


One way of looking at the Internet of Things (IoT) is to think of it as endowing machines with human characteristics – in particular with respect to our ability to sense the world. To some extent, past efforts have served to sense things that we’re not so good at sensing precisely ourselves. Like temperature or pressure or orientation.
That helps humans, who can then combine their own senses with machine senses for better decisions. But if we further enable our machines to do what we can do, then we can have the machines do without us. (I know… not so good for jobs…). So cameras and microphones will replace our eyes and ears, playing an increasingly important role as our ability to process their data improves.
But it turns out that, at least with respect to audio, putting together an audio system is demographically difficult. That’s because it combines engineers of differing skills, according to DSP Concepts.
On the one hand, you have algorithms. Complex algorithms. Just as the visual arts have benefitted by an explosion in algorithms like computational photography, so the manipulations of sound are becoming particularly sophisticated.
One contributing factor is the use of multiple microphones where one used to do. Taking several streams of sound and massaging them into a single high-quality audio stream is no mean feat. These algorithms are developed by specialists, each algorithm being optimized a particular way and each algorithm bringing something to the party while sacrificing something else.
An algorithm exists to add some characteristic to sound. It might be about filtering out noise, or it could be about rebalancing the highs and lows in a music stream or about adding some particular effect. It’s something that, in particular, music production teams have done for years, with old circuits and new. It’s just that modern techniques are letting us do more.
But then we have to integrate these algorithms into a system. And the folks who do this are generally very different from the folks that build the algorithms. They don’t really know what’s going on in the heart of the algorithms they use; they simply know (or want to know) what effect a particular block has on the audio stream.
It’s not like there’s one best way to process audio, so it’s not like there’s this linear progression of ever-improving circuits with a “best” version at any given time. The right algorithm depends on the nature of the sound, the nature of the recording and playing environments, and the task to be performed with the sound.
And the target tasks have bloomed far beyond what they used to be. Traditional efforts have served the obvious broadcast and music industries. But now we’re talking about voice recognition and the ability of sound in some abstract way to tell us something about what’s going on around us in a sensor. New ground, new algorithms. How is a system designer to proceed?
This is a problem that DSP Concepts is trying to address with their Audio Weaver tool.
Leveraging Audio Consulting
DSP Concepts’s history lies in doing custom consulting work for customers. Through that effort they have developed countless algorithms themselves, hand-optimizing them for a variety of platforms (ARM Cortex M4/M7/A8/A9/A15, ADI Blackfin, ADI SHARC). They’re now taking on the task of productizing this Audio Weaver tool for assembling these algorithms into a system.
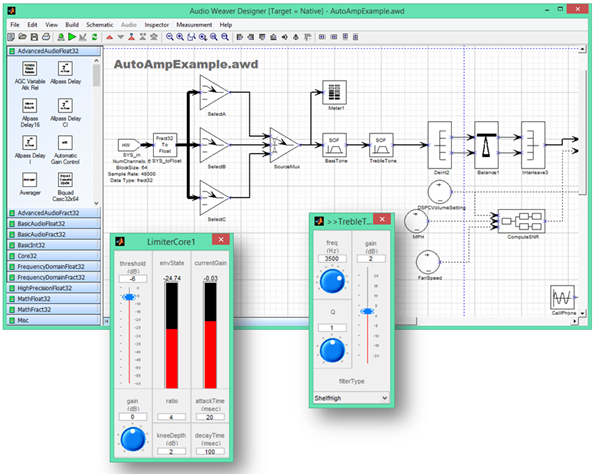
Audio Weaver provides a graphical interface for putting together an audio subsystem. You drag and drop various components – and an algorithm is a component – into a subsystem that will execute on a PC or the target audio platform. This is an area where, according to DSP Concepts, virtual platforms can’t be used – there are too many real-time issues that can’t be captured. So the output must be executed live.
In this particular case, DSP Concepts is providing both their algorithms, which they’ve honed over time, and this tool to pull them together. But their long-term focus is the tool; they’re anticipating an algorithm marketplace that will eventually enable designers to pull in algorithm IP from different sources, comparing to select the best ones.
This comparison process is something that Audio Weaver enables. Let’s say you want to check out the effect of a particular block on the sound. Does it help? Is it worth adding? Or let’s say you have two or more implementations of a particular algorithm, or even two or more algorithmic approaches to the same problem, and you want to compare them to see which works best for this particular platform and task.
Audio Weaver lets you build a system with multiplexers for selecting from a variety of blocks, using checkboxes for two, picklists for more than two. Blocks can also be bypassed or muted. But there’s some nuance in how you would implement those tests. One way might involve static generation of multiple systems according to the selections. If you were doing simple A/B testing, then you’d generate an A system and a B system.
(Image courtesy DSP Concepts)
But how to compare them? In that case, you’d need to load and run A, then load and run B. You’re relying entirely on your memory of how A sounded while B loads and starts. The longer that gap, the more time adds to the distortion that your memory already provides. I suppose you could also have two systems and mute one and then the other, going back and forth, but that would get particularly unwieldy for A/B/C/D… testing.
You might say, “Hey, simple: just record A and then load B and play it and the recording of A at the same time.” Except that then you’ve introduced a whole new set of audio processing to A by virtue of recording and replaying it. So that won’t work.
What you need is to run A and then click a checkbox and immediately hear it replaced by B – back and forth to get a good sense of which is better. Audio Weaver can do that.
It does so by segregating component (or algorithm) code from the overall system configuration. Each code block is typically hand-crafted even at the assembly code level, since they say that compilers mostly don’t do a good enough job.
Each of those components is then a function. Some of these functions may also have variables or parameters for tuning. When instantiating blocks, Audio Weaver creates a data structure for each one containing parametric data and function pointers. When exercising the system, Audio Weaver remains in the picture, and clicking checkboxes or dialing parameters around merely changes the values in the tables or affects which function pointer is used.
This means that you can make changes and tune the system without recompiling or incurring any delays between the configurations being compared. You immediately hear the effect of any change you made.
Audio Weaver also lets you design hierarchically, so you can take an assemblage of components and collect them into a block that can be instantiated multiple times or whose effectiveness can be tested using a checkbox to enable/disable it.
For algorithm and IP developers, it’s also possible to link Audio Weaver up to Matlab, letting Matlab generate filter coefficients and such as a slave to the Audio Weaver.
If your actual hardware platform isn’t ready yet, you can use the PC – as long as the speakers you use and everything downstream of the audio processing output are the same ones you’ll use with the actual target hardware. When generating a system for production, Audio Weaver will no longer be in the picture, but the data structures are still used, enabling system adjustments up to the last minute.
DSP Concepts’ focus is on low-level sound processing. For example, they don’t do voice recognition themselves – they provide the voice recognition tools with sound quality that will make it easier for the voice recognition algorithms, but those algorithms are layered above what Audio Weaver generates.
DSP Concepts appears to be in something of a transition period as it moves from strictly a consulting business to one that has a shrink-wrapped product. For example, there’s no specific press announcement detailing the launch of Audio Weaver – yet, anyway. It has the feel of a “soft opening” with more announcements planned.
But you can go and download a free version of Audio Weaver (there are also paid versions that have more features). If they’re delivering on their promises, then you could save a good chunk of development time.
More info:



Would a tool like Audio Weaver make your audio design life easier? How?