


Dr. Emilio Lizardo/Lord John Whorfin: “May I pass along my congratulations for your great interdimensional breakthrough. I am sure, in the miserable annals of the Earth, you will be duly enshrined.” – The Adventures of Buckaroo Banzai Across the 8th Dimension
My previous CXL article, “Addressing The Memory Guy’s CXL Conundrums,” published in January, discussed some issues about CXL raised by my friend, Jim Handy, The Memory Guy. Handy had published a blog about Compute Express Link (CXL) and wrote about two conundrums he perceives regarding CXL. His two conundrums were:
1. Will More or Less Memory Sell with CXL?
2. Where does CXL Fit in the Memory/Storage Hierarchy?
The article discussed both conundrums, but new information recently surfaced, so we’ll revisit the second conundrum in this article. In his original CXL blog, I wrote:
“Where does CXL memory fit? Handy has long used a very – er – handy graph of the computer memory hierarchy that nicely characterizes all the memories we attach to computers. He customized the graph for my previous article:
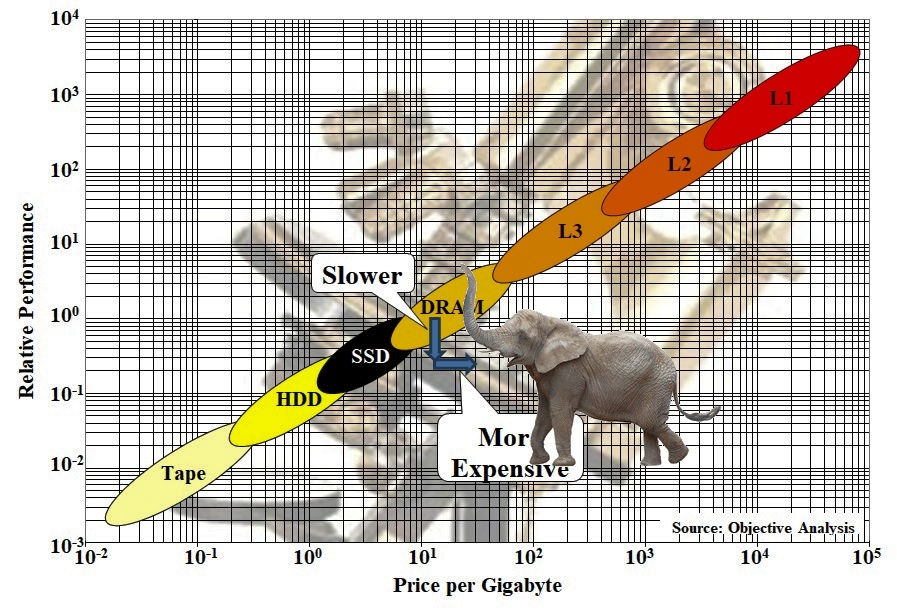
Computer Memory Hierarchy with CXL commentary through animal analogy by Jim Handy, The Memory Guy. Image credit: Objective Analysis
Handy’s graph shows that CXL memory fits between DRAM and SSDs in the memory hierarchy. CXL memory is faster than SSD storage, but it’s also both slower and more expensive than locally attached DRAM, and those characteristics should make CXL memory somewhat unattractive. However, here’s what I wrote in January:
“…although CXL DRAM may have longer latency than local DRAM due to the need for transactions to pass through at least one CXL switch, CXL may also attain higher bandwidth than closely coupled DRAM thanks to those 64 GT/sec CXL channels. It all depends on the CPU, the integrated memory controllers, the CXL memory controllers, the width of the CXL implementation, and the system design. So, The Memory Guy’s graph will need another oval blob for CXL memory, which Handy drew as an elephant for the purposes of this article. (Not too long ago, Handy’s graph had an oval blob for Intel’s Optane memory, positioned between DRAM and SSD, but Intel killed that product and Handy vaporized its blob. So, blobs come and go in Handy’s memory hierarchy, which merely reflects the fluid reality of computer design.)”
Later in the article, I wrote:
“Handy’s blog on the topic suggests that CXL memory will be slower and more expensive than DRAM, so his CXL oval (or elephant in this case) appears beneath and to the right of the localized DRAM oval. If Handy is correct, then there’s no good reason to have CXL memory. Perhaps he is correct. However there’s also the possibility that The Memory Guy’s positioning of that CXL memory elephant/oval is not correct or that his 2D chart doesn’t show all the important considerations for hyperscale data centers. We will need to wait to see which of these alternatives is correct.”
We need wait no longer. Thanks to a booth presentation of an experiment by MemVerge, Micron, and SuperMicro at Nvidia’s GTC conference in March, we now know at least one of those off-the-graph third dimensions where CXL proves its worth.
You’ve likely heard of memory maker Micron and PC/server maker SuperMicro before, but you may not have heard of MemVerge. The company develops enterprise-class software – “Big Memory” software – for big, data-intensive applications running in big computing environments, namely data centers. One such piece of MemVerge software, the Memory Machine, creates a large, unified memory from the tiered memory available to a server processor. This unified memory includes the processor’s locally attached DRAM, persistent memory such as Intel’s discontinued Octane Persistent Memory (see “Optane, We Hardly Knew Yeh”), and other accessible memory, such as a CXL memory pool. Based on the Memory Machine’s data sheet, it seems to me that MemVerge originally developed this software layer for tiered memory systems that included local DRAM and Intel’s Optane Persistent Memory, and that Intel’s discontinuation of its Optane Persistent Memory products has prompted MemVerge to expand the Memory Machine’s tiered memory coverage to include CXL memory pools.
MemVerge generally makes the Memory Machine available through its Memory Machine Cloud, not as a standalone piece of software. However, for the demo experiment at GTC, the Memory Machine was running on a preproduction SuperMicro Petascale server based on an AMD Genoa EPYC 9634 84-core/168-thread CPU and 256Gbytes of locally attached DRAM, with 512Gbytes of DDR4 DRAM installed in Micron CZ120 CXL modules, two 960Gbyte Micron 7450 M2.1 SSDs, and an Nvidia A10 GPU equipped with 24Gbytes of GDDR6 SDRAM.
FlexGen, a high-throughput generative AI engine that runs large language models (LLMs) on “weak” GPUs and limited GPU memory, served as the target application for this experiment, which ran on the experimental server with and without CXL memory pooling as managed by MemVerge’s Memory Machine. This experiment has been contrived so that the LLM’s parameters will not fit in local memory. Without the Memory Machine and CXL memory, the system must spool these model parameters from the SSD. With the CXL memory, the model’s parameters fit in the system’s total memory. The system’s software stack appears in the graphic below.

The software stack for MemVerge’s CXL experiment includes FlexGen, a high-throughput generative AI engine that runs large language models with limited GPU memory, running on an unmodified Linux OS. The MemVerge Memory Machine, when activated, unifies access to the local DRAM and CXL DRAM on a Micron CZ120 CXL module. Image credit: MemVerge
The performance of this system when running an AI inference benchmark with and without the CXL memory and Memory Machine software layer appears in the graphic below.
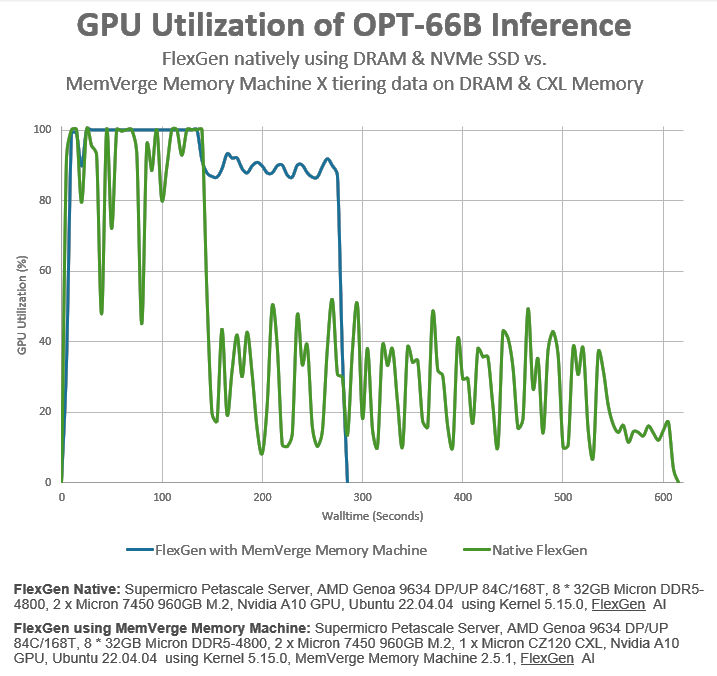
Image credit: MemVerge
Without the additional CXL memory, the inference benchmark finishes in just over 600 seconds – ten minutes. With the CXL memory included through the Memory Machine software layer, the inference benchmark finishes in just under 300 seconds – five minutes. That’s a 2X improvement in system throughput with no modifications to the application program or the Linux OS.
Now, I’ll be the first to point out that this is a contrived experiment. The test has been constrained so that it will not fit in the server processor’s local DRAM or the GPU’s attached DDR6 SDRAM, which forces SSD spooling of the model parameters. The performance doubling requires the addition of 512Gbytes – half a terabyte – of CXL memory. The same performance boost could have been achieved with a larger amount of local server DRAM or more GPU memory. However, that’s not really the point of this experiment.
Attaching more local memory to the server CPU creates “stranded memory,” which is a term coined by the CXL crowd to denote DRAM that’s available to only one CPU. Local memory not being used is “stranded” and is not available for use by other CPUs in the data center. Stranded memory is a resource left fallow. Its cost is not being amortized while it’s stranded. CXL was created, in part, to allow that memory to be shared with other servers, which improves the data center’s cost structure. The same is true for a GPU’s local SDRAM. It’s available only to the GPU, not to other servers.
So, even though this experiment is somewhat contrived, it does demonstrate that third dimension not shown by Jim Handy’s memory hierarchy graph. That graph shows a memory hierarchy for just one CPU, which was never intended as a use case by CXL’s designers. A data center consists of hundreds of thousands or millions of CPUs, where CXL memory is available to many or all of those CPUs. CXL memory is not stranded, and the MemVerge demo experiment caused this added dimension to stand out in bold relief.

SMART Modular recently introduced a family of CXL Add-In Cards (AICs) that accept either four or eight DDR5 DIMMs. Image credit: SMART Modular
The MemVerge experiment demonstrates one way that CXL can be used to accelerate applications. Micron has similar arguments in a White Paper titled “CXL Memory Expansion: A Closer Look on Actual Platform” and a blog titled “Memory lakes: How the landscape of memory is evolving with CXL.”
My friend Handy, The Memory Guy, remains a skeptic. In an email sent to me while writing this article, he wrote:
“Yes, I get your thinking about the third dimension, but CXL DRAM is still expensive, and that makes it attractive only in a certain relatively narrow slice of applications: If you needed a certain performance level, where would you be able to save money by adding CXL? In applications where you can get by with fewer servers by using CXL then it’s a shoo-in. I kind of doubt that this is very common. I fixate on cost/performance.”
For more insight into Handy’s contrarian thinking about CXL, you might be interested in his CXL report. Check that out at The Memory Guy site.
CXL memory is still very new, and servers that incorporate its pooled-memory capabilities are only starting to appear, so data center architects are not well versed in the technology’s use, yet. MemVerge’s experiment is merely a data point, but that data point tells me that there are many more unexplored dimensions to the puzzle of assembling and orchestrating computer supersystems using many data center servers. As CXL becomes more established and better understood, I expect to see more experiments like this.
Dr. Emilio Lizardo/Lord John Whorfin: “Where are we going?”
Red Lectroid chorus: “Planet Ten!”
Dr. Emilio Lizardo/Lord John Whorfin: “When?”
Red Lectroid chorus: “Real soon!”
References
MemVerge Memory Machine data sheet
What is “Stranded Memory?”, The Memory Guy Blog, March 5, 2024



For this “monkeyboy”, one “fud” (Phd) is usually just like another, but I must admit I certainly pay attention when you begin your article by quoting the august Dr. Emilio Lizardo!
Bravo!
Ya gotta “laugh while you can,” Tacitus.
Really? That’s very depressing.
That said, since I’m using a digital input/analog output architecture that mimics an advanced neuromorphic design, the CXL sounds like one possible solution to my memory problems – but then my doctor says that at my age, I just need to get more exercise.
Hi Steven,
Very nice article. I read your previous article also. One possible deployment of disaggregated memory in
a data center rack can be follows –
– PCIe Backplane based rack
– CPU blades in the rack will have only nominal DRAM
– Rack will also have Memory expander blade(s) which will allocate/deallocate memories as requested by the CPU blades
– CXL and PCIe Switch blade, as the Root complex for the system, and to route PCIe and CXL traffic within the rack, and also across multiple racks and to the external world via TOR Ethernet blade
Same memory can be allocated to different CPUs at different times, but at a time to only one CPU. Heterogenous memory can be supported – DDRx, LPDDRx, HBMx, SSD. Or there can be different memory expander blades each with specific type of memory.
Memory expander blade can also have some custom logic, which can operate locally on the data in the expander memory. That way memory expander card can act as a co-processor to the CPU blades.
Cache coherency aspect of CXL is not used in this use case.
The tradeoffs here are the added latency and the added incremental cost of CXL memory over local memory (due to extra memory controllers, memory expansion boards, and PCIe switches). If you don’t mind either of those, then CXL can be used as a memory pool as you suggest.