


It’s funny how, the older you get, things seem to increasingly circle around. You start off thinking you are heading in a new direction, and then you suddenly find yourself back where you started. I don’t know about you, but just re-reading the previous sentence reminds me of the lyrics to Time by Pink Floyd — the part that goes, “And you run, and you run to catch up with the sun but it’s sinking, racing around to come up behind you again. The sun is the same in a relative way but you’re older, shorter of breath and one day closer to death.” Wow! That sounds like a bit of a downer, doesn’t it? But I’m really feeling quite sanguine — honest!
As I’ve mentioned on previous occasions, my first position after I graduated university in 1980 was as a member of a team designing central processing units (CPUs) for mainframe computers. A little more than a year after I started, two of my managers left to form their own company called Cirrus Designs, and it wasn’t long before they asked a few of the chaps from the old team, including yours truly, to join them.
Although Cirrus Designs started off as a small company (I was the sixth person on the payroll), we covered a lot of ground in the nine years I was with them, at which time I was made an offer I couldn’t refuse from another company, thereby ending up with my moving to America in 1990. We started off writing test programs for printed circuit boards (PCBs) designed by other companies. After a couple of years, we also began to develop our own RISC-based hardware accelerator. The idea here was for a “box” that sat next to your main Unix computer. The Unix machine remained in charge of the operating system and file management and suchlike, but it handed the execution of the applications over to the accelerator. Since you could see anywhere from 2X to 10X speed-up depending on the task, this was pretty significant, let me tell you.
Another project we worked on with our sister company, Cirrus Computers (which was famous for developing the HiLo and System HiLo digital logic simulators), was a hardware emulator whose name I forget. In this case, the system accepted a netlist of your design — which could be anything from an application-specific silicon chip (ASIC) to a PCB — and created an internal representation that was functionally equivalent to the final product. Using the same stimulus (waveforms) as the System HiLo logic simulator, you could use the emulator to debug the functionality of your design before committing to a real-world implementation. Although there were already humongous (in terms of both size and cost) emulators on the market, ours was intended to be a much more affordable desktop system.
I must admit that I drifted away from emulation in the 1990s, but I do remember meeting up with Lauro Rizzatti at a Design Automation Conference (DAC) sometime in the early 2000s. At that time, Lauro was the USA General Manager and World-Wide Marketing VP for a French company called EVE, which was founded in 2000. When I met Lauro, EVE had recently launched its flagship hardware acceleration and emulation product, the FPGA-based ZeBu (where “ZeBu” stands for “Zero Bugs”). With a lot of hard work on both the technology and marketing fronts, EVE and ZeBu became tremendously successful, eventually ending up being acquired by Synopsys in 2012.
As an aside, the term “zebu” also refers to a species of domesticated cattle originating in the Indian sub-continent. These little scamps are well adapted to withstanding high temperatures and are farmed throughout the tropical countries, both as pure zebu and as hybrids with taurine cattle. Now, I bet you’re thinking that I’ve wandered off-topic as is my wont, but…
… I just got off a video conference call with the chaps and chapesses from Mipsology. One of the guys I was talking to was Ludovic Larzul, who was Co-Founder and Engineering VP at EVE, and who is now Founder and CEO at Mipsology. As Ludovic told me, in the very early days of artificial intelligence (AI) and machine learning (ML), he turned his attention to the idea of using FPGAs to accelerate the inferencing performed by artificial neural networks (ANNs), which led to the founding of Mipsology in 2015.
If you visit Mipsology’s website, you’ll see them say, “We focus on acceleration, you focus on your application.” And they go on to state, “Accelerate your inference, anywhere, in no time and with no effort using Mipsology’s Zebra.”
Hang on; Zebu… Zebra… are we seeing a pattern here?
On the one hand, we have the zebras we all know and love — that is, African equines with distinctive black-and-white striped coats, of which there are three extant species: the Grévy’s zebra (also known as the imperial zebra, these little rascals were named after the French lawyer and politician Jules Grévy), the plains zebra, and the mountain zebra. On the other hand, we have Zebra by Mipsology, which, in their own words, “is the ideal deep learning compute engine for neural network inference. Zebra seamlessly replaces or complements CPUs/GPUs, allowing any neural network to compute faster with lower power consumption and at lower cost. Zebra deploys swiftly, seamlessly, and painlessly without knowledge of underlying hardware technology, use of specific compilation tools, or changes to the neural network, the training, the framework, or the application.” Well, that’s certainly a mouthful, but it pretty much covers all of the bases.
The Zebra stack, which was first introduced in 2019, is an AI inference accelerator for FPGA-based PCIe accelerator cards. Let’s suppose that you create a neural network framework using one of the usual suspects (TensorFlow, PyTorch, Caffe, MXNet…), and you train it using a traditional CPU/GPU setup. Transitioning from the CPU/GPU training environment to a Zebra inferencing deployment is a plug-and-play process that does not require any changes to the framework, the neural network, or the application. As the folks at Mipsology say, “Transitioning from the CPU/GPU environment to Zebra and switching back and forth between the two is possible at any time with zero effort.”
If you talk to the folks at Mipsology, they can (and will) explain in excruciating detail how performing AI/ML inferencing using FPGA-based PCIe accelerator cards beats CPU/GPU solutions hands-down with regard to lower cost and higher performance, but that’s not what I wanted to talk about here. The thing is that it’s all well and good to use FPGA-based PCIe accelerator cards in the servers in the data centers forming the cloud, but vast amounts of AI/ML inferencing tasks are migrating their way into embedded systems and to the edge of the internet. For all sorts of reasons — not least cost, power consumption, and physical size — it’s impractical to have PCs with PCIe cards as embedded systems or edge devices, so what are we to do?
Well, fear not, because the folks at Mipsology have us covered. They recently introduced their Zebra IP to accelerate neural network computing for edge and embedded AI/ML applications. As its name suggests, Zebra IP is a macro that can be implemented in an FPGA’s programmable fabric and integrated with other functions inside the FPGA (it includes a simple interface based on Arm AXI that facilitates communication with on-chip processor cores and suchlike). Now, this is where things start to get really clever. I think we need a diagram, but I don’t have access to one I like, so I’ve cobbled the following illustration together out of bits of other images (with apologies to all concerned).
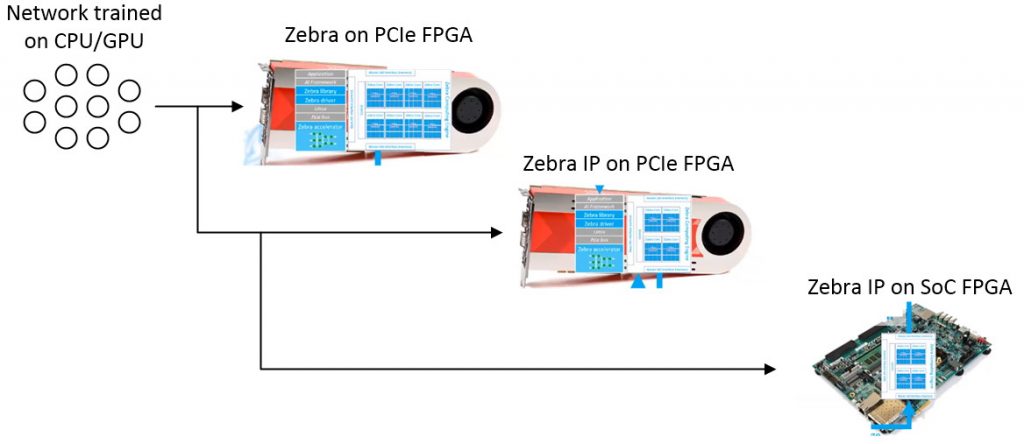
Zebra and Zebra IP development flow.
We start with a neural network that’s been trained in a traditional manner on a CPU/GPU-based system. As was previously discussed, this trained network can be transitioned to Zebra on an FPGA-based PCIe card using a plug-and-play process. This is where we can verify performance and accuracy.
When it comes to Zebra IP, the first clever part is that it can be loaded into the FPGA(s) on the PCIe accelerator card, thereby allowing for qualification of the IP’s behavior and reproduction of any potential edge-related issues. The final step is to load the Zebra IP instantiation of the neural network into the FPGA in the target edge device or embedded system.
As always, “the proof of the pudding is in the eating,” as the old saying goes, so just how good is Zebra IP? Well, first of all we have a small problem in that people are prone to prevaricate in terms of TOPS (tera operations per second), but real, sustainable TOPS aren’t the same as the peak TOPS that are so often quoted. A more reliable measure in the case of a visual inferencing application is to use real performance as measured in FPS (frames per second). In this case, Zebra is said to deliver 5X to 10X more FPS with the same “peak” TOPS, as is illustrated in the image below.
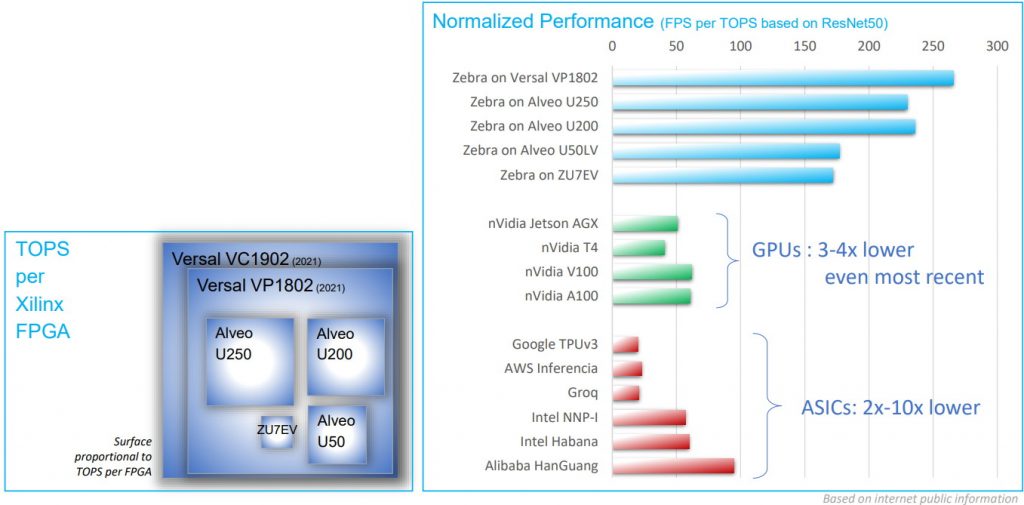
Inferencing performance: Zebra IP compared to GPUs and custom ASICs
(Image source: Mipsology)
I’m starting to feel like an old fool (but where can we find one at this time of the day?). For example, I designed my first ASIC back in 1980, which is more than four decades ago as I pen these words. At that time, I couldn’t conceive of anything out-performing an ASIC.
I remember when FPGAs first arrived on the scene in 1985 in the form of the XC2064 from Xilinx. This little scamp had an 8 x 8 array of configurable logic blocks (CLBs), each containing two 3-input look-up tables (LUTs). I remember being vaguely interested, but I had no conception as to how these devices would explode in terms of capacity and performance.
I also remember when what we would now consider to be GPUs started to appear in the 1990s (the term “GPU” was coined by Sony in reference to the 32-bit Sony GPU, which was designed by Toshiba, that featured in the PlayStation video game console released in 1994).
As their name would suggest, GPUs — which can be visualized (no pun intended) as an array of relatively simple processors, each with some amount of local memory — were conceived to address the demands of computer graphics and image processing. Over time, it was realized that this architecture could be employed for a wide variety of parallel processing tasks, including mining Bitcoins and performing AI/ML inferencing.
I fear I’m starting to ramble. The point is that, as recently as a few years ago, if you’d asked me to take a wild guess at the relative performances of ASICs, FPGAs, and GPUs for tasks like AI/ML inferencing, I would have placed ASICs at the top of the pile, GPUs in the middle, and FPGAs at the bottom, which just goes to show how little I know. All I can say is that if I ever get my time machine working (you simply can’t find the parts here in Huntsville, Alabama, where I currently hang my hat), one of the things I’m going to do — in addition to purchasing stock in Apple, Amazon, Facebook, and Google, along with splashing some cash on Bitcoins when they could be had for just 10 cents apiece — is to invest in companies like Mipsology. What say you?


