


I’m having “one of those days.” During a recent chat with someone who has a lot to answer for, I was informed that IREE is the execution layer for MILR and that I can think of MILR as a newer version of LLVM. Now I know what I sound like when I’m talking to my family and friends. Also, my head hurts.
This all came about when I was chatting with John Weil, who (a) is Vice President and General Manager for the IoT and Edge AI Processor Business at Synaptics and (b) needs a larger-than-average business card to carry his title. The purpose of our conversation was for John to bring me up to speed on a new family of AI-native processors that feature a neural processing unit (NPU) designed in collaboration with Google Research.
As a reminder, although most of us tend to think of real-world AI deployments as being a relatively recent occurrence, Synaptics has been playing in this arena since the late 1980s (you can read more about this in my columns Reimagining How Humans Engage with Machines and Data and BYOD or BYOM to Synaptics’ AI-Native Edge Compute Party).
There’s currently an exponentially increasing trend to migrate AI from the cloud to the IoT Edge, which is where the “internet rubber” meets the “real-world road.” Synaptics plays on the left-hand side of the image below (roughly the area indicated by the dotted line on the bottom left-hand side).
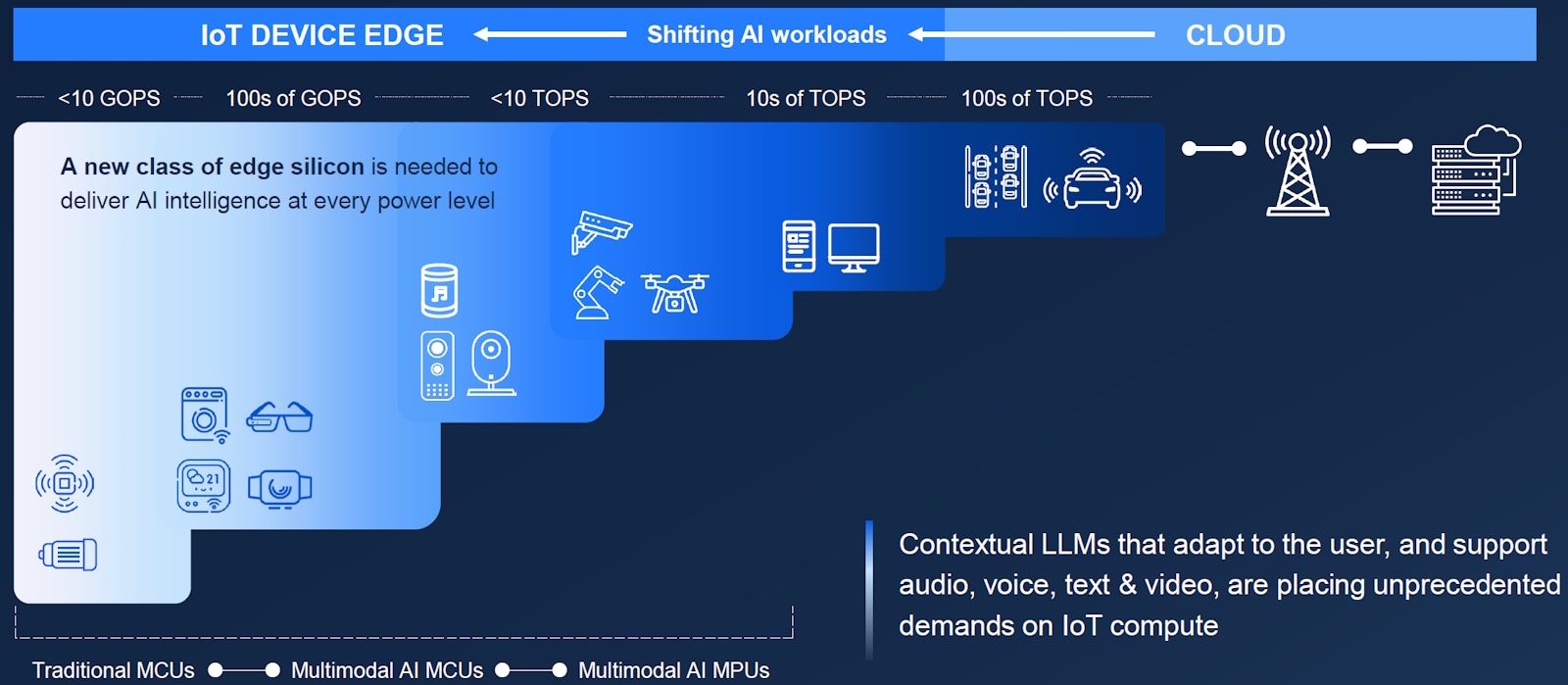
AI’s next frontier—the device edge (Source: Synaptics)
Remembering that MCU and MPU stand for microcontroller unit and microprocessor unit, respectively, Synaptics has evolved from building traditional embedded processors (MCU-class devices) to multimedia-capable application processors (AP-class devices), to multimodal AI-native MCUs, and now to multimodal AI-native MPUs that integrate machine learning accelerators alongside CPU, GPU, and NPU subsystems.
The latest and greatest of these devices is embodied in the form of the Astra SL2600 Series of multimodal Edge AI processors, which were formally announced yesterday (i.e., the day before this column was published). These processors are purpose-built for the next wave of smart appliances, home and factory automation equipment, charging infrastructure, healthcare devices, retail point-of-sale (POS) terminals and scanners, autonomous robotic systems, unmanned air vehicles (UAVs), casual gaming devices, and more.
The Astra SL2610 product line comprises five families—the SL2611, SL2613, SL2615, SL2617, and SL2619—which are designed to address the needs of a wide range of solutions, from battery-powered and passively cooled devices (like thermostats), to coffee machines, cookers, and washing machines, all the way up to high-performance industrial vision systems. These processors deliver hallmark power efficiency and seamless integration with Synaptics Veros Connectivity—across Wi-Fi 6/6E/7, BT/BLE, Thread, and UWB—providing a unified developer experience that accelerates time-to-market.
One point of interest is the price. As John says, if someone is at Home Depot looking at two cooking ranges A and B, with the only difference being that option A is AI-enabled, many people will opt for B because A is (typically) significantly more expensive. By comparison, powering option A with an Astra SL2610 AI-native device allows the creator of the cookers to maintain cost parity.
Something else that’s well worth considering is that all these devices are pin-to-pin compatible, thereby providing the ability to future-proof one’s designs. There are multiple aspects to this. The obvious aspect is that a future incarnation of a product may require more processing power; in such cases, the ability to simply plug in a higher-performance processor offers a clear advantage. Less obvious is the fact that the designers of the original incarnation of the product may not be 100% certain as to just how much processing power they need, so they tend to over-engineer (“just in case”). In this case, the advantage of having pin compatibility across the entire range is that it’s possible to migrate to a lower-performing (and lower-cost) processor once the first pass of the design is complete.
The diagram below encompasses the entire SL2610 family. The dotted lines indicate optional elements that may not be present in all family members. On the CPU side, we have one or two 64-bit Arm Cortex-A55 processors augmented with Arm NEON, which is Arm’s SIMD (Single Instruction, Multiple Data) architecture extension—a built-in vector processing engine that enables the CPU to perform the same operation on multiple data elements in parallel.
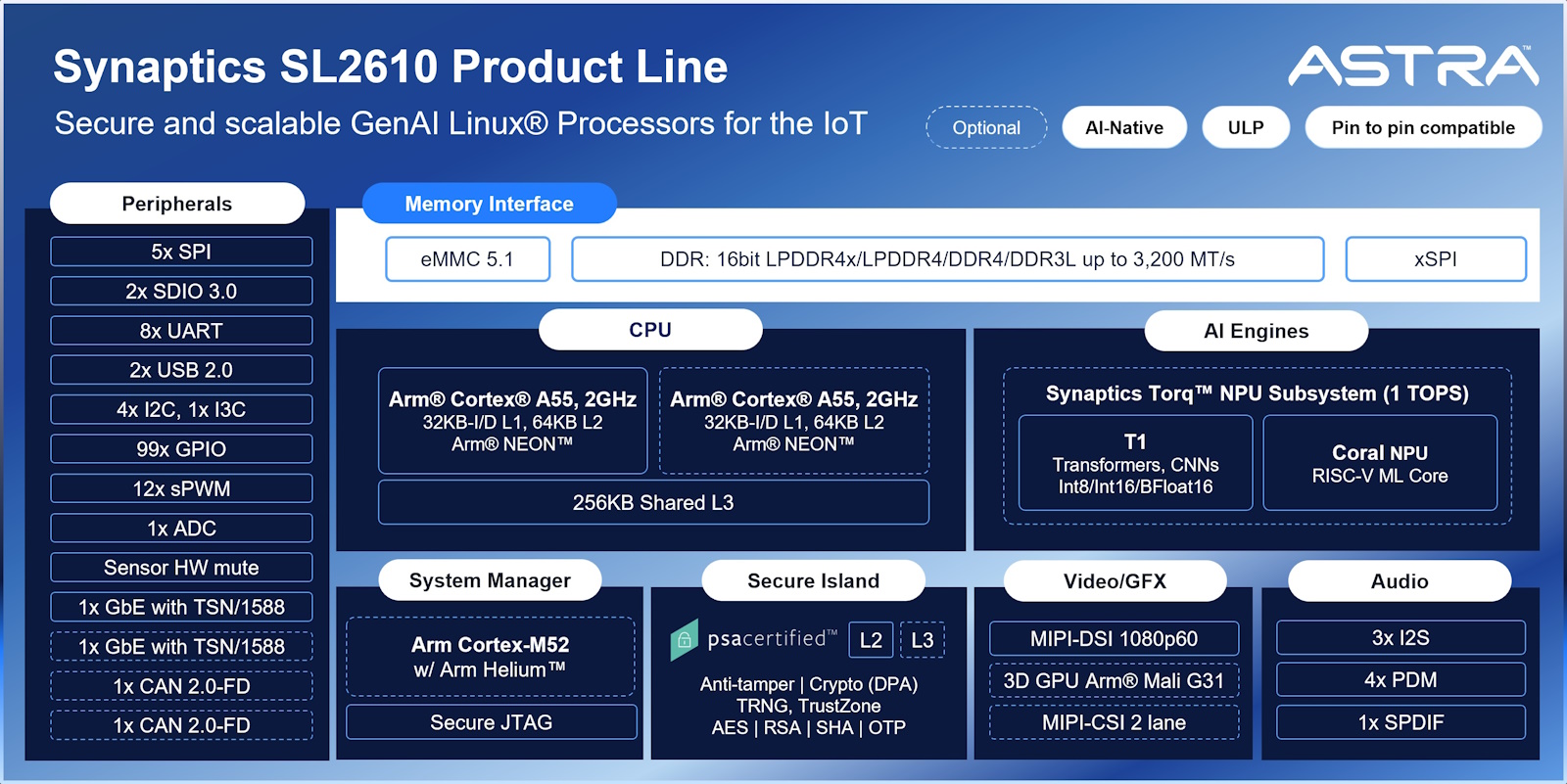
Summary of the Astra SL2610 product line (Source: Synaptics)
Now consider the system manager, which is implemented using a 32-bit Arm Cortex-M52 processor augmented with Arm Helium (also known as M-Profile Vector Extension, or MVE), which is the SIMD/vector-processing engine for Arm’s Cortex-M microcontrollers. The M52 occupies the “sweet spot”, combining the low cost and low power of the M33 with the performance and capability of the M55. Meanwhile, Helium is conceptually similar to NEON but redesigned from the ground up for the microcontroller (M-profile) world—offering lower power, a smaller footprint, and deterministic timing.
The SL2610 can operate entirely from its M52 microcontroller core, dramatically reducing power consumption. The system can boot directly into MCU mode, so the Arm A55 application cores stay powered down. The M-core handles housekeeping, real-time I/O, display refreshes, motor/PWM control, and other always-on tasks at sub-100mW levels. When higher-level Linux services or AI inference are needed, the M-core can wake and orchestrate the A55s (and the rest of the system) via secure wake/power-gating and interconnects, giving designers a straightforward low-power baseline plus deterministic real-time control without sacrificing the option to scale up to full application-processor performance.
Speaking of security, this is treated as a first-class design goal in the SL2610 family, not an afterthought. The integrated Secure Island provides a fully isolated execution environment with hardware root of trust (RoT), PSA Certified Level 2 and Level 3 support, and robust protection against both software and physical attacks. It includes anti-tamper circuitry, a true random number generator (TRNG), and hardware acceleration for AES, RSA, and SHA algorithms. The subsystem also supports DPA-resistant cryptography, Arm TrustZone, and one-time programmable (OTP) key storage. Together, these features ensure that sensitive credentials, secure boot, and lifecycle management are protected from cloning, tampering, and side-channel attacks—critical requirements for connected IoT and industrial systems.
To meet the demand for rich, modern user interfaces at the edge, Synaptics has equipped the SL2610 with a more than capable graphics and video subsystem. At its heart is an Arm Mali-G31 GPU, a compact and power-efficient 3D graphics engine that delivers smooth rendering for Linux- and Android-class UIs. Display and camera interfaces are supported via MIPI-DSI (up to 1080p60) and MIPI-CSI (two lanes), enabling applications such as smart displays, control panels, and vision-based IoT systems. The inclusion of a full GPU, rather than a simpler 2D engine, underscores Synaptics’s focus on design usability—developers can create fluid, animated UIs and overlay real-time graphics on video streams without the need for external accelerators.
Additionally, the SL2610’s audio subsystem leverages Synaptics’s long heritage in voice, sound, and acoustic processing. It features multiple digital audio interfaces—three I²S ports, four PDM microphone inputs, and one SPDIF output—allowing flexible connection to speakers, amplifiers, and multi-mic arrays. With low-latency paths and integrated signal processing, the platform can perform tasks such as beamforming, noise suppression, and wake-word detection entirely on-device. This makes the SL2610 ideal for smart speakers, voice assistants, and industrial control systems where natural-speech interaction and high-quality playback are key differentiators.
Having said all of this, I must say that the real magic is in Synaptic’s Torq NPU subsystem. This provides 1 TOPS (tera operations per second), meaning it can sustain roughly one trillion AI math operations per second, thereby giving it the punch of a much larger system while staying within a low-power, embedded SoC footprint.
Now, this is where things get a bit tricky, so let’s see how well I do explaining everything. The Synaptics Torq NPU subsystem is a heterogeneous AI subsystem developed in collaboration with Google Research. It combines Synaptics’s own NPU IP (the “T1”) with components derived from Google’s open-source Coral NPU project.
The Coral NPU RTL provides a baseline. Synaptics integrates and extends this with its own proprietary IP, architectural modifications, and dedicated memory and transformer-friendly compute blocks. To put this another way, the diagram above shows both “T1” and “Google Coral NPU” because Synaptics wants to credit Google for its research partnership and the open-source roots. In reality, the T1 is Synaptics’s enhanced implementation of the Coral NPU, not a separate engine per se. The “Google Coral NPU” block shown in the diagram represents the research lineage and open IP foundation, while the T1 represents Synaptics’s production-grade, co-developed version of that architecture.
The easiest way to wrap one’s brain around this is to say that Google Coral NPU is the open-source reference design, while Synaptics Torq T1 is a customized, production-ready derivative of Coral integrated into the SL2610 SoC.
What about the references to IREE, MILR, and LLVM with which we started this column? Well, take a deep breath (I’ll tell you when you can breathe out again):
- LLVM (Low-Level Virtual Machine) refers to the industry-standard compiler infrastructure used by Clang, Rust, Swift, and countless others. It provides an intermediate representation (IR) in the form of a low-level, typed assembly-like language for optimizations, backends that target specific CPUs or ISAs (x86, ARM, RISC-V, etc.), and optimization passes that address constant folding, loop unrolling, vectorization, etc. Think of LLVM as the universal back end that turns generic code into executable instructions for actual processors.
- MLIR (Multi-Level Intermediate Representation) was originally developed by Google to extend LLVM’s ideas upward into the machine-learning domain. Instead of one flat IR, MLIR supports multiple levels of abstraction and multiple dialects (e.g., Tensor dialect, Linalg dialect, GPU dialect, etc.). It allows new hardware (like NPUs, DSPs, or accelerators) to define their own dialects and transformation rules. In other words, MLIR is to LLVM as the combination of AI and heterogeneous computing is to traditional computing.
- IREE (Intermediate Representation Execution Environment) is an open-source project from Google built on top of MLIR. It’s designed to compile and run machine-learning models anywhere—CPU, GPU, or custom accelerators—with minimal runtime overhead. It takes MLIR graphs and compiles them into highly optimized VM bytecode or native executables, provides a runtime to execute them efficiently on the target device, and supports backends for Vulkan, Metal, CUDA, and custom NPUs. Think of IREE as a portable runtime that uses MLIR to target many types of hardware.
And people wonder why I drink! (OK, you can breathe out again.)
As always, writing this column has caused a cascade of thoughts to reverberate around my poor old noggin. In my previous column, Polish Logic Meets Silicon Magic, for example, I introduced the GenioSOM-700 System-on-Module (SOM) from the guys and gals at Grinn. It seems to me that the SL2610 would be perfect for one of these SOMs. In another column from a couple of weeks ago, Agentic AI Prevents Costly Machine Downtime in Factories and Semiconductor Fabs, I introduced Via Connect, Via Copilot, and Via Control from the chaps and chapesses at Via Automation. I can easily envision the SL2610 playing numerous roles in smart factories, all of which could be orchestrated by Via Automation’s solutions.
I don’t know about you, but my head is buzzing with ideas. What do you think about all of this? Do you have any thoughts you’d care to share with the rest of us?


