


We’ve talked about audio company DSP Concepts before. We’ve looked at their Audio Weaver tool, and we’ve looked at how their offering has evolved from tools to reference designs. But what I learned from them came through typical phone or in-person briefings using slideware. I recently had a chance to see some of what they do in a live demo, and the ensuing discussion helped to crystallize the kinds of problems they solve and don’t solve (some of the latter presumably being “yet”).
So let’s set up the problems facing audio engineers. And, honestly, how you view the problem probably has to do with what tools you might have to fix it. For smart-speaker companies like Amazon and Google, pretty much every problem can be solved by more artificial intelligence (AI). If the smart speakers aren’t always understanding the wake word, then, by simply feeding the training system more difficult or extreme examples over time, you’ll get there.
DSP Concepts’ notion, however, is that, to the extent that some of the difficulty in understanding the wake word may come not from, say, accents, but from noise in the audio stream. Clean that up, and, well, you’ve made all the other work easier (if not outright easy). Their latest announcement is of their TalkTo product, which handles some of the audio issues that have been trickier to solve.
They operate at the bottom of an audio stack, dealing with the raw microphone input. They don’t do anything to work with the cleaned-up sound: there are lots of other folks doing that, with parts of it being for the edge and the tough parts being done in the cloud. The following is their picture of that stack (turned sideways, where AEC is “acoustic echo cancellation,” ASR is “automatic speech recognition,” and NLU is “natural-language understanding”). In this picture, DSP Concepts occupies the AFE slot.
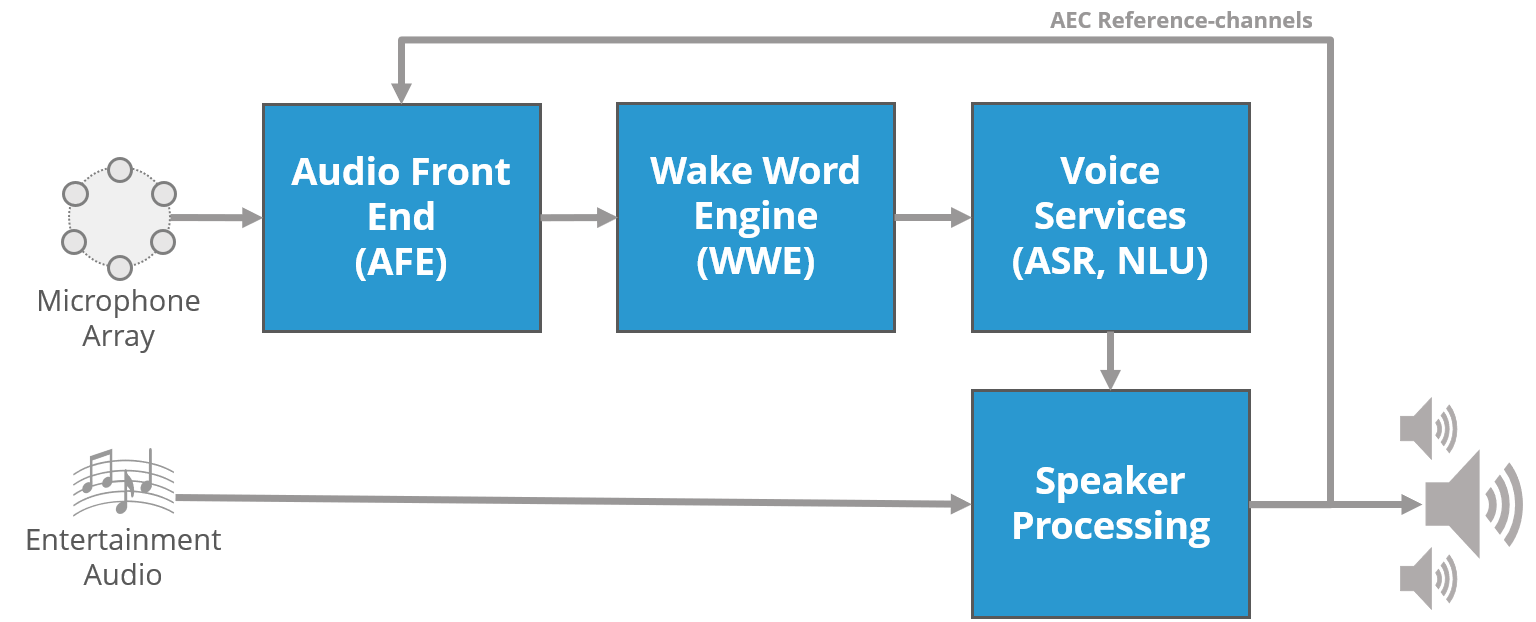
(Image courtesy DSP Concepts)
So let’s look through some of the audio problems that have been solved and not solved to help understand the challenges that DSP Concepts and any other similar company might be overcoming for audio algorithms higher up in the stack.
Noise Cancellation
This falls mostly in the “problem solved” category. We’ve had noise-cancelling headphones around for a long time, although the earliest ones could really handle only periodic noise. DSP Concepts refers to this as stationary noise – it’s stationary both in the sense of being fixed in position, but also of the noise itself being constant.
Airplane noise or road noise (to some extent) are good examples of this. The key here is that the microphones have an unchanging periodic(ish) source that they can “learn” and filter out. Put on the older headphones, and you hear the noise slowly die away over a few seconds. The reason for this is that it takes a while to sample the periodic noise.
Given the advent of faster electronics, however, it becomes possible to hear any sound and generate the inverse of that sound fast enough that our ears don’t notice the latency, and now you can cancel non-periodic sounds as well. We talked about that in our coverage of Usound earlier this year. So, while it may take time for such technology to work its way into consumer products, at least it exists, and it could be checked off as a solved problem.
Echo Cancellation
If you have a speaker playing what’s going into the microphone, and if the microphone can hear it, you can have some great fun with infinite echoes. So echo cancellation has been an important technology – one that’s partly solved.
As DSP Concepts describes it, single- and double-channel (aka stereo) echo cancellation has been done. For a single channel, it’s relatively straightforward because you have the clean signal going into the speakers that you can then subtract from the microphone input. Of course, it’s not quite so simple, since the physics of the speakers distorts the clean signal. And if the system isn’t integrated by a single company, then the box dealing with the microphone may not have access to the signal going to the speakers.
Stereo would be a tougher variant on this concept, but, per DSP Concepts, it’s now a solved problem.
The thing is, however, we’re going beyond stereo these days, both with speakers and with microphones. So-called sound bars may have multiple speakers and/or multiple microphones. This might seem like simply a further extension of the stereo problem, but, as DSP Concepts tells it, the stereo solutions don’t extend well to more than two channels. Room acoustics, while a consideration for any kind of echo cancellation, become more of an issue with multiple mics and speakers.
Non-Stationary Noise
Noise and echo cancellation have been well attested for a long time, whether for conference calls or karaoke. But, as more people use smart speakers, we have a new problem: the accuracy of speech recognition. It starts with the wake word and then applies to whatever speech is captured after that word.
The challenge is the fact that no room becomes silent when you want to talk to your speaker. There are multiple other noise sources – one of which may be the smart speaker itself. The latter is referred to as barge-in, since your commands are barging into an ongoing sound stream. You need your commands to be heard over, or despite, the sound of the speakers.
Many – in fact, most – such noises aren’t stationary. Some are fixed in position, but they don’t put out constant sound. A TV, for example, will have tons of non-periodic sound – or it may make no sound at all when off.
We talked about cancelling non-periodic sounds, but this is different. This has to do not with, say, cancelling all sounds that aren’t part of an input stream, but with compensating for things in a room that might make life difficult for a smart speaker. And this is part of what’s featured with the new TalkTo offering. Let’s say the TV turns on: DSP Concepts can localize the source of the sound and then cancel it on an ongoing basis. It takes 2-3 seconds for this to happen after a new source turns on.
For the time being, it’s important that the sound not be moving around. This helps the noise-cancellation algorithms to identify more clearly which sounds are the noise to be cancelled. I saw a demonstration of this in a conference room, where music was playing – loudly, and increasingly more so – while someone said, “Alexa.”
They said it loudly and quietly, near the mic and at the opposite end of the (largish) conference room, facing the speaker and even facing the wall away from the speaker at the other end of the room. At times I almost couldn’t hear it myself. But the system picked the “Alexa” out of the sound every time. They say that they did a demo like this for some normally reserved Sony audio folks once, and they literally applauded.
This works with multiple speakers and microphones, so they claim to have done what simple extension of stereo was unable to do well. They manage this through the use of adaptive filters, and they can eliminate individual microphone streams from the whole as necessary.
So their advice to the Amazons of the world is, “Stop working so hard on trying to understand the wake word under every possible distortion and condition. Let us clean up the sound first so that it’s easier for you to parse.”* Amazon sets their wake-word recognition passing quality “limit” at no more than 3 failed wake-word recognitions within 24 hours. DSP Concepts say that they reduce the failures to 1 in 24 hours.
The one problem they haven’t solved is one that some have declared simply unsolvable: the cocktail-party effect. That is, being able to isolate a single voice out of a number of voices speaking at once. Our brains seem to have an easy time doing that – especially if we’re looking at who’s talking. Fusing video with audio could help there. But even so, we have this knack for isolating a single voice even with our eyes closed, presumably zeroing in on tone and timbre, which differentiate voices. Whether doing so outside our brains is doable, only time will tell.
*To be clear, this isn’t a literal quote from DSP Concepts.
More info:
Sourcing credit:
Paul Beckmann, Founder, CTO, DSP Concepts
Chin Beckmann, co-Founder, CEO, DSP Concepts



What do you think of DSP Concepts’ notions about how to improve speech recognition?