IP, they’ll be able to do things like facial recognition locally (selecting from a few locally stored faces). Then there will be yet one more reason not to need a connection.
*You may be familiar with mean-time-between-failures, or MTBF. Apparently, that applies only to systems that can be repaired – and therefore live again to fail another time in the future. If the system can’t be repaired, then you get only one failure and you’re done – as measured by the MTTF.
More info:
Micron surveillance video memory



{kind=link}
What do you think of Cadence’s new vision IP and Micron’s new memory?