


At this summer’s DAC conference, Mentor had a couple of artificial intelligence (AI)-related announcements. One of them concerned their own use of AI for physical chip verification, which we have already covered. The other dealt with tools and blocks for use by engineers designing AI architectures, and that’s what we’re going to look at today.
Before we get into the meat of the announcement, however, there are some AI-related notions that we should probably clarify first, since I, at the very least, have found myself needing to separate similar-sounding-but-different concepts to keep from tying my own personal neural nets into neural knots.
3 Stages of a Neural Network
The ultimate job of a neural net is to make inferences about something. But there are several steps required to get to that point, and you may not have to do each of them from scratch. In fact, you probably don’t want to.
The first is the creation of a neural-network architecture. Yeah, you probably know that you have to train a model, but before you can do that, you need a network architecture on which to do the training. This is a lot of work – one that universities and other research-oriented organizations tend to do. Commercial efforts often leverage architectures that have been proven effective already. You may hear them referred to by names like AlexNet or YOLO.
But an architecture, while essential, isn’t a model. The model is the next step: you train an architecture for a specific task. In the ideal case, you can think of this most simply as putting weights on the architecture that you’re using. So a model equals an architecture with assigned weights.
In reality, the training process involves more than just coming up with weights. You may want to simplify the architecture by pruning some of the nodes to reduce the size of the model. So the chosen architecture tends to be merely the starting point; the optimization of a trained model may make changes to that architecture, after which you may need to retrain the modified network.
Finally, you need to implement the trained network on the hardware that you will use for the final inference engine. This is the hardware that will execute the trained model. For that, you need some underlying hardware architecture that will be effective at that inference task.
The hardware architecture is independent of the model, and you’ll probably need to further optimize the model to run on the chosen hardware. One of the big steps here is quantization, since the original models tend to use real numbers – something that many inference architectures can’t do because it’s too expensive. Instead, they use integer (or even binary) numbers for weights, meaning yet more optimization passes in the training process.
Hardware choices include generic options like CPUs, DSPs, GPUs, and FPGAs. But, for FPGAs in particular, there may be pre-designed architectures that work well for a specific neural-net architecture. For example, there is one named Eyeriss that can be used for vision applications. And this is where it’s easy to get confused. As we’ll see, it’s distinct from the network architecture, so, for instance, you might implement the YOLO network architecture on the Eyeriss hardware architecture. Yeah, I need a drink too.
So architecture affects training and hardware affects training, which can make it hard to keep the three concepts – neural net architecture, trained model, and underlying inference hardware – separate in your mind. But doing so will help us (or at least me) to understand the different parts of the Mentor announcement (and others).
There are a few other concepts that get tossed around within AI circles that may be confusing to those of us looking in from the outside (and, based on my own Googling, I’m not the only one with these questions).
A deep-learning network architecture consists of some number of layers. That there are more than just the input and output layers is what defines a deep neural network: it also has inner “hidden” layers. So one parameter that characterizes a particular network is the number of layers.
Each layer takes some inputs and generates outputs that go to the next layer. Of course, with the first layer, the input comes from some sensor or other data source. The output of that and every other layer is referred to as the activation, since desired features will achieve a high or low level of activation in the layer. This is also referred to as a feature map, or fmap, as far as I can tell. Because the activations generated by one layer will feed the next layer, it’s easy to think of activations as the inputs to a layer, which they pretty much are – except for the very first layer.
So each layer has inputs (activations in most cases) as well as weights. These make up all of that data that gets moved around – the activations going from one layer to another (often via memory) and the weights coming from memory as a layer is executed.
The thing is, however, that, at least with CNNs (others too?), the number of nodes can grow exponentially as you add layers to a network. And that can get out of hand really quickly. So, to deal with that, pooling layers are used between convolutional layers to reduce the amount of data as you move from one neural processing layer to another.
Which brings us to the final notion here: fusing. Depending on the hardware architecture, it’s likely that only one layer will be “resident” in the execution engine at a time. Heck, if you’re using a CPU (usually not recommended), you may have only one node, or a portion of a node, resident. This gives rise to the huge data-movement burden due to all of those weights and activations that we talked about.
So one option for the implementation (or hardware) architecture (not the neural-net architecture) is to fuse layers – that is, to bring several layers up at the same time so that the data can flow directly from one layer to another without taking a vacation in memory between layers. If the hardware supports this, then you can save a lot of data thrash in the process.
Tools and Blocks
So <deep breath> with all of that under our belts, let’s look at what Mentor announced. There are two dimensions to their announcement. The first is tool-oriented, intended for hardware architectures being implemented in FPGAs or ASICs. It involves their Catapult tool for converting C/C++ into hardware. So you can take a C++ definition of your network and model and reduce it into hardware.
If you’re scratching your head over the fact that Mentor is offering the Catapult tool again, um… yeah. If you haven’t been paying attention <looks guilty>, you might have missed the latest phase of this history. Mentor originally developed Catapult, then sold it to Calypto (while working collaboratively with them), and then, more recently bought Calypto. So Catapult is back in the Mentor fold again.
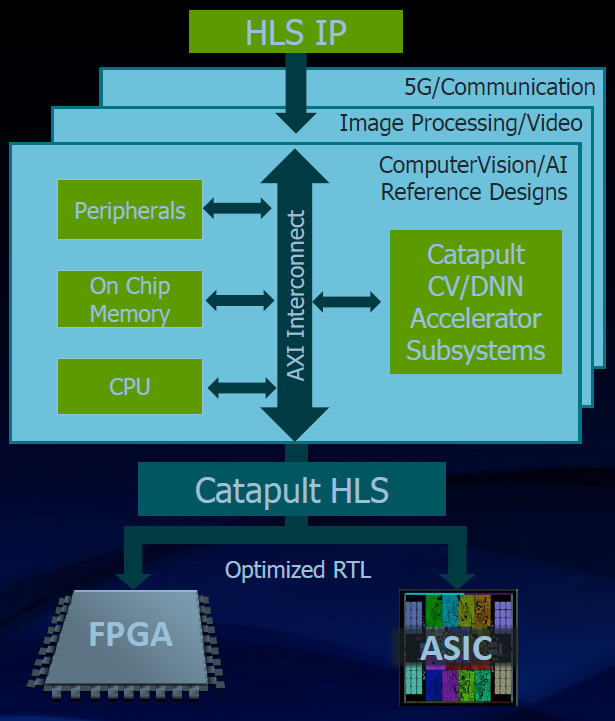
(Image courtesy Mentor, a Siemens business)
The second aspect of their announcement involves toolkits consisting of four different architectural blocks, two of which are explicitly neural in nature. The first two are a conventional (non-neural) edge detection block (using Histogram of Oriented Gradients, or HOG algorithms) and a 2D convolution reconfigurable processing-element (PE) array (which can implement edge detection as well).
Then there are two neural-net options with different levels of lock-down. Both are 9-layer 4D CNNs for vision. The first uses a fused architecture. You can change the weights to train and optimize it for a specific task, but you can’t change the structure of the network itself. The other is implemented on a reconfigurable Eyeriss PE array that can be used more generally for a variety of neural network architectures.
As an example of the neural-net vs. hardware architecture thing, they’ve implemented the YOLOv2 network on their Eyeriss hardware using a Xilinx FPGA. “YOLO” stands for “You Only Look Once” – it’s an approach to image processing that claims to be faster and use lower power by analyzing an entire image at once rather than pieces at a time. This is why we started this article by separating out the neural-net and hardware notions.
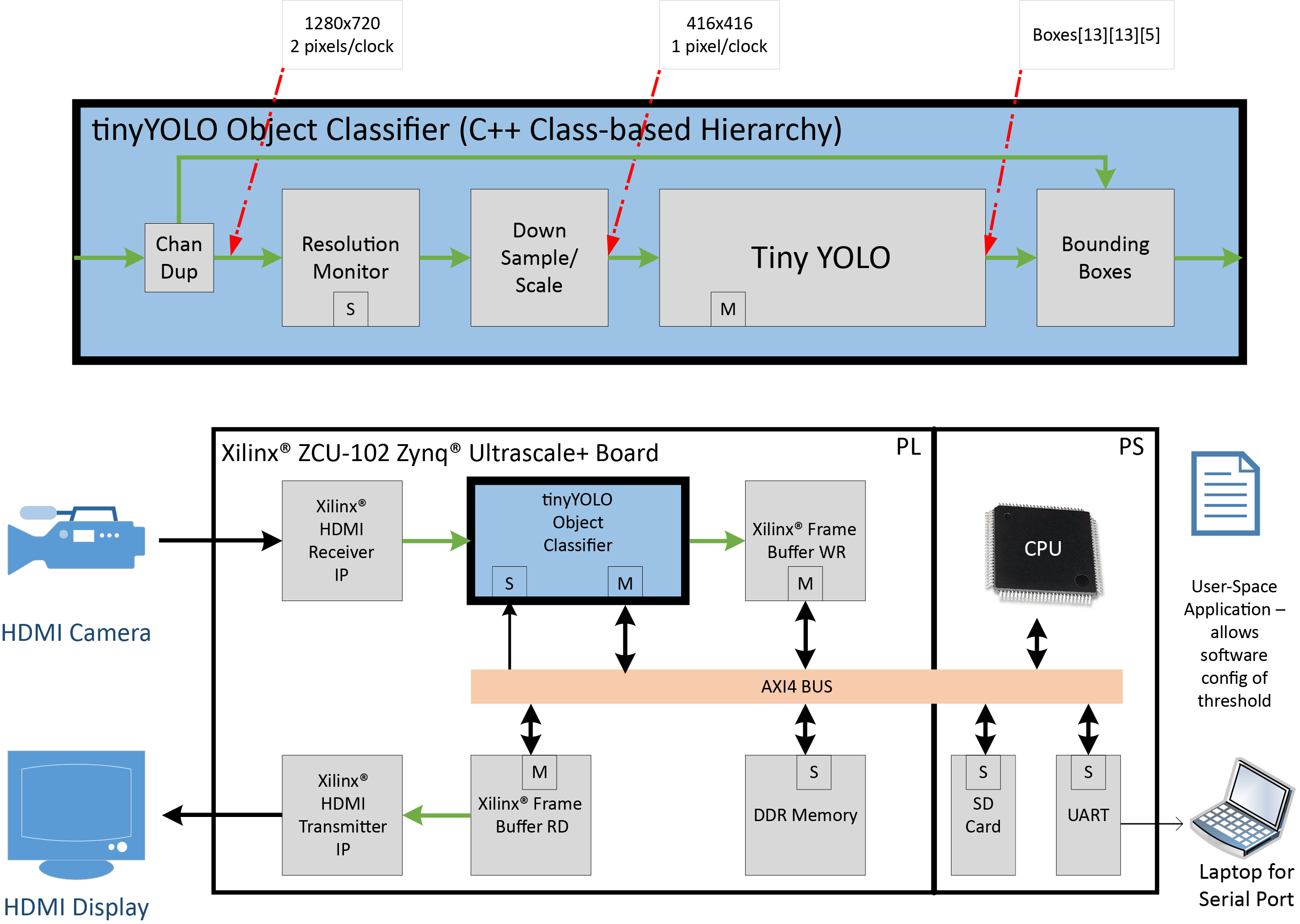
(Click to enlarge; image courtesy Mentor, a Siemens business)
We’ll continue to look at AI options (and notions) as developments continue. That’s likely to happen for a long time…
More info:
AI Accelerator Ecosystem: An Overview
Sourcing credit:
Ellie Burns, Director of Marketing, Calypto Systems Division, Mentor



What do you think of Mentor’s tools and kits for machine-learning designs?