


Memory. What’cha gonna do with it, amirite? It’s too slow, too expensive, it takes up too much space on your board, and the supply is more volatile than a honey badger on acid. But every system needs memory, and the more processors you have, the more memory you need. Too bad there isn’t a way to, y’know, somehow make half of those problems go away.
Wish granted. A Gothenburg Sweden–based startup called ZeroPoint Technologies (ZPT) thinks it has come up with a solution: an all-hardware IP block that nestles in between your chip’s processor(s) and memory controller(s), cutting memory usage by more than half, slashing bandwidth on the external bus, and trimming the power consumed by all those read/write cycles.
What wizardry is this? What arcane secret have ZPT’s 15 employees uncovered that the rest of us somehow missed? The trick is all in compression. ZPT’s founders have been studying and implementing memory-compression algorithms for years, and they ultimately came up with Ziptilion, the company’s one and only product. It compresses data on the fly as it’s written to memory and decompresses the data on its way back in. Unlike some earlier approaches to memory compression, Ziptilion is (almost) completely invisible to software, including operating systems and drivers. It’s a hardware-only fix that squeezes more data into the same amount of RAM.
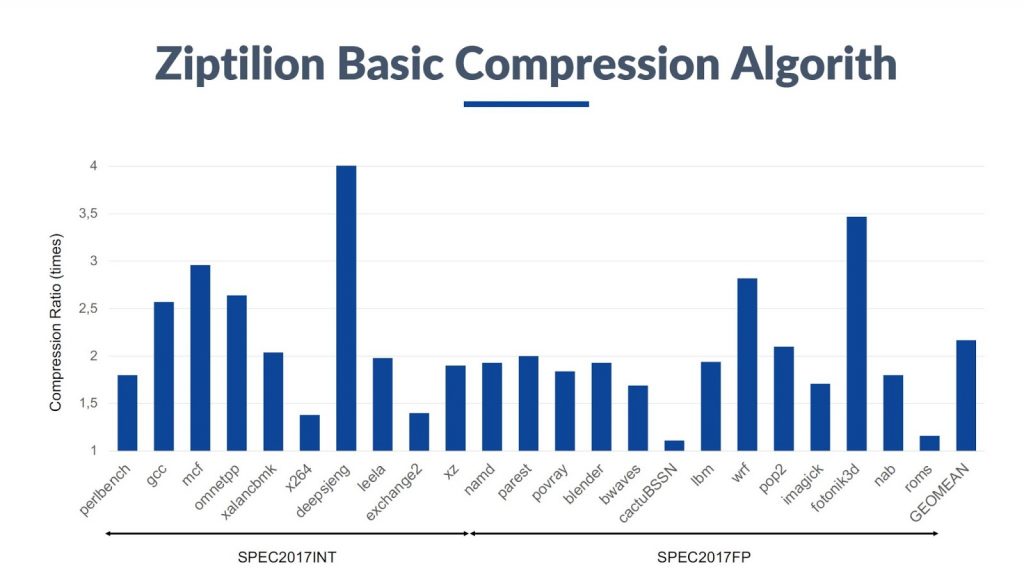
The company claims a 2:1 average compression ratio, meaning you can get by with half the physical memory you thought you needed. Compression also means bus transactions are shorter and less frequent, reducing bus traffic. And that, in turn, saves power. It’s a three-way win.
The catch? ZPT’s data compression takes time. Ziptilion adds 7 cycles to every memory write transaction, and another 7 cycles to every read. That affects latency, not throughput, so your system has the same memory bandwidth as before; it just takes a bit longer to get started. This may or may not affect performance, depending on the speed of your existing memory subsystem and the locality of your data references.
Memory compression isn’t a new idea – plenty of companies have either tried it or actually implemented it – but making it functionally transparent to the system is a new trick. IBM’s CodePack for PowerPC, for example, squeezed down the size of executable code (but not data) by compressing and decompressing instructions on the fly in hardware. This was different from other “compressed” instruction sets like ARM’s Thumb that simply used shorter and less flexible opcodes. IBM’s system really did reorganize and compress the bits of standard PowerPC binaries, like running WinZIP on program files. The downside was that compressed code wasn’t transportable, and it was inscrutable to debuggers. It also required cooperation from the host operating system to know whether code blocks were compressed or not. It worked, but it wasn’t pretty.
In contrast, ZPT’s Ziptilion requires no software intervention. It sits beside the memory controller and silently compresses and decompresses everything – code and data – as it passes in or out of the chip. The rest of the system is blissfully unaware that anything has happened, so there are no operating system tweaks or funny drivers to integrate. The only observable difference is that the frequency of memory transactions has declined.
Compression seems like a simple idea – obvious, even – but the devil is in the details. For starters, different data sets compress differently based on the compression algorithm used. Some data is not compressible at all. A JPEG image, for example, is already compressed; you can’t compress it any further. The size of the data also affects compressibility. Generally speaking, the larger the data sample, the more effectively you can compress it.
Then there’s the weird effect on memory addresses. Compressing data on its way out to memory necessarily changes where that data is written. Your software might think it’s writing 4096 bytes to address 0x8000–0x9000, but the whole point of Ziptilion is to squeeze that down. It won’t be 4096 bytes when it’s done, and it won’t be located at address 0x8000.
Ziptilion tackles the “best algorithm” problem by implementing several different ones, all proprietary to ZPT. (All compression is lossless, obviously.) It constantly monitors the data flowing in and out and chooses the most effective algorithm to produce the smallest result. It even changes algorithms on the fly, constantly iterating as data types change. Alternatively, you can force the choice of algorithm if you already know the characteristics of your data.
This self-training feature is automatic and invisible to the user or the system. However, it takes time to collect enough data samples to decide to change algorithms. Switching time is on the order of seconds, not milliseconds, according to CEO Klas Moreau. Ziptilion isn’t designed to change with every task switch or process thread.
Dynamically switching among different compression schemes adds yet another wrinkle. Any data written to memory obviously needs to be decompressed using the same algorithm that was used to compress it, even after the passage of arbitrary amounts of time, so Ziptilion tags memory with an algorithm ID.
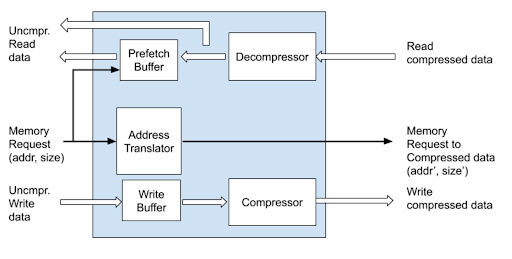
If compressing data on writes uses less memory, then read cycles must return more data than absolutely necessary. When Ziptilion receives a processor request (or more likely, a cache line request) to read 64 bytes from external memory, it doesn’t yet know how much space that data actually occupies, so it fulfills the entire 64-byte request. In all likelihood, the data occupies only about 32 bytes of RAM, so the additional 32 bytes is superfluous. Rather than discard the excess data, however, Ziptilion keeps it in a local buffer on the assumption that it will be requested next. In effect, it’s a read-ahead buffer or a very simple last-level cache. If the surplus data isn’t needed, no harm done. But if it is, Ziptilion saves an entire memory transaction.
ZPT offers an optional encryption module to go with Ziptilion, which many customers requested. Encryption happens after compression, partly because there’s less data to encrypt that way, and partly because encrypted data tends to be stochastic and therefore incompressible. Doing it the other way wouldn’t be very effective.
Although Ziptilion’s operation is virtually transparent to both hardware and software, there is one scenario where it may complicate life, and that’s during debugging. The actual physical memory addresses that Ziptilion uses don’t correspond to what the processor(s) think they’re using. In effect, it adds a level of MMU address translation above and beyond whatever the processor might be doing, but that’s hidden from it. That might confuse third-party debuggers or systems that use shared memory.
But even that’s not insurmountable. Ziptilion maintains its own MMU translation table in external memory, and when the device is in debug mode that table is not compressed or encrypted in any way, so debug tools can examine or interrogate it to see what goes where.
Ziptilion’s size, speed, and cost depend on a lot of factors, of course, but CEO Moreau says that 1.5 million gates is a good baseline number to plan for. Encryption adds more to that, the size of the prefetch buffer is configurable, and multicore implementations are more complex. Licensing terms are typical for semiconductor IP, with an upfront fee plus royalties.
Moreau points out that memory performance used to be an engineer’s biggest concern. Now it’s performance-per-watt, both at the low end (battery-powered mobile devices) and the high end (datacenter servers). Saving power by saving memory is an excellent tradeoff for these designs. The cost savings and optional encryption are bonuses. Unlike the stuff advertised on late-night TV, Ziptilion might be the memory supplement that actually works.



I’ll be grappling with memory decisions in future and do appreciate this piece