


I remember as a kid being constantly admonished by my mother to “Remember to use your indoor voice.” I also remember feeling quite aggrieved because whatever news I wished to impart was of great import (obviously, otherwise I wouldn’t have wanted to divulge it in the first place), and—being so important—it deserved to be imparted at high volume to a wide audience.
Unfortunately, this was one of many topics on which my mother and I didn’t see eye-to-eye, which wasn’t surprising because, in those days of yore, she was much taller than your humble narrator (she also had a way of looking at you that made your knees go wobbly—she still has that ability, now I come to think about it).
Of course, person-to-person communication was all we had in those far-off times. The thought of being able to talk to a machine, and to have that machine understand you and respond to your commands, was both figuratively and literally the stuff of science fiction.
And yet, here we are. When I wake up in the morning, once I’ve commanded my Alexa-based Sandman Clock (I was one of their first supporters on Kickstarter) to cease its incessant warbling, I next instruct the main Alexa to “Turn Daddy’s Light On” (our cats, Coconut and Little Drummer Boy know me as “Daddy”).
As an aside, Little Drummer Boy’s moniker is something of a misnomer because he’s a humongous Maine Coon, which is one of the oldest natural breeds in North America. The Wikipedia gives adult Maine Coon males a weight range of 13 to 18 pounds and a nose-to-tail length range of 19 to 40 inches. All I can say is that whoever wrote this entry fell far short of the mark. I wouldn’t be surprised to discover that Drummer was closer to 40 pounds (or more) and his nose-to-tail flopped-out length almost spans our King-size bed (now you have me wondering just how long he is—I’ll have to try measuring him tonight… but only if he’s in a good mood).
Suffice it to say that, in addition to “Mommy’s Light” and “Daddy’s Light,” the third Alexa-controlled illumination in our bedroom responds to the name of “Drummer’s Light.” Furthermore, I don’t know how she did this, but my wife (Gina the Gorgeous) has our Alexa set up such that, when you ask it a question or issue it a command, she starts and finishes by meowing like a cat in a very realistic fashion (by “she” I mean Alexa, not Gina), which causes Coco and Drummer’s ears to prick up and for them to stare at each other suspiciously before returning to their customary comatose state.
But we digress… I’ve talked about the folks at XMOS on previous occasions (see One Step Closer to Voice-Controlled Everything and Next-Gen Voice Interfaces for Smart Things and Loquacious Folks). As you may recall, they have a rather unique processor architecture called XCORE. The third-generation flavor of this architecture is called XCORE.ai (as I discussed in Using RISC-V to Define SoCs in Software, the forthcoming fourth generation will be RISC-V compatible). These devices are of use wherever applications demand a combination of multi-core compute, DSP, edge AI, control, and lots of general-purpose input/output (GPIO) in a single, powerful platform. Example applications include automotive, industrial, medical, manufacturing, home automation… the list goes on.
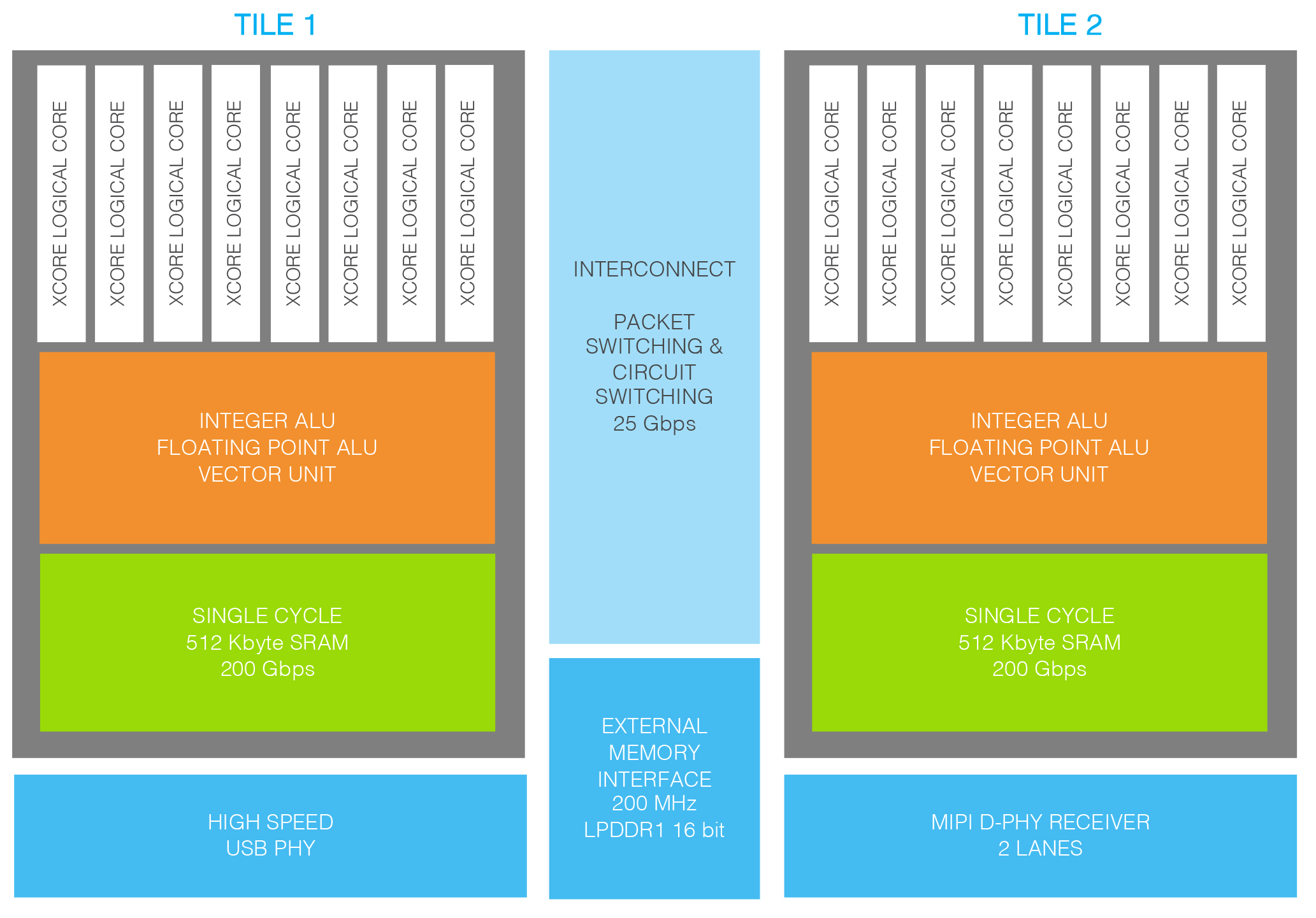
XCORE.ai architecture (Source: XMOS)
As we see, the XCORE.ai chip has two tiles, each boasting a scalar, floating-point (FP), vector, control and communications pipelined processor. Each tile has its own local, tightly coupled memory (not cache) along with eight hardware threads and 64 GPIOs. The tiles can communicate with each other by means of a high-performance switching fabric.
The threads do not involve context switching in the traditional sense. These are hardware threads where each has its own register file, maintains its own state, and has its own access to the memory with guaranteed characteristics. Essentially, each thread has everything it needs to run autonomously; it just happens to be sharing the processing pipeline, but the way it shares this pipeline is entirely deterministic.
As I wrote in one of my earlier columns: “The XCORE architecture delivers, in hardware, many of the elements that are usually seen in a real-time operating system (RTOS). This includes the task scheduler, timers, I/O operations, and channel communication. By eliminating sources of timing uncertainty (interrupts, caches, buses, and other shared resources), XCORE devices can provide deterministic and predictable performance for many applications. A task can typically respond in nanoseconds to events such as external I/O or timers. This makes it possible to program XCORE devices to perform hard real-time tasks that would otherwise require dedicated hardware.”
One of the tasks for which XCORE.ai devices excel is that of automatic speech recognition (ASR), which refers to the technology that allows humans to talk to computers. Actually, that’s not strictly true because humans have been able to talk to (often swear at) computers since their inception. The difference is that ASR technology allows the computers to hear and understand what their humans are saying and (if they feel like it) respond accordingly.
In the past, the guys and gals at XMOS have provided high-performance standard products as turnkey solutions. However, while convenient, this didn’t provide customers with any flexibility when it came to changing parts of the voice processing pipeline or adding their own AI model. To address this, the chaps and chapesses at XMOS recently released their XCORE-VOICE platform.
XCORE-VOICE provides the same high-performance algorithms as the existing turnkey solutions, while allowing the end customer to use or replace any portion of the far-field voice pipeline (e.g., echo cancellation, interference cancelling, noise suppression), customize the local commands (e.g., “Dim the lights,” “Fan speed up,” “Channel down”), and use it in the operation of any smart device, such as fans, lights, appliances, or hubs, to name but a few.
The key point here is that, as opposed to simply “cleaning up” the voice signal and passing it up to the cloud (which you can still do if you want), XCORE-VOICE allows you to run a local AI model that supports wake-word capability and local offline command recognition. Consider the XK-VOICE-L71 Voice Reference Design Evaluation Kit, for example.

XK-VOICE-L71 Voice Reference Design Evaluation Kit (Source: XMOS)
This kit includes several example reference designs for a great out-of-the-box experience. One of these reference designs features a local AI model delivering local command recognition, thereby minimizing the need for the cloud, enabling a better user experience through lower latency and enhanced privacy, and offering savings in cost and power requirements in product designs. Users can swap out this AI model for alternative third-party models as required.
As someone at XMOS wrote in their press release: “This has the potential to unleash a new era of voice-based user experience for the next generation of smart electronics.” Far be it from me to disagree. How about you? Do you have any thoughts you’d care to share?



2 thoughts on “Indoor Voice or XCORE-VOICE?”