


Watching the tech industry over the last few decades, it’s easy to come to the conclusion that all of the inventions have come solely through the efforts of single-minded entrepreneurs determined to win, even if it means losing in the attempt. While lots of that has happened, this worldview, just like the notion that the Wild West was won solely by rugged individualists with no help from anyone, is over-romanticized.
In fact, while lots of specific ideas come and go like so many quantum fluctuations, there are efforts on various fronts to forge a strategy and set guidance on how technology can be best brought to a cogent market – a real market, with real competition. These fronts include industry, typically in the form of consortia (so that they don’t run afoul of anti-trust laws) and government.
The government bit gets complicated, since I know that many folks would rather they permanently remove themselves from this picture. “Regulations” tends to be a dirty word – and there are certainly times when it deserves that reputation. But regulations exist for various reasons. Yes, some are due to overzealous regulators solving a non-existent problem. Others are erected by deep-pocketed market incumbents as a way to erect barriers against shallow-pocketed upstarts. And finally, there’s always someone who acts badly, resulting in regulations banning whatever the bad action was and ruining it for all the good players. As full disclosure, I feel that the best regulations those that are just enough to maintain a level playing field to ensure that the best ideas, not the biggest bank balances or the biggest bullies, win.
So this week we’re going to look at efforts by various groups, all of which have industry participation, to establish guidelines for different aspects of technology. Even though they span different domains, I’ve gathered them together because they all have forward-looking policy as a common theme.
A National Strategy – or at Least a Dialog
We start with a conversation that was initiated by Intel, Samsung, and the Informational Technology Industry Council (ITIC) (yes, there will be acronyms) in June of 2016. They worked in partnership with the Semiconductor Industry Association (SIA) and the US Chamber of Commerce Technology Engagement Center (sorry, no acronym) to put out a report.
While they didn’t publish a list of the industry participants, they did note “broad industry engagement” and a wide variety of governmental organizations that were part of the discussion. Quoting: “the Department of Commerce (DOC), Department of Health and Human Services (HHS), Department of Homeland Security (DHS), National Institute of Standards and Technology (NIST), White House Office of Science and Technology Policy (OSTP), National Telecommunications Information Administration (NTIA), and Food and Drug Administration (FDA). Industry and other external participants include … CTIA the Wireless Association, Advanced Medical Technology Association (AdvaMed), World Bank, and Information Technology and Innovation Foundation (ITIF).”
The overall effort was dubbed the “National IoT Strategy Dialogue,” or NISD. Note that this isn’t an official strategy; it’s a dialog(ue). There’s no specific enforcement of any provision, and, really, it’s not about what technology should look like as much as it is about priorities, considerations, and process as this IoT thing evolves.
Specific areas that were called out were security, investment priorities, and the value of public/private partnerships.
- When it comes to security, there are no specific requirements as to how to implement it, but it’s encouraged at multiple levels, and good security should be a requirement for any projects looking for government agency funding.
- Investment priorities are transportation, 5G and other “transformational” technologies, and smart buildings.
- Investment should be directed to public/private partnerships.
- Interestingly, there was no mention of net neutrality anywhere in the document. While the topic tends to focus on our ability to browse freely and access content without artificial deep-pocket barriers, it can also relate to the IoT and any services being delivered over the internet. This struck me as a hole in the document, despite the fact that it’s a divisive issue (surprisingly – you’d think user freedom would be a no-brainer).
There was also much discussion about not going nuts with regulations – in particular, putting them in place only when necessary and only when such an effort wouldn’t duplicate existing regulations – which seems like reasonable guidance. Standards are encouraged – and standards typically arise out of industry, not government. And, despite the fact that this is a US-centric document, federal participants are encouraged to work internationally to make sure that there aren’t ill-considered stumbling blocks as you cross borders.
Guidance for Industrial Data
Next we look at a document released last fall by the Industrial Internet Consortium. It’s their Industrial IoT Analytics Framework (IIAF), and its purpose is to provide guidance as machines increasingly deliver up data that needs to be worked into enterprise data systems as part of the convergence of information technology (IT) and operations technology (OT).
In typical IIC style, they lay out the problems to be solved from four viewpoints: business, usage, functional, and implementation. They then examine big data and related concepts, analysis and modeling, and analytic system considerations.
Part of what’s interesting here is how they define the problems and organize the solutions. They leverage the industrial internet reference architecture (IIRA) functional decomposition of an industrial IoT (IIoT) system into five buckets (and I quote):
- “Control: sensing, communication, execution, motion, and actuation;
- “Operations: provisioning, management, monitoring, diagnostics and optimization;
- “Information: data fusion, transforming, persisting, modeling and analyzing;
- “Application: logic, rules, integration, human interface; and
- “Business: enterprise and human resources, customer relationships, assets, service lifecycle, billing and payment, work planning and scheduling.”
With respect to the analytics, they have two different ways of organizing them into three types. One is:
- Descriptive – that is, it says how something is;
- Predictive – that is, it says how something is likely to be in the future;
- Prescriptive – that is, it says how something ought to be, prescribing action.
The other relates to the response timeframes of different analytics:
- Baseline: these detect anomalies within milliseconds of their occurrence in some piece of equipment;
- Diagnostic: these provide root cause information, typically within minutes of an event; and
- Prognostic: these provide predictions, but often after hours of analysis.
Interestingly, when dealing specifically with the control domain of an IIoT system, they define timeline horizons at three levels that don’t completely overlap with the prior timeframes:
- Machine: real-time control, millisecond response;
- Operations: this is for maintenance, fault detection, and fleet operations as examples, with response in seconds; and
- Planning: this is where the business can learn from the data, with a response time on the order of days or longer.
Then there’s the data taxonomy thing. They define two broad classes of analytics: big data (BD) and artificial intelligence (AI). BD is all about dealing with lots and lots of data, as characterized by the five Vs distinguishing BD from traditional storage and handling (again, quoting):
- “volume: too big,
- “velocity: arrives too fast,
- “variability: changes too fast,
- “veracity: contains too much noise and
- “variety: too diverse.”
They illustrate BD operations using the following figure.
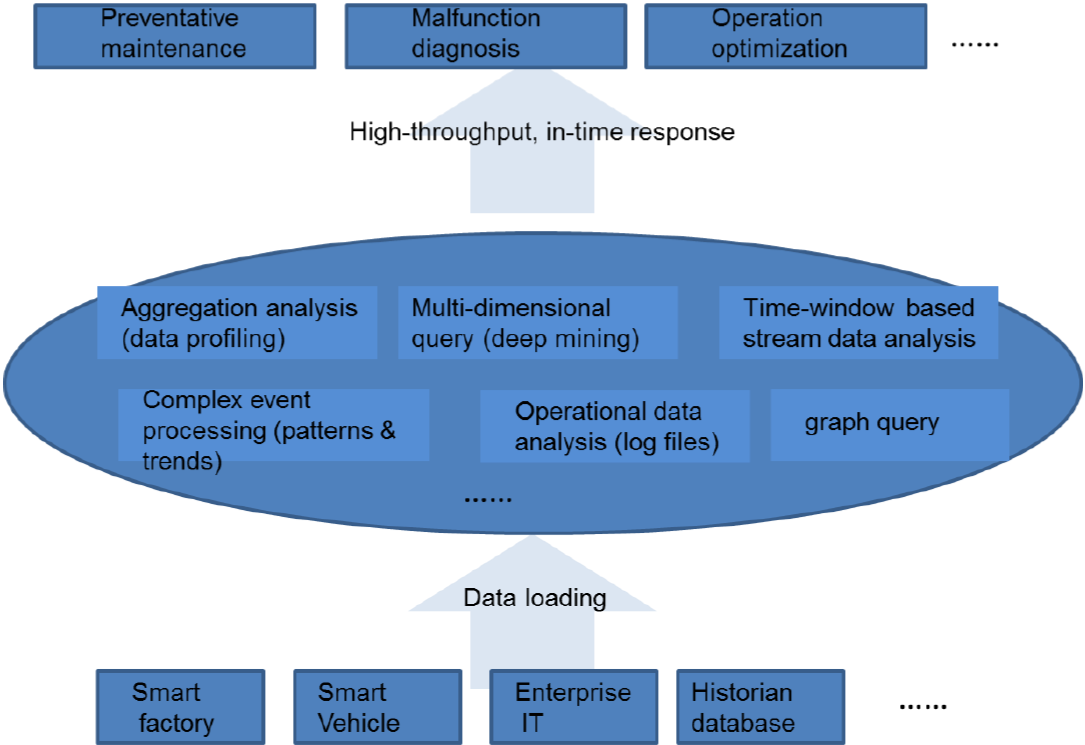
(Click to enlarge; Image courtesy the Industrial Internet Consortium® (IIC™))
They also discuss big-data processing, starting with the well-worn “lambda” architecture. It attempts to solve the problem of doing handling vast amounts of incoming data while still being able to do short-term analysis.
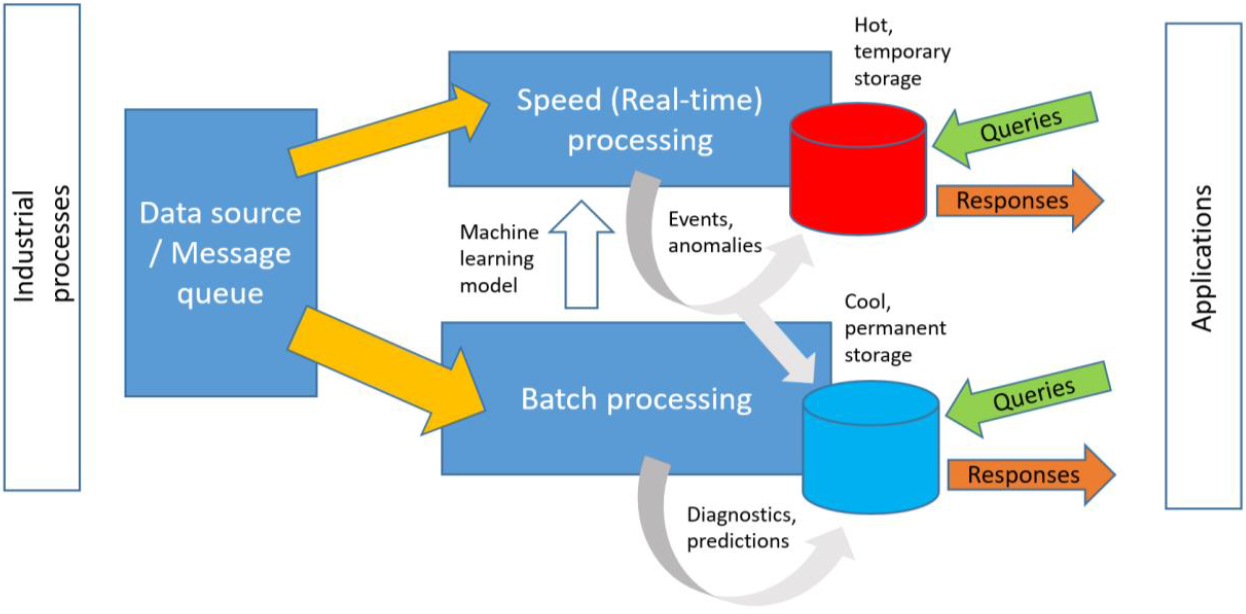
(Click to enlarge; Image courtesy the Industrial Internet Consortium (IIC))
On the ascendant is a modified approach, referred to as the “kappa” architecture. It models processing as separate jobs, where one might use new incoming data while another works on analysis of data that’s already been stored.
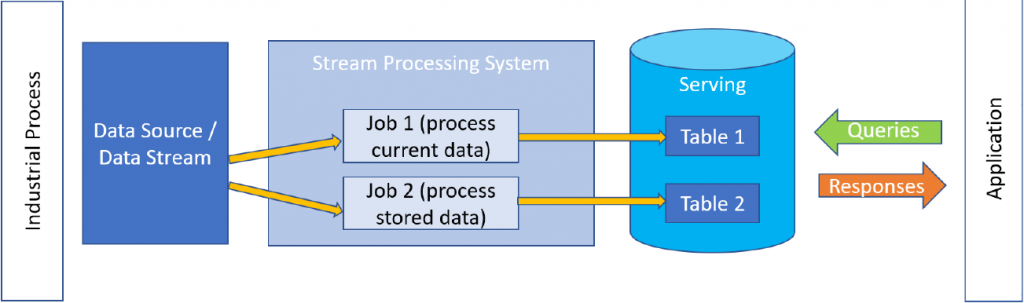
(Click to enlarge; Image courtesy the Industrial Internet Consortium (IIC))
AI, on the other hand, they break up into two separate branches: machine learning (ML) and deep learning (DL). This seems to me to be something of a problematic distinction, since, if I’m not mistaken, “deep learning” refers to neural nets that have more internal layers – which makes them more of a subset of ML, not a separate alternative to it. The document includes neural nets in the ML category, but not CNNs or RNNs, which they place in the DL category.
I sent a question regarding this in to the IIC, and the chairs responded that, “The IIAF considers ML and DL within the context of workflow for developing the models. The IIAF focuses on the similarities and differences, namely the elimination of the feature extraction and reduction step. The IIAF does introduce CNNs and RNNs but does not dive deeply into them. The comments provided can serve as a good discussion point for a future revision.”
They put together a pretty hefty list of different kinds of ML algorithm, which they illustrate in the following figure.
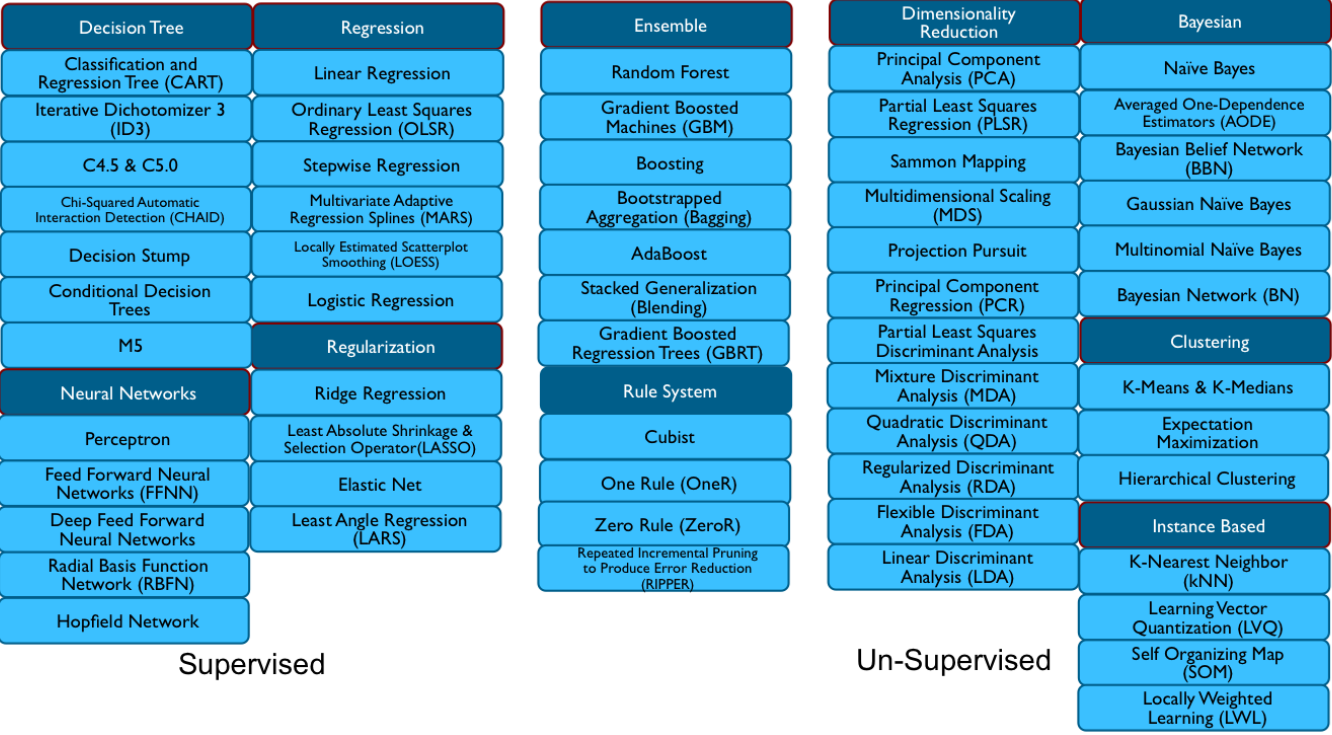
(Click to enlarge; Image courtesy the Industrial Internet Consortium (IIC))
Privacy: I Know What You Had for Breakfast Today
We wind down by looking at privacy. I’ve always found privacy to be somewhat problematic because, for the most part, I’m not aware of any technical solutions that can guarantee to your average citizen that their privacy is being respected (as compared with security, where, in theory, anyway, you can put together a technical solution). That means policy or regulations become part of the solution (if, indeed, there is a solution).
And, full disclosure, I’m a fan of privacy. I know some people roll their eyes at the notion (often because defeating privacy lets them make more money), but I’m not crazy about having my activities tracked and monitored 24/7. Or even 8/5. Or at all.
And it didn’t escape my attention at many past sensor and IoT conferences that many features of devices – indeed, perhaps the only reason for a “smart” device to be connected – was so that some entity can grab all the data (whether you’re aware or not) and then sell it to advertisers. When it comes to the consumer version of the IoT, it was the only concrete value proposition I could discern for many smart devices (even if it wasn’t value to the purchaser). Such devices basically become legal permission to spy on everyone, and that creep factor keeps many people from signing on.
My paranoia was tempered by a discussion with Sahir Sait of Ayla Networks, an early IoT solutions provider. He said that, in their many conversations with customers, the ability to collect personal data was not a priority. The ability to use the connection was all about learning the ways in which their devices were – and weren’t – used so that they could make improvements.
As Mr. Sait suggests, this may be partly because there’s so much other data out there that, at present, there’s not a lot of additional value in consumer devices – especially since roughly half of such devices (by Ayla’s count) aren’t ever connected, leaving a giant hole in the system. Granted, this is highly anecdotal input, but it’s something…
This may, of course, change, but for now, it’s something of a relief. That said, the fact that we as consumers have no control over this stuff is why governments tend to get involved. The US tends to be reluctant to get in the way of anyone’s ability to make money (even by questionable means), but other countries stand up more for consumers.
Europe in particular has their GDPR (General Data Protection Regulation) that applies to any country in the European Union. It places limits on what can be done with personal data. And this becomes a problem for global corporations – especially ones based in the US, which has much less protection. Large companies have been penalized for violating those rules, and Germany is, as we speak, taking issue with Facebook requiring users to register only with their legal names.
Privacy Shield is one mechanism by which companies outside the EU can self-certify that they meet the EU’s personal data requirements (there’s a version for Switzerland too, which isn’t part of the EU, but has personal data regulations).
Designing Privacy In
Part of why we’re discussing privacy in a policy article is because we largely rely on people’s good will not to abuse the reams of data they’re collecting about us. And we all know that, if people can’t be trusted to do the right thing, then someone needs to make enforceable rules if they’re inclined to address the issue.
There is a notion of “Privacy by Design,” however, and, while vague and not particularly enforceable, it does provide some guidelines for data collection that respects privacy. The elements of this concept are (quoting from Wikipedia):
- “Proactive not reactive; Preventative not remedial
- “Privacy as the default setting
- “Privacy embedded into design
- “Full functionality – positive-sum, not zero-sum
- “End-to-end security – full lifecycle protection
- “Visibility and transparency – keep it open
- “Respect for user privacy – keep it user-centric”
And, as it turns out, there are ways to design with privacy in mind. The easy scenario to picture is one where there’s a giant pile of data with your name on it up in the cloud somewhere. Many such piles, actually. And your name is on them because your name is attached to your devices when you on-board them.
The concern here is that anyone mining the data has to actively strip your name off of it in order to use the data anonymously. Even if the company policy is to do that, it relies on individual data analysts to do so faithfully every time, or else it breaks.
But it turns out there’s a different way to do it. Talking to another provider, they said that they use individual micro-services to send data up. When you on-board the device, one micro-service captures that data and puts it in one pile. When you send up usage data, another micro-service (or maybe multiple ones) are used, and that data ends up in another pile. Significantly, that second pile doesn’t have your name on it because your name is in the first pile.
Now… the second pile will have a device ID on it, and a data analyst can join the two piles by relating the device ID to your name. But here’s the thing: in the first one-big-ol’-pile scenario, your name is there unless someone strips it; in this second scenario, your name isn’t with all the other data unless someone specifically arranges for it to be there. So it’s more private by default. The second data pile isn’t completely anonymous, since it can be traced back to you with some work, but it’s one step removed: it’s called pseudonymous.
So that completes our run-through of various policy- and regulation-related topics. You can find more specifics in the links below.
More info:
National IoT Strategy Dialogue
Industrial IoT Analytics Framework



What do you think of these ideas regarding structure for the IoT?