

The way in which my mind leaps from topic to topic with the agility of a young mountain goat sometimes gives me pause for thought and makes me wonder: “Is it just me or do everyone’s brains work this way?”
I’m reminded of the British science fiction television series Doctor Who — in particular, the Blink episode in the third series following the 2005 reboot when the Tenth Doctor (portrayed by David Tennant) says: “People assume that time is a strict progression of cause to effect, but actually, from a non-linear, non-subjective viewpoint, it’s more like a big ball of wibbly-wobbly, timey-wimey… stuff.” The sad thing is that the “wibbly-wobbly, timey-wimey” part largely describes the inner workings of my poor old noggin.
Did you ever see the British science fiction television series Red Dwarf? A very brief summary is that our hero Dave Lister is a low-ranking technician on a gigantic mining spaceship — the eponymous Red Dwarf. Due to a series of unfortunate events, Dave wakes up after spending three million years in suspended animation to discover that he’s the last living human. His only companions are Holly (the ship’s computer), Arnold Rimmer (a hologram of Dave’s erstwhile bunkmate), and a lifeform called Cat (who evolved over the course of the three million years from Dave’s pregnant cat).
The reason I mention this here is that in Episode 3 of Series III we meet a genetically mutated non-human life-form with shape-changing properties called a Polymorph. Although I didn’t know it at the time, polymorphism is a Greek word that means “many-shaped,” and this concept appears all over the place, such as materials science, biology, and computing. In computer programming, for example, the term “operator overloading,” which is sometimes referred to as “ad hoc polymorphism,” is a specific case of polymorphism in which different operators have different implementations depending on their arguments.
“But what has any of this to do with the price of tea on Trantor or the cost of coffee beans on Coruscant?” I hear you cry. Well, were you getting worried that — as an industry — we were falling behind with respect to overloading our acronyms? If so, you need fear no more because I’m here to tell you that acronym overloading is alive and well. Take Function as a Service (FaaS) as an example. Wikipedia defines this as, “A category of cloud computing services that provides a platform allowing customers to develop, run, and manage application functionalities without the complexity of building and maintaining the infrastructure typically associated with developing and launching an app.” In a classic case of acronym overloading, I just discovered that FaaS may also be used to refer to FPGA as a Service, in which case we are talking about an FPGA-based fog or cloud platform that can be used to dramatically accelerate your Big Data workloads.
Everything we’ve discussed thus far was triggered like a cascading chain of dominos by my chatting with the clever chaps and chapesses at VMaccel who are laser-focused on offering a cloud platform that provides the FPGA flavor of the FaaS acronym.
Just to set the scene, let’s remind ourselves that today’s uber-complex central processing units (CPUs) are outrageously good at many tasks, especially those of the decision-making variety, but they can be horrendously inefficient with respect to the processing required by many Big Data applications. Another approach we can use to satisfy our processing requirements is to use graphics processing units (GPUs), which are essentially formed from an array of simple CPU cores. Whereas a CPU may contain anywhere from 1 to 64 complex cores, a GPU may contain hundreds or thousands of simpler cores.
If we think of CPUs and GPUs as being coarse-grained and medium-grained on the core front, respectively, then we might also think of field-programmable gate arrays (FPGAs) as being fine-grained because they can be configured (programmed) to perform appropriate processing tasks in a massively parallel fashion (see also What the FAQ are CPUs, MPUs, MCUs, and GPUs?). As a result, FPGAs in general, and FaaS in particular, are of extreme interest when it comes to use cases like artificial intelligence (AI), machine learning (ML), and deep learning (DL); data analytics and database processing; video analytics and transcoding; biotechnology (e.g., genomics and protein folding); finance and high-frequency trading (HFT); cryptography, research, electronic design automation (EDA), and… the list goes on.

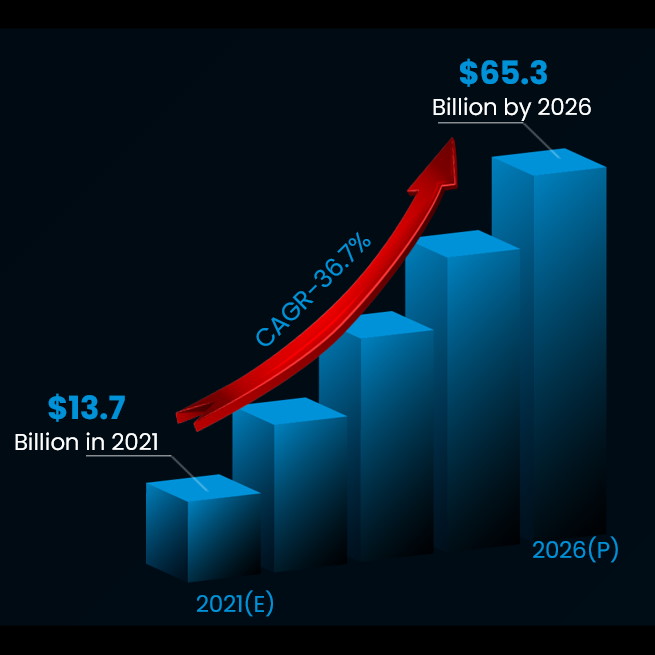
FPGAs can offer up to 100X higher performance (Image source: VMAccel)
What we are talking about here is up to 100X the performance, which is something of an attention-grabber for those who are intent on performing these projects. One way to look at this is that if you have a task that takes 100 hours (4+ days) on a CPU-based platform, you can set this task running before heading out to lunch and see the results on your return if you switch to an FPGA-based environment. How about a task that takes 1,000 hours (~6 weeks) when using a CPU-based solution? In this case, switching to an FPGA-based platform means you could start the task early in the morning and gloat over the results before heading home to watch the evening news.
Sad to relate, however, there is an elephant in the room, a bump in the road, and a fly in the soup, as it were (I never metaphor I didn’t like). Although many companies have basked in the benefits of FPGA acceleration when creating custom implementations on their own premises (“on-prem”), they have enjoyed less success whilst trying to migrate these solutions into the cloud. One reason for this is that although all the major cloud vendors like to boast that they offer CPU, GPU, and FPGA capabilities, the grim reality is that they tend to focus on the CPU and GPU side of things while somewhat sheepishly supporting only a “one size fits all” type of FPGA environment.
The problem is that — much like with people rummaging around a “one size fits all” clothing emporium — the result is a less-than-optimal fit that makes you stand proud in the crowd (but not in a good way) in the vast majority of cases. This is particularly unfortunate when we discover that, according to a report by Verified Market Research, the data center acceleration market is anticipated to grow from an estimated $13.7 billion in 2021 to a predicted $65.3 billion by 2026.
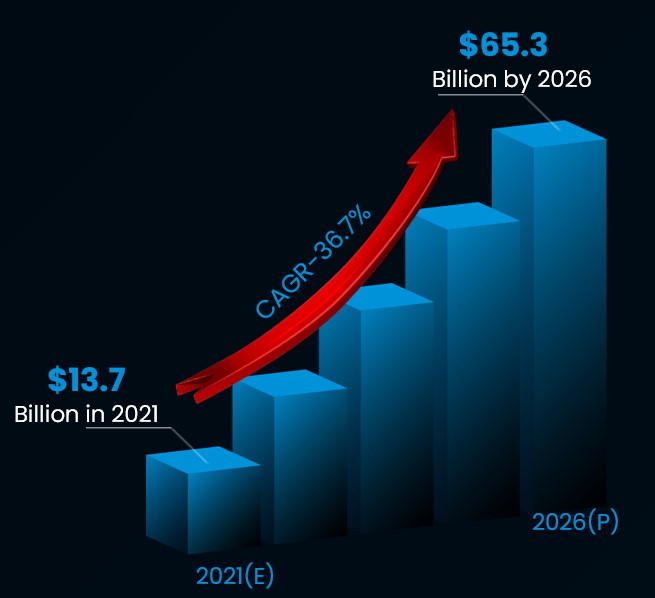
The data center accelerator market 2021-2026 (Image source: VMAccel)
What can I say? “I like big graphs and I cannot lie” (to paraphrase American rapper Sir Mix-a-Lot). This explains why, rather than trying to offer a solution for all seasons (CPUs + GPUs + FPGAs), the folks at VMAccel have determined to focus on offering the best FPGA-based acceleration solution currently available in the Orion Arm.
In order to achieve this, as discussed in this video, VMAccel has built a dynamic cloud platform capable of enabling the full potential of FPGAs while still managing to accommodate the widely varied needs of customers and ISVs.
The guys and gals at VMAccel claim their cloud platform enables users of all skill levels to leverage FPGAs in their workloads. As opposed to squeezing users into a one-size-fits-all solution, VMAccel offers a customized dynamic approach in which instances are tailored to client workloads. In addition to running on virtual machines (VMs), Kubernetes (K8s), and bare metal, VMAccel supports simple one-click acceleration applications for users who do not wish to develop their own FPGA code, all the way up to preconfigured instances with complete development environments, drivers, simulation tools, and everything else necessary for development on FPGAs. VMAccel also supports a wide range of developer flows, including low-level RTL, OpenCL, C++, Python, and more.
As VMAccel’s CEO Darrick Horton says: “FPGAs have traditionally been shrouded in complexity and subject to steep learning curves and limited accessibility. These factors have greatly inhibited widespread adoption of the technology. VMAccel aims to facilitate adoption of FPGA technology by reducing complexity and allowing ease-of-use and open accessibility while simultaneously preserving the levels of performance and customization that can be achieved on-prem.”
Well, I’m sold. All I need is an application to accelerate. How about you? Do you see cloud-based FPGA acceleration in your future? If so, you should reach out to the folks at VMAccel and ask them to tell you more about how they can bring a smile to your face with respect to the price-performance combo they proudly proffer.



Hi Max, interesting, informative and entertaining as usual. Are you aware of US patent 10,181,003, Processing Circuits for Parallel Asynchronous Modeling and Execution? No CPU, no GPU just millions of parallel self-propagating decision flowcharts executing in substrate or as configurable FPGA hardware or as clock-less FPFA, Field Programmable Flowchart Array hardware.
Hi Ron — I wasn’t aware of this patent — I will have to take a look — thanks so much for sharing — now I’m wondering what impact such a patent might have on anyone using FPGAs to perform massively parallel processing…
Hi Max, I think it means that FPGA’s will become viable for a much larger user base and ‘massively parallel’ thinking and designing can begin.
What about design entry? VMAccel no doubt takes care of that. EXCEPT that they never define what kind of input/description is required.
Then Ron comes along with a clock less FPGA patent that clearly glosses over the complexity of asynch design.
Yeah, it is flow chart based — as if showing a decision block is better than and/or/invert gates is better.
There is no clock, however there is a delay block used to allow circuits to resolve/settle. The difference is that a clock period is fixed while a delay time can be generated(if you know how and how much)
Apparently it is assumed that flow charts magically eliminate the need for something analogous to a compiler and its associated language/syntax.
Are programmers simply wasting their time learning different languages? Should they just draw flow charts and be done with it?
Ron did mention events and delay generation and the fact that asynchronous design is difficult. So far, flow charts do not make it easy because flow charts have been around forever.
Boolean Algebra is the only way to correctly define the logic design, period! If there is computation involved then operator precedence must also be handled.
Another couple of vague solutions for undefined problems.
Hi Karl, thank you for commenting and I am not surprised at your perception of the technology because at first most have the same perception.
Yes the patent glosses over the complexity of ‘current and past’ asynchronous design because it is a non-issue with a Flowpro Machine. There isn’t any handshake and a user is completely unaware of the asynchrony of the circuits but is completely aware of the asynchronous (parallel) nature of the computational machine. This is a key point to massively parallel substrate based systems. I think a quick overview of propagating a flowchart will clear up some of your concerns.
Flowcharts fell out of favor as a planning tool for writing code because they weren’t up to date as the code changed and they quickly devolved into spaghetti code. A Flowpro Machine uses decision flowcharts as the code so they are always up to date and hierarchical objects are used to eliminate the spaghetti code. A Flowpro Machine is referred to as a single flowchart or a collection of flowcharts. A Flowpro Machine executes (propagates is a better word) when voltage is applied to the enable block (bubble at the top) of the flowchart. Keep in mind that thousands of these flowcharts can be enabled at the same instant and begin propagating. I call this a computational wave because all enable blocks are propagating a low to high transition from the enable block to the first block of each flowchart. Each transition flows through this first block causing an action or a ‘latched’ test as the transition signal continues on to the next block of each flowchart. Once enabled a flowchart is always propagating somewhere. A flow chart path that loops back to a previously executed block will clear the just executed path and begin a new transition trail through that flowchart.
You are correct, a decision block isn’t any better than a gate to most engineers but I have found that it is to domain experts.
There isn’t a need for a delay block because the circuits are leading edge dependent.
Flowpro Machines have a compile process. Flowpro Machine that is targeted to execute on a Turing Machine compiles to a data file that represents the flowchart which is then executed by a small kernel of that Turing Machine. A Turing Machine simulates a Flowpro Machine by executing the flowcharts in an ordered fashion. A Flowpro Machine targeted at substrate compiles to fixed circuits that are ‘Atomic’ Action and Tests structures which are then assembled into variable Tasks structures.
A big advantage of “they just draw flowcharts” is the concentration is on the algorithm and not the solution to performing the algorithm. Best of all, multiple domain specific experts can participate in creating the algorithm, without thinking about code. Complexity of our systems is increasing and multiple hierarchical flowcharts is, in my opinion, an excellent way to manage complexity.
Boolean algebra is not the only way to define logic design but it is better in some cases. Using a gate and two signals will use fewer transistors than decision blocks performing the same function. Or, a two input and gate could be used as the test input of a decision block. But when the logic gets really complex we have found that flowchart logic on Turing Machines almost always used less memory. The more complicated the bigger the advantage of Flowpro.
Any solution that is handled by a Turing Machine can also be handled by a Flowpro Machine. The reverse is not true because of true parallelism!