


Cadence has had a number of announcements over the last few months. I’ve been collecting them up so that we can review them here now. We’ll cover four stories: their Cloudburst announcement, their Clarity 3D solver, a ConnX update, and a vision processor update.
Forecast Cloudy
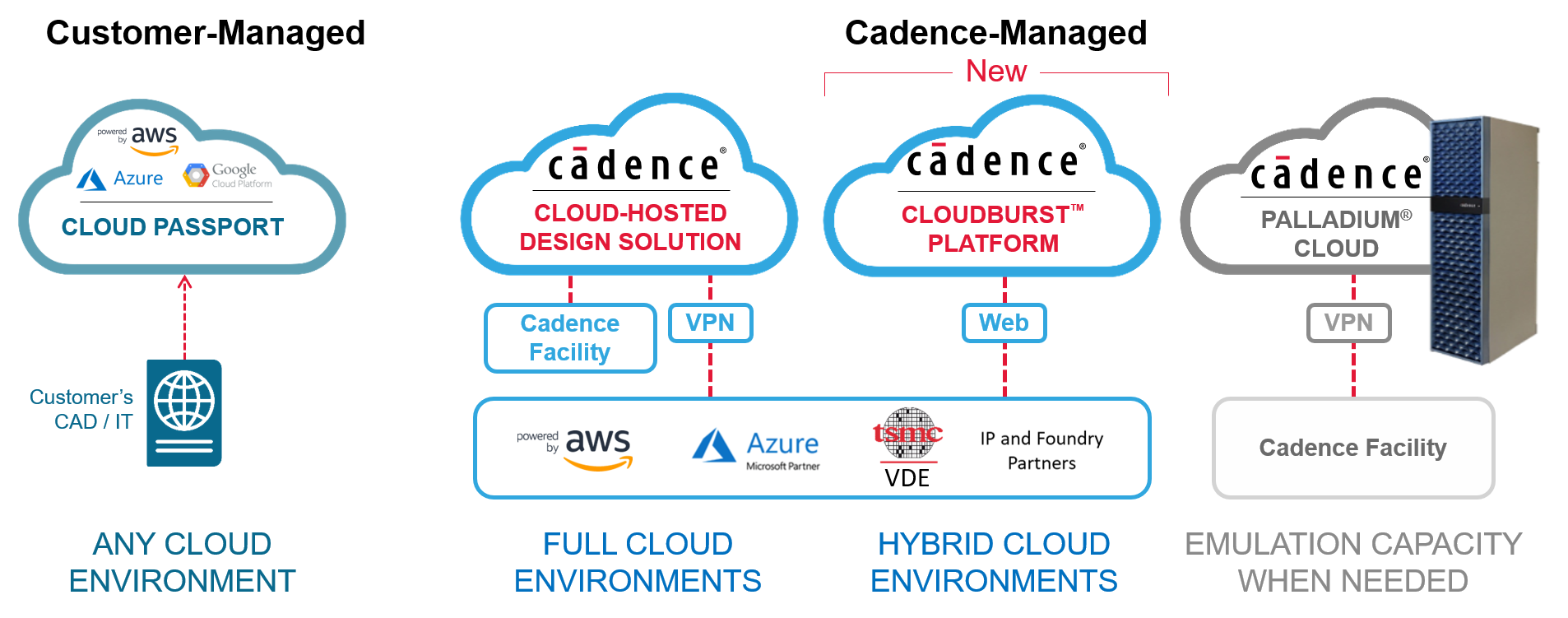
Last year, Cadence updated their cloud strategy, and we spent some ink covering it. If you’re not familiar with Cadence’s cloud position prior to their recent Cloudburst announcement, then last year’s piece might make a good review.
But, at that time, they were offering a binary choice: either cloud-ready software that the customer could manage on their own or a Cadence-run cloud. What they found was that many of their customers aren’t quite so binary. Larger companies in particular have invested heavily in their own server farms for hosting tools. They need to pay for those systems by ensuring that they’re used to capacity.
This brings up the usual peak dilemma. If you have enough hardware to cover the peaks, then it’s going to spend a lot of time underutilized when it’s not peak time. On the other hand, if all the hardware is well utilized on a daily basis, then they’ll be hosed at crunch time.
Which is why Cadence has now turned their binary decision into a spectrum through their Cloudburst hybrid approach. Such approaches aren’t new, but putting them together has involved lots of already-overburdened IT folks to build the links between internal and cloud systems. What’s different here is that Cloudburst requires no IT involvement; everything happens via the web. CAD folks will still need to help when it comes to permissions and project segregation (Cadence is not involved in that aspect), but no IT is required.
(Click to enlarge; image courtesy Cadence)
If you want to take advantage of this, you still need to have a conversation with Cadence, however, since no two chip-design flows are alike. That said, they claim that you can be up and running in a couple of days.
Cadence makes available both Amazon’s AWS and Microsoft’s Azure. At least for now, there’s no Google option. You can select which service to use; if you have no preference, then Cadence chooses. The setup allows for non-Cadence tools in the flow – as long as you have permission to run those tools up there.
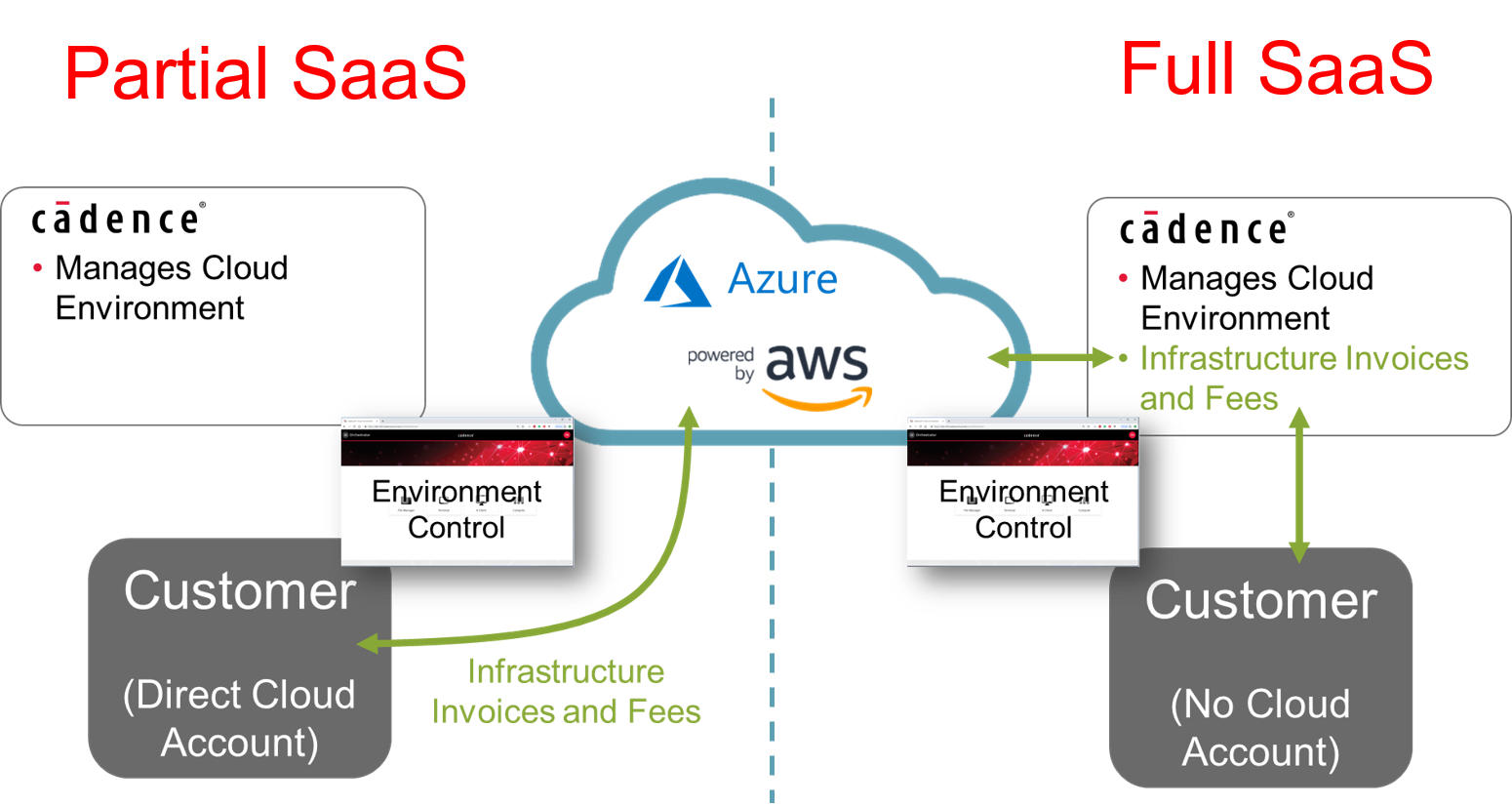
You can also operate this as what they call “full SaaS” or “partial SaaS.” With full SaaS, Cadence is your provider, and all the billing comes through them. In a partial SaaS situation, you’re working directly with your cloud provider, and they send the bills to you.
(Image courtesy Cadence)
One possible hitch could be IP used in the design. Some IP providers restrict where their IP can be, so you need permission from each IP provider before you can include their IP in a design being processed in the cloud.
Cloud Clarity
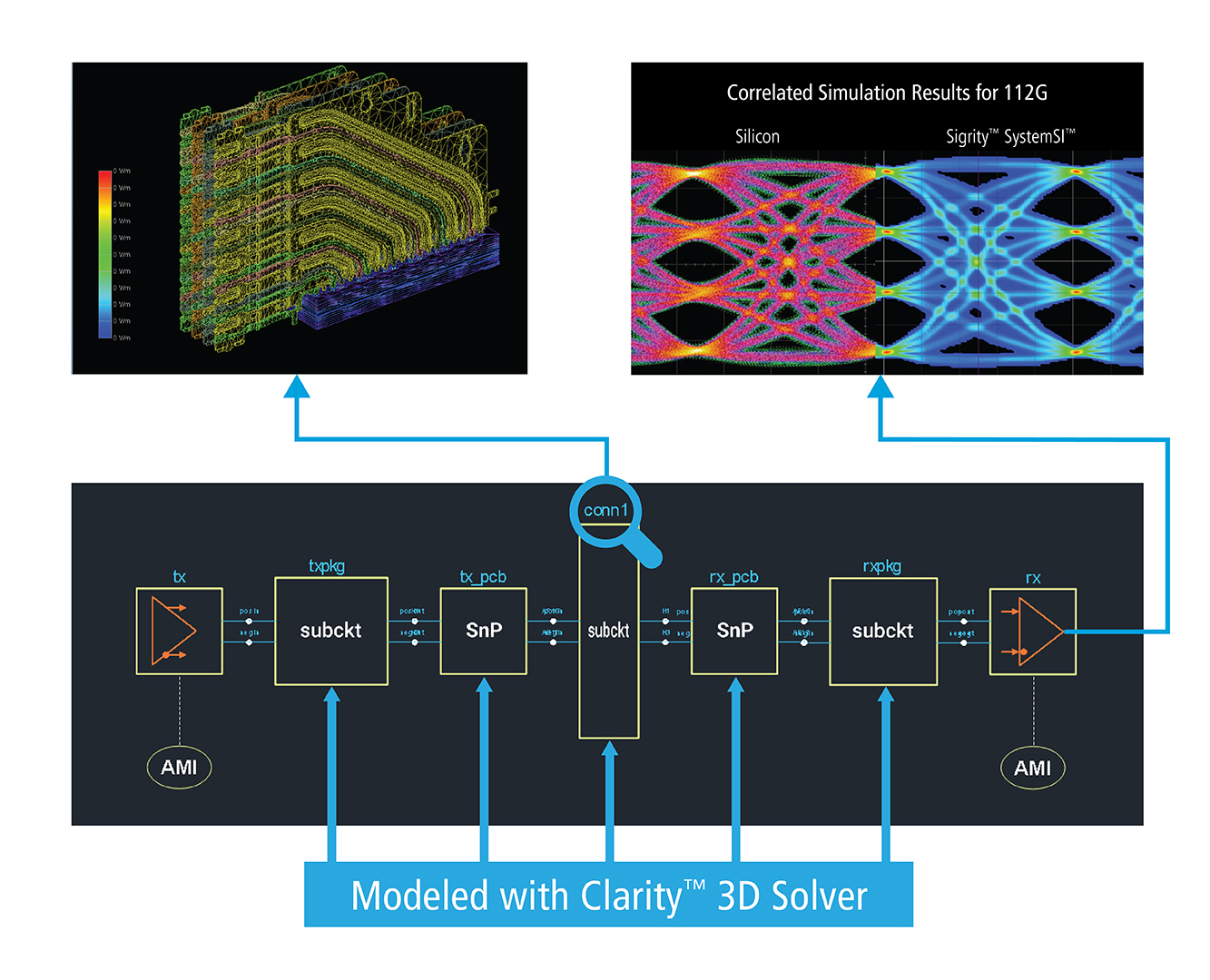
Shortly after their Cloudburst announcement, Cadence announced a new 3D solver, Clarity 3D. It can, in fact, run in Cloudburst – a good thing for a compute-heavy problem – although it’s not required to. They’ve addressed two big issues with this tool: meshing and capacity.
Meshing is the process of taking an object and breaking it down into a mesh of shapes (typically triangles and tetrahedra) at some small size that determines the resolution of the calculations. As Cadence tells it, this is traditionally a very time-consuming process, dominating run times. They’ve addressed that in Clarity 3D, getting performance that they say is 10 times greater than legacy tools can give when lots of CPUs are involved (they got 12.3X faster for a 112-gig connector interface and 10.4X faster for a DDR4 interface, both with 320 CPUs). Speed notwithstanding, they’re still claiming “gold-standard accuracy.”
The other big challenge with solver tools is capacity. At some point, if what you’re trying to model is too large, you need to break the problem up into manageable bi(y)tes. You then run each piece individually, probably on different machines. Then comes the fun part: stitching the results back together, by hand – which Cadence describes as an error-prone process.
Instead, Clarity 3D has, by Cadence’s description, “virtually unlimited capacity.” You can pick any machine or combination of machines and Clarity 3D will break up the original design into chunks that can be handled by those machines. The tradeoff is, of course, compute time. Got machines with lots of memory (which equals high capacity)? Then things will run faster. If you have only smallish machines, then you can break the problem down as much as needed, but the full solution may take longer.
Breaking up the design and stitching the results together are done automatically. That can be helpful in particular if you’re running on different machines at different times (in which case you would have had to do multiple breakings-up and multiple stitchings-together – by hand – if you didn’t have this feature).
In combination with other electrical tools like Sigrity, they’re trying to address challenging applications like signal integrity through high-speed interconnects involving, for example, PAM-4 signals, and power integrity for entire modules and systems.
(Click to enlarge; image courtesy Cadence)
Processor Updates
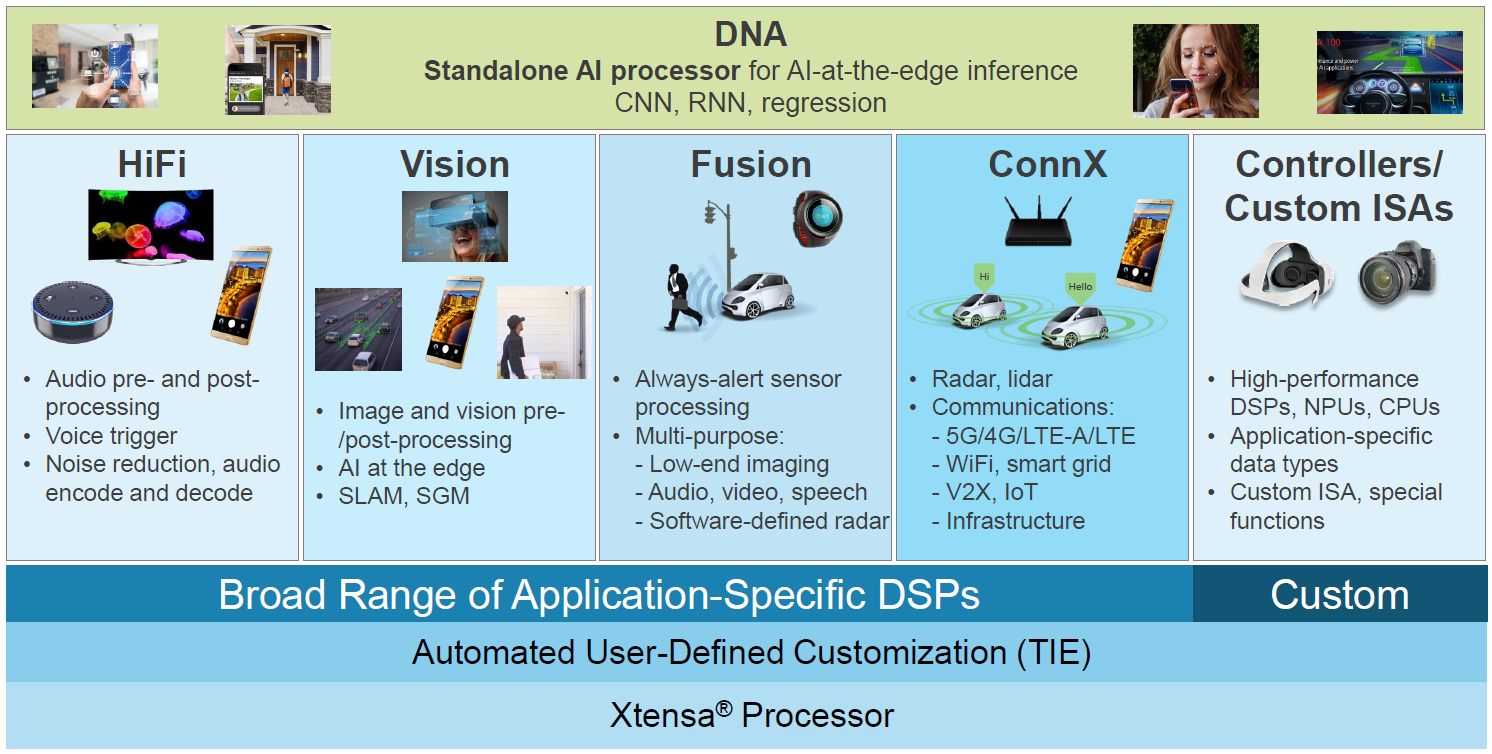
Finally, Cadence has had a couple of updates to their ConnX and Vision DSP families. In order to help position where these families belong in the panoply of specialized processors enabled by their Tensilica technology, they’ve put together the following guide. You can see that, for today, we’ll be focusing on radar/lidar/communications apps and vision apps.
(Click to enlarge; image courtesy Cadence)
They went further in outlining where these families have a role in the all-popular automotive environment.
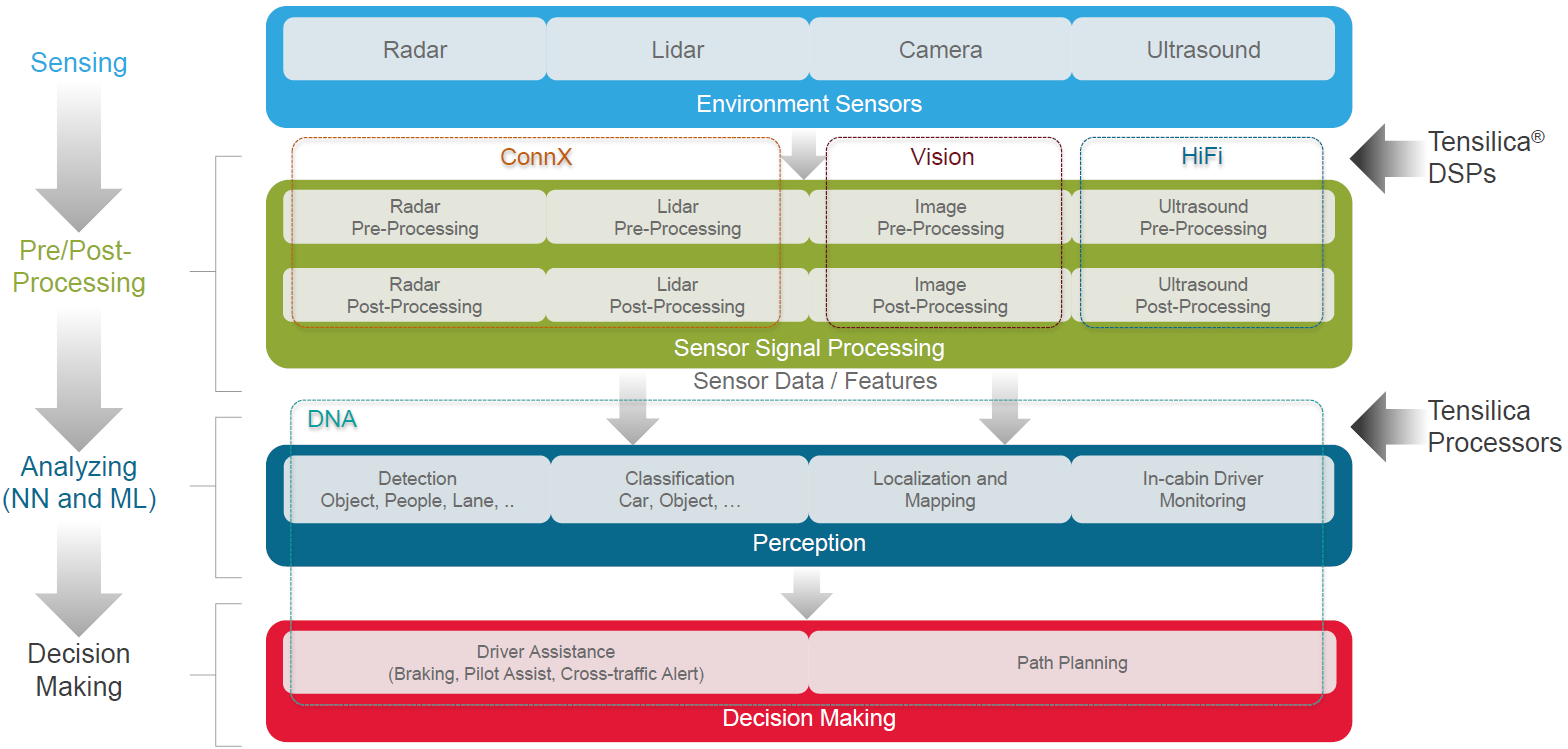
(Click to enlarge; image courtesy Cadence)
For ConnX, they’ve announced the B20 offering. The key here is receiver front-end processing, right near an antenna. There’s lots of conversion between time and frequency domains, and that, of course, involves complex math. Not just complicated math, but math with complex numbers.
They claim to have achieved as much as 30X faster performance for some portions of communications apps and 10X faster for portions of radar and lidar apps. They got this in part based on the following improvements:
- A deeper pipeline that allows 1.4-GHz clocking.
- An option for twice the SIMD width (x32), increasing parallelism.
- Options for single- and half-precision floating-point operations.
- Forward error correction (FEC) acceleration options for algorithms like Viterbi, Turbo, Polar, and LPDC.
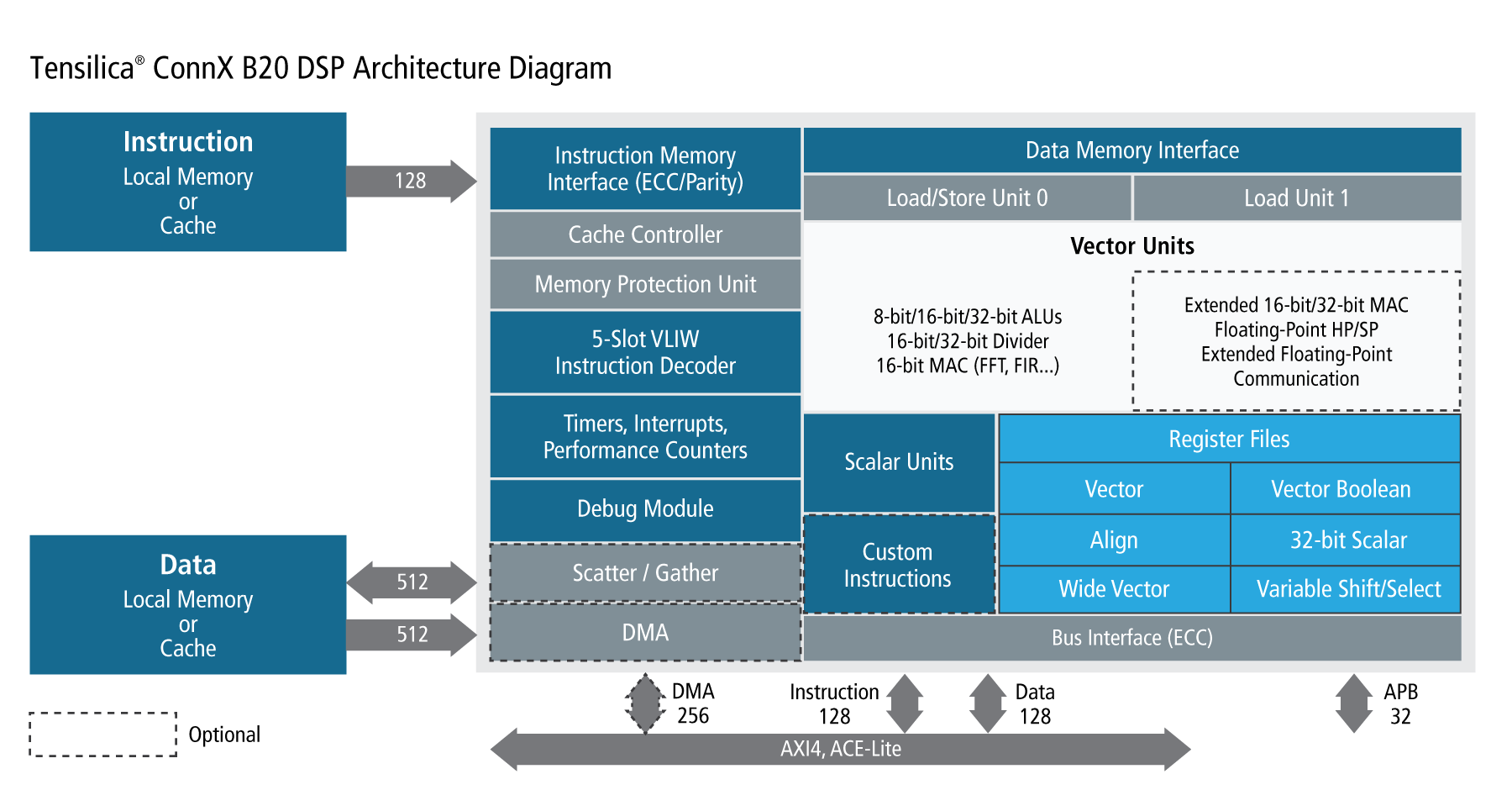
(Click to enlarge; image courtesy Cadence)
Radar and lidar are, of course, forms of vision (if rudimentary, at least in their current incarnations). Cadence says that the small images that result can be managed on a ConnX device – or you could use one of their Vision family processors, which we’ve covered before, and for which there is now a new member: the Q7.
The first notable thing in the Q7 family vs. the earlier Q6 family is that they’ve doubled the number of multiply-accumulate (MAC) blocks. Wait, no, that’s not the notable part. What’s notable is that they did that… without increasing the silicon area. I know, right? Whaaaaaat? They say that they came up with architectural and implementation improvements to their MAC that greatly reduced their size, allowing them to break even area-wise with twice as many.
Twice as many can mean much higher performance. Along with instruction-set architecture (ISA) improvements and on-the-fly weight decompression (for AI functions), they doubled the performance of single- and half-precision floating-point operations as well as operations for a very specific application they appear to be targeting with this version: simultaneous location and mapping (SLAM).
SLAM is an evolving application where you figure out where you are while building a map of an unknown area. This isn’t for mapping you to the corner bar (or, worse yet, getting you back home when you no longer know where you are), but is rather used by robots and drones and their ilk when figuring out their environment.
It’s also used for augmented and virtual reality (AR/VR) applications in what’s being called “inside-out tracking.” I know, if you’re not hip to what’s going on there, it’s a strange phrase, but it gets to how an AR/VR user knows their position. Older technology uses external sensors that watch you – that’s outside-in. With inside-out tracking, you’re figuring it out yourself.
This appears to be a major target of the Q7, so we’ll have to see whether this application becomes a serious repeating topic (or goes the way of “push technology”).
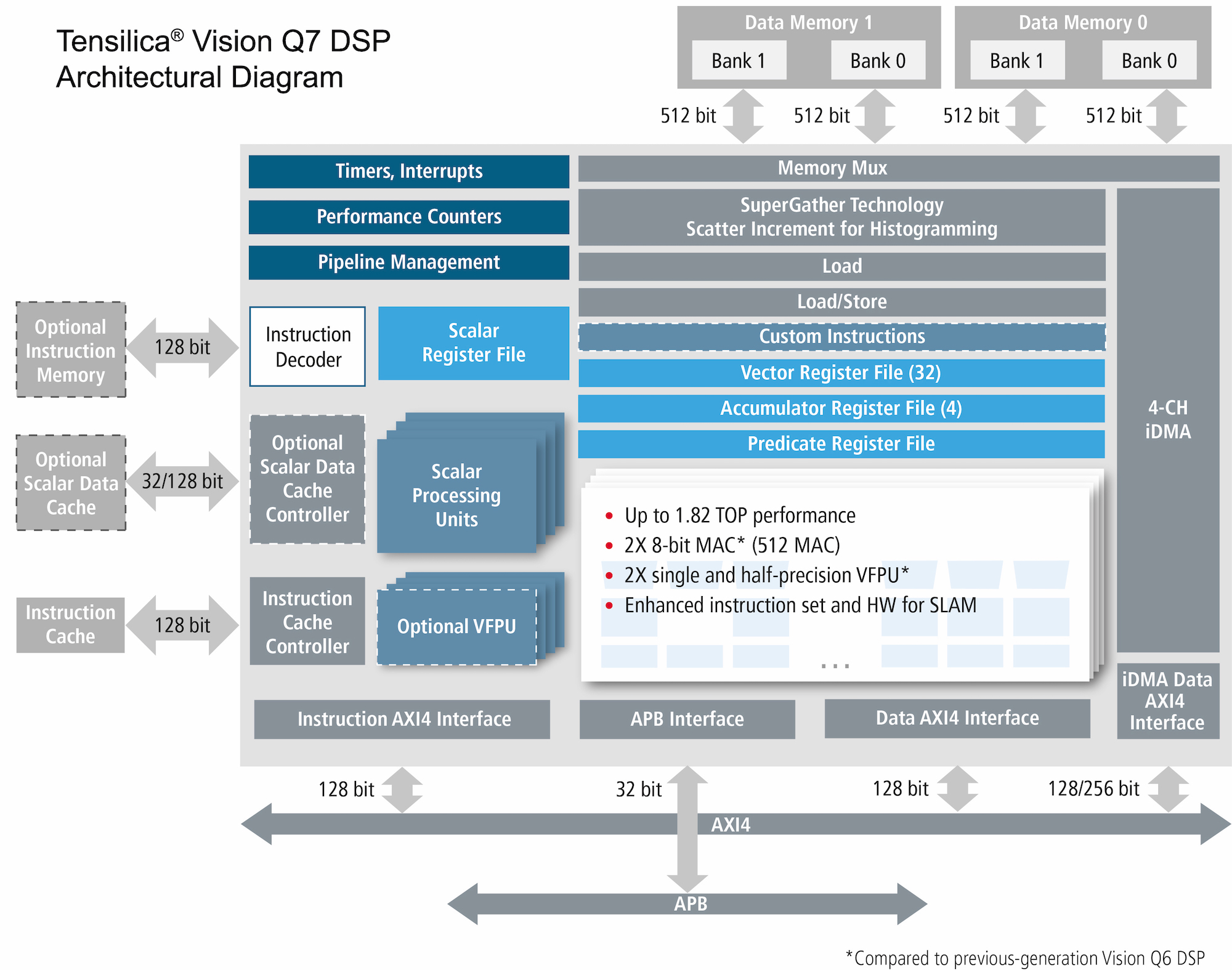
(Click to enlarge; image courtesy Cadence)
By the way, many vision applications make use of neural-net technology for classification and identification, so it can be confusing as to which pieces are vision processing and which are neural-net processing. The following image can help to clear that up.
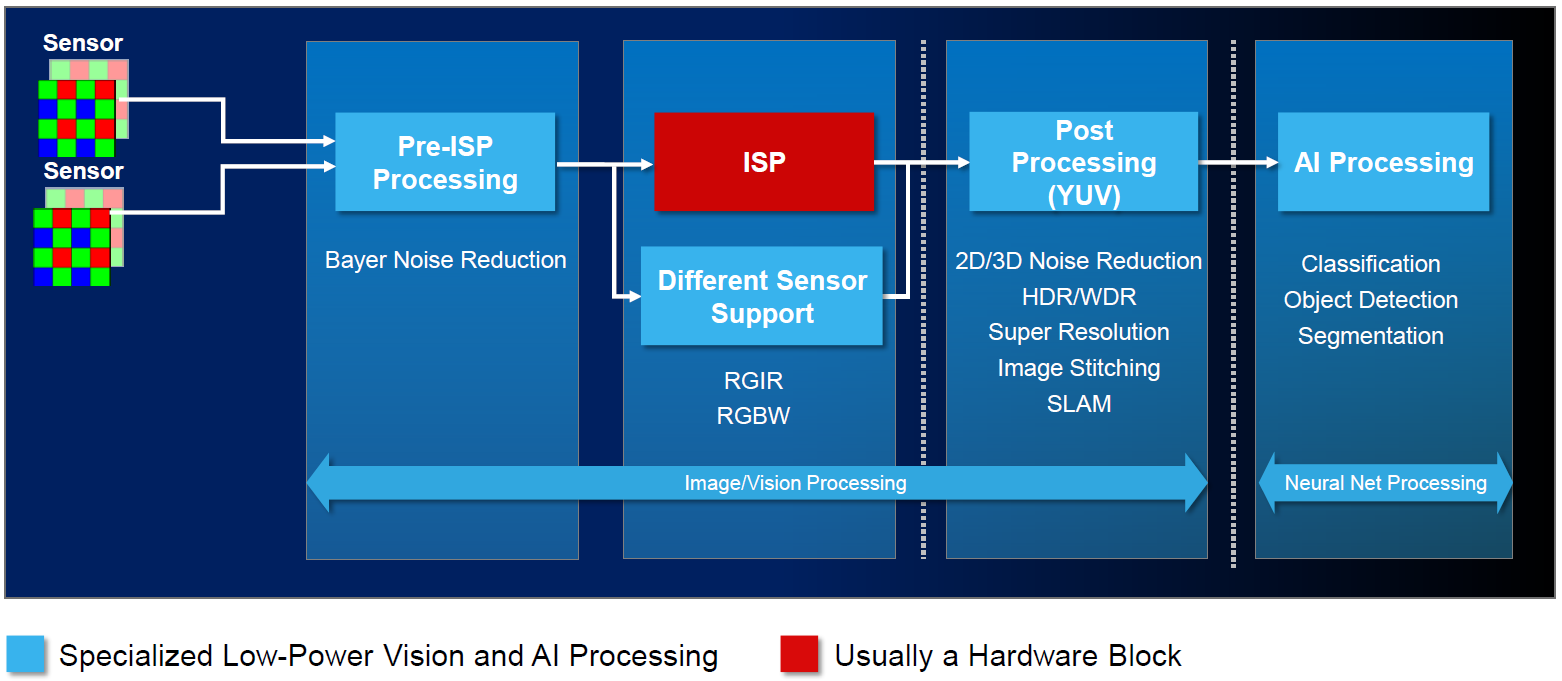
(Click to enlarge; image courtesy Cadence)
Of course, now that we’ve caught up on these four announcements, we head to DAC as this is published, where I have meetings on a couple more announcements. So we may be coming back to you in the coming months with more from Cadence (not to mention from other EDA folks).
More info:
Sourcing credit:
Craig Johnson, VP of Cloud Business Development (Cloudburst)
Brad Griffin, Product Management Group Director, System Analysis Group (Clarity 3D)
Neil Robinson, Director of Product Marketing for Tensilica Radar, Lidar and Communications DSPs (ConnX)
Pulin Desai, Product Marketing Director, Tensilica Vision DSP Product Line (Vision Q7)


