


It’s all about the monetizing of the Xeon.” – Dan McNamara, Intel PSG
Intel’s Data-Centric Innovation Summit, held earlier this month at Intel’s Santa Clara HQ, incorporated a lot of talk about the role of Intel’s FPGA products in the “great scheme of things.” Last week, I discussed the FPGA market with $8 billion in annual sales that Intel’s targeting—see “The New, New Intel Unleashes a Technology Barrage”—but that’s hardly the full story for Intel’s FPGAs. Dan McNamara, Senior VP and General Manager of Intel’s PSG (Programmable Systems Group), had a couple of opportunities to tell more of that story and to provide his carefully nuanced description of Altera’s transformation into Intel’s Programmable Systems Group. One opportunity was a lunchtime discussion at a catered affair in a walled-off section of Intel’s cafeteria, and the other was his formal afternoon presentation. Let’s take the two opportunities in reverse order, because the later presentation actually sets the stage for McNamara’s briefer, more off-the-cuff remarks at lunch.
In his afternoon presentation, McNamara said that he thinks of FPGAs as a “data shovel.” OK, not a very glamorous marketing analogy but an efficient, two-word description if that’s what you’re looking for. FPGAs remove data bottlenecks and accelerate the work, he said. I guess that’s what a shovel does, if you use the right tongue angle, as YouTube video star Dave Jones might say.
Then McNamara further parsed his meaning. “The cloud’s always looking to provide more services while managing TCO,” he explained.
Translation: Wherever possible, we want to offload more mundane tasks from our incredibly expensive Xeon server processors and move them to lower-cost, more efficient processing engines to make room in the Xeon for tasks that deliver more revenue to data center operators and more value to data center customers. In many cases, those offload engines are constructed in hardware using programmable logic—aka FPGAs.
Quick aside to lunch where McNamara gave a more succinct explanation:
“It’s all about the monetizing of the Xeon.”
This is the reason Intel’s currently giving for its acquisition of Altera. (For more details about the acquisition back in 2015, see Kevin Morris’s “After Intel and Altera: What Happens to FPGA?”). Is monetizing the Xeon a good reason to buy an entire FPGA company? Well, sure it is. Earlier in the day, during the Data-Centric Innovation Summit, Intel’s EVP and GM of the Data Center Group Naveen Shenoy had said that Intel had shipped 220 million Xeon processors worth an aggregate value of $130 billion over the last 20 years. (Intel is celebrating the Xeon processor’s 20th birthday this year.)
Here’s a Xeon family tree, for those keeping score:
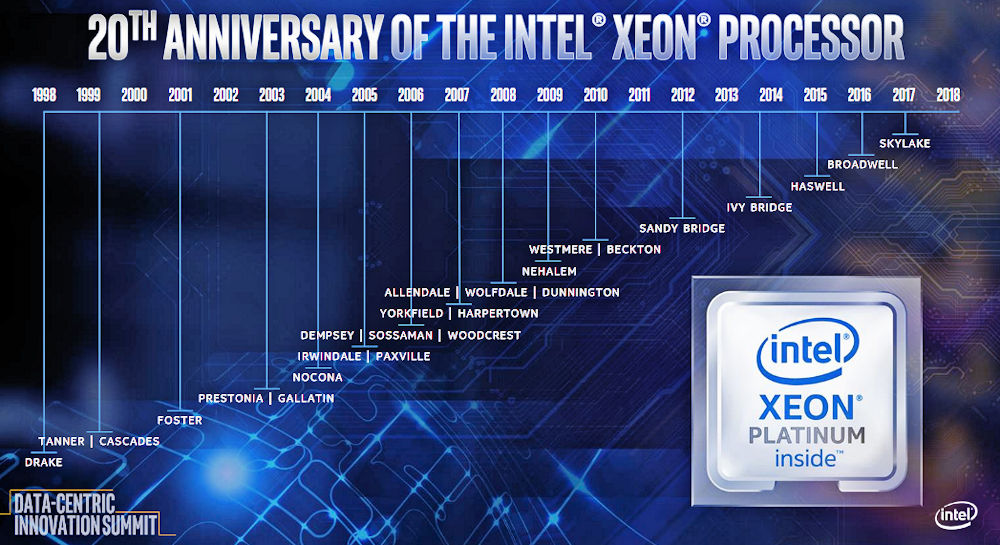
Figure 1: The Intel Xeon family tree spans two decades. (Image source: Intel)
During his morning talk, Shenoy made it crystal clear that Intel was not about to move high-value tasks from the very, very profitable Xeon processor line to the still-pretty-darn-profitable Intel FPGA product line. He did that by citing the new features coming up in future Xeon processor designs that will make Xeon processors more valuable to data centers, including built-in support for Intel’s Optane DC Persistent Memory DIMMs, a new layer in the ever-expanding memory hierarchy, new instructions for AI and machine learning dubbed “Intel Deep Learning Boost (DLBoost),” and support for a new AI-oriented, 16-bit, floating-point data type originally developed by Google called BFloat16, which is useful for neural-network training rather than inference.
Support for Optane DC persistent memory and the initial version of DLBoost are scheduled to appear later this year in a 14nm Xeon iteration code named Cascade Lake. The follow-on Cooper Lake version of Xeon, also fabricated with 14nm process technology, will appear in 2019 with an improved, second-generation version of the DLBoost extensions and BFloat16 support. By 2020, Intel intends to roll these innovations and more into a 10nm device called Ice Lake. Shenoy didn’t elaborate on the “more” part of that last sentence.
Segue back to FPGAs and Dan McNamara’s afternoon talk, where he discussed several tasks ripe for Xeon offloading, including “lookaside acceleration” such as neural network inferencing, image and video transcoding, and database searching; network infrastructure acceleration including network packet processing, storage, and security; and enterprise application acceleration including data analytics, financial processing, video processing, network and data security, and genomics. These target applications are a sure bet for Intel PSG’s FPGAs, because they’re already being performed by an increasing number of Intel and non-Intel FPGA boards plugged into servers located in data centers around the world.
Getting down to the brass tacks of production and product delivery, McNamara said that Intel PSG’s 14nm FPGA products are in production and that his group was now focused on “filling out the family.” (Translation: Intel PSG is busy designing more 14nm parts and bringing them into production.) McNamara also said that, going forward, the 14nm devices would be the dominant design-win vehicle for his group, and he mentioned that we will see more use of Intel’s EMIB (Embedded Multi-die Interconnect Bridge)—a form of 2.5D chip assembly—in future Intel PSG products to add functions such as embedded ARM cores and high-speed SerDes transceivers.
McNamara said that his group is going “full steam ahead” on 10nm FPGA designs and that Intel planned to sample these new parts next year. You might want to take that statement with a grain of salt when you consider that the 10nm Ice Lake Xeon variant discussed a couple of paragraphs above isn’t scheduled to ship until 2020. My spider sense and the usual Intel financial boiler plate caution about future predictions—“forward-looking statements… involve a number of risks and uncertainties”—tell me not to take that sampling schedule to the bank. As Shenoy said earlier in the day during a Q&A session, “I don’t talk to customers about nm.”
There’s a valid reason for that in Intel’s recent history, and I don’t see 10nm FPGAs upstaging Intel’s flagship 10nm Xeon processors or even getting in the flagship’s way within the 10nm fab. Even with all of the transition talk during the Data-Centric Innovation Summit about Intel’s migration from processor-centric to data-centric, I don’t see processors taking a back seat to FPGAs in Intel’s most bleeding-edge process technology. That’s not to say it couldn’t happen; however, remember McNamara’s lunch statement: it’s all about monetizing Xeon.
Finally, McNamara discussed Intel’s recent acquisition of eASIC in the context of Intel PSG and FPGAs. During his afternoon talk, he said, “eASIC adds an end-to-end lifecycle solution” through its structured ASICs, which have a lower NRE than ASICs. Adding eASIC to the portfolio means that Intel will supposedly have a way to reduce the cost of FPGA-based designs by taking these designs and rolling them into eASIC’s structured ASICs, which will have lower unit costs and lower power consumption than the FPGAs they replace. Here’s the relevant slide from McNamara’s talk:

Figure 2: Intel’s justification for its acquisition of eASIC includes synergy with Intel PSG’s FPGAs (Image source: Intel)
Earlier, during lunch, McNamara said, “Look at eASIC as a little bit of a hedge.” Tasks that aren’t changing twenty times a month are ripe for conversion to a structured ASIC.
This is the existing eASIC story, so it can certainly work for Intel. However, if you’d like a deeper analysis of Intel’s eASIC acquisition, be sure to read Kevin Morris’s July 17 article titled “Intel Acquires eASIC – Why?”



Then there is a sort of middle ground: Quit designing using individual FF’s and gates.
Use memory blocks to store literals and variables — Use memory blocks for sequence control —
Use memory blocks/LUTs for arithmetic logic.
What????????
Three dual port memory blocks and a couple of hundred LUTs can execute C statements and expressions with no need for a CPU and OS with all the overhead for interrupts, context switching, branch prediction, cache coherence, speculative execution, etc.
And it is blinding fast because the memory blocks cycle in parallel with no cycles wasted to
fetch load instructions to then fetch data operands.
With hundreds/maybe thousands of memory blocks available on chip what is typically done by an interrupt handler can be done by dedicated parallel hardware.
IBM made a lot of money using microprogram control for general purpose computing, then went with superscalar for compute intensive applications. (because Moore’s law was good enough for general purpose)
Problem is that RISC/superscalar/cache coherency/multicore/… are running out of gas and the memory wall is real.
Oh, yes multicore was supposed to solve the problem. Too bad no one can figure out how to program it.
If anybody is ready to consider a new approach, let me know. I have design, architecture, debug, and troubleshooting experience from micro controllers to mainframes and just plain old logic design.
I certainly have to agree … that was the big reveal after doing the FpgaC project a decade ago. Unfortunately that was strongly torpedoed by Xilinx staff and supporters when the Virtex parts of the day started rolling over dead with on die SSO problems when more than a few percent (something over 10-30%) of the logic was active. There was NO external bypass fix to keep the parts stable. The on die power and ground rails would simply pull too close together, and noise would send them unstable.
All it took was modest parallel loop unrolling and reverse pipelining to drive SSO’s above 70% quickly, and the FPGA execution platform starts really performing … until some data pattern triggered noise issues and hard power resets on the Virtex parts. Xilinx called these “perverse” designs, because “normal” designs had SSO’s below 15% or so. I’ve baited Xilinx several times to assure developers that the SSO problems they call “perverse” designs are no longer an issue … never a reply. Leads one to suspect it’s still an issue they want to hide.
The Xilinx 3rd party C of the day avoided the SSO issue with a slow sequencer design, so it wasn’t much of a speed up, but rather a simple HLS framework that could still pull off some amazing design wins.
The netlists FpgaC produced have some serious logic depth issues, that a good logic optimizer can remove. Or you can be aware of the issue, code the C “nicely” to produce more optimal results, and clean up the rest by hand. A rewrite removing the 4-bit logic tables, with an internal optimizer is really in order … using OpenMP extensions.
Xilinx at the time was brutally obstructionist … and claimed any Open Source tool that produced/exposed their internal macro names and other API/tool interfaces was an IP and license violation, would be subject to litigation. So it was time two walk away from public updates of FpgaC. A rather sleazy choice for a company that uses Open Source tools in other areas, yet keeps key product access closed for external open source developers.
It’s tempting to resume FpgaC work … maybe with Intel support, and/or some other FPGA vendors support. The Microsemi Polarfire parts are larger than the Virtex parts a decade ago, and much lower power. I’ve been told it’s unlikely they will have internal SSO problem like the Xilinx parts did.
There are several significant speed up strategies that I prototyped a decade ago, that would be useful to get flushed out in a rewrite. A new sequencer design that takes place and route feedback to optimize clock speed in several important ways. Using block rams as large variable width LUT’s for large complex combinatorial nets. Support for multiple disjoint parallel access address spaces by type, including address pointer typing and folding. Integrated streams/messaging with cross clock domain safety.
FpgaC from it’s TMCC roots is amazingly simple and powerful … even with it’s warts. It would be nice to rewrite it, and remove the warts.
For the record … Austin’s USENIX FPGA post … first time Xilinx publicly admitted the problems we had with SSO’s was real … and that took some serious backing them in the corner … before that was just slurs we didn’t know what we were doing.
Subject: Re: fastest FPGA
From: Austin Lesea
Date: Fri, 25 Aug 2006 07:45:00 -0700
OK,
The Virtex 4 family is the first family to ever be able to shift 1,0
through all resources (without tripping power on reset from the
transient of all switching on the same edge).
Cooling it is another matter, as many have stated.
[…]
So, even this perverse design (in V4, or V5) is now able to run, in the
largest part.
I still do not recommend it, as the THUMP from all that switching leads
to not being able to control jitter, even with the best possible power
distribution system. I believe that V4 and V5 will require some
internal ‘SSO’ usage restrictions, as they are not like earlier devices
which would configure, DONE would go high, and then immediately reset
and go back to configuring if you tried to instantiate and run a full
device shift register.
Austin
This proposal is not a CtoFPGA, CtoH, or C to anything. It is a design that actually foes if/else, for, while, etc and assignment/condition expressions.
The CSharp Syntax API SyntaxWalker visits the nodes according to the precedence of the operators in the assignment expressions. It is then a matter of getting the 2 operands and operator for binary expressions then applying the operator to the operands and pushing the result to the stack.
There is a little more to it, but if the stack and operands are implemented as memories it simply becomes memory reads rather than the horrible select the right registers and drive all the individual bits to the ALU and drive ALU out to the stack with all the SSO poblem(the SSO is inside the memory blocks).
So read the control word memory to get the 2 operand addresses.
Use the two addresses to read the 2 operands(dual port).
Read the next control word using the incremented address in the same cycle as the operand read
Apply the operator to the first 2 operands while the next operator and operand are being read
Push the ALU out to the stack so the stack supplies one operand while the other is read
This uses 3 true dual port memory blocks and a couple of hundred LUTs for ALU, a couple of incrementers, and control word decode.
The FPGA design is simple and independent of the C code, build the FPGA and load the memories from the parsed C code.
Then you are compiling your C to your own ALU+CTL CPU (or interpreter) design with a custom instruction set (or pop code) or expanded out as a data flow pipeline engine. If there is any significant parallelism, then there will be SSO issues if the design is non-trivial. You can not hide SSO issue’s inside memory … as they occur in the communication between hardware blocks (memories, LUT’s, registers, muxes, etc). Designs using a clock per C statement with an execution graph FSM, generally are easy to implement, but will not be very parallel, fast, and frequently a CPU/SOC design will be better.
A C function (of any size) without loops can be reduced to a highly optimal Boolean multi-valued combinatorial expression that is highly parallel, and optimized for logic depth with a single clock. Doesn’t matter if it’s 1 statement, 5 statements, or 5 million statements long. All intermediate values in the function just turn into signals (never a memory or register assignment), where only exported values and saved state are stored as memory or register values. The logic is just packed into LUT’s, MUX’s, and block RAM’s as jumbo LUT’s … what ever yields fastest clock rate and lowest power.
A C function with loops can generally be unrolled, and again reduced to a highly optimal Boolean multi-valued combinatorial expression that is highly parallel, and optimized for logic depth with a one (or more) clock.
A larger C program broken into multiple functions can be just as efficiently parallelized and reduced, by compiling function calls inline.
Then construct an outer FSM from the outer loop, or clock from external events.
If the combinatorial depth is too deep, it can be segmented to multiple clocks and/or pipelined.
It’s generally useful to keep XOR logic in ESOP form, and other logic in SOP form, possibly negated to reduce the number of terms in the expressions.
This is how you make C as an HDL highly competitive in speed and power when using an FPGA. FpgaC did very little of this, because it didn’t do a really good job at logic optimization. In theory the vendor tools could … and probably should, but they are targeting RTL and Verilog designs, where removing a large sweeping swath of expressly instantiated logic would probably be the wrong optimization choice.
So all of those things can be done, should be done, but nobody is doing them.
Probably because designers are hung up on the things you wrote about.
Meanwhile large chips are being designed and simulation/verification/emulation is taking forever and is very expensive.
Sure, the vendors are sticking with RTL because of all the brainwashing and hype.
And the things you mentioned don’t seem to make things easier, just possible.
And as I recall HLS in all its forms still has not matured enough to be truly general purpose.
Why it was such a big deal that Verilog could simulate hardware therefore it should become a design language is a total mystery to me.
Use of if statements to describe Boolean logic was done because it was a way for programmers to write synthesis code.
Meanwhile hardware designers had to convert Boolean logic into flow if statements after they had done the design. Oh for the good old days when designers could concentrate on the design rather than how to do design in spite of having to contend with RTL.
Anyway, you have put your spin on what I propose and made false assumptions while doing it.
Thanks for your time .
Then you should probably stop hand waving with general statements, and point people to a public open source web site where they can just try it and see how it’s “really supposed to be done” using your tools.
There are a lot of things right about FpgaC as an HDL or HSL 90% demonstration project that shows it’s possible to use C efficiently as an HDL, and that C HSL makes sense. For instance, one key optimization is the removal of all logic that doesn’t affect an output, which for some constructs removes about 90% of the logic that would otherwise be instantiated.
Formal logic as a discipline predates electrical engineering by a couple thousand years, it just became a handy tool to deal with modern logic systems. So useful, that I found both Modern and Traditional logic classes in the Philosophy Dept to be gold mines during my undergrad work in the early 70’s. Without the long history of logic disciplines as a foundation, we might still be living in an analog only world of electronics today.
It really doesn’t matter if we choose to describe our problems as:
1) if(a) then b, else c.
or
2) a?b:c
or
3) a&b | !a&c
Or what every your personal favorite expression and syntax is.
I have spent some time around HLLs for FPGAs. It has its ‘warts’, too, but what is wrong with OpenCL? We had some decent results with it a few years back, but it wasn’t good enough to displace the GPUs we were using at the time.
I think it goes something like this:
GPU was invented for graphics processing.
The key was that the data could be streamed from main memory to local memory. Once the data is local – and not shared globally as in cache coherence, etc. – the GPU only accessed local memory.
The processing was compute intensive and the data was contained in a defined block. OpenCL
is probably similar, just not proprietary.
How about the SOC world and general purpose processing and power constraints?
1) no need for 64 bit addressing
2) need to reduce number of clocks per operation for power and speed
3) global sharing of memory costs time and resources
C programs use blocks of memory and some variables and literals.
1) Memory is dynamically allocated or is from an input source an doesn’t always have
to be put into main memory and then accessed repeatedly for processing
2) variables and literals probably can easily fit in an embedded memory
Time to quit rambling!
BUT the world of general purpose multi-user shared memory brings with it a whole lot of baggage. Then when data and instructions are in that same memory AND the CPU uses RISC architecture there is a n instruction fetch to get the load instruction which then does a data fetch to get each operand and then an instruction fetch to get the operator and then an instruction fetch to get the store instruction then a store instruction to write the result to memory.
Microsoft research did a study “Where’s the Beef?” compared an FPGA to various CPUs and found that CPU spend a lot of time doing instruction fetches. Then followed up with ‘Project Catapult’ where they found that FPGAs could out perform any CPU they could find.
My take is that blocks of data are read to local memory where the FPGA accesses that data faster because it is local, but a CPU would still access as if it was shared.
Yes indeed, it is common knowledge that register files, speculative execution, out of order, instruction cache, data cache, and the other glitzy stuff that has been marketed ALL solve this problem.
EXCEPT to refer back to the success of the GPU because the data was packaged as a workload and put into local memory, it beat the pants of of all the glitzy stuff and lead to OpenCL.
So here we are up to our ___es in all this glitzy stuff.
But, if we put the C/HLL statements AND variables/literals in local memories(true dual port) we can read both operands, the operator, and the next statement/expression all in the same cycle that the previous operator is being evaluated.
Karl15/CEngine16 project on git has an application and source text that I am using for debug.
Start the app and select the Demo15 file for input. CEngine is a work in progress and git is new to me so I don’t know how useful it will be, except that it shows how few clock cycles it takes to run general purpose C.
Now that Moore’s law is not doubling CPU speed fast enough and we have all the glitzy gizmos, I went into design mode and came up with CEngine.
Variables, literals, and stack are in one local memory.
Statements are in another.
And the third controls expression evaluation.
All 3 are accessed so current and next operators and operand are available to read the next 2 operands and operator while the current operator is evaluated.
Nothing wrong with OpenCL … works great on CPU’s, GPU’s and FPGA’s, especially for any application where SIMD has value, and other SIMD data sets as well. It’s been ported to most major CPU’s and GPU’s. It’s largely Std C, with a few kinks and bells. It’s a real plus that Altera/Intel support it.
I find CUDA better for Nvidia chips, although there really isn’t a good reason for this, and someone should simply do a better compiler job with OpenCL optimizations on Nvidia. Cuda’s “driver API” provides good low level hardware access. With some minor thought, differences are minimal, and you can port easily between the two.
https://arxiv.org/vc/arxiv/papers/1005/1005.2581v1.pdf
The choice between CPU, GPU and FPGA is often driven by the resources on the board. Both high end CPU/GPU’s come with a lot of FAST memory, GPU’s with fast I/O back to host memory. Most FPGA boards are lacking lots of fast memory. Multi-core cpus with sse/avx support blur the need for GPU/FPGA acceleration.
A decade ago I built several large PCI FPGA boards that had 8 or 16 tiles of FPGA/memory/storage, and fast PCI-E back to host memory. Each tile had DDR3 memory plus two TFlash/microSDHC cards. High bisection bandwidth between tiles with an onboard mesh plus Hypercube architecture. Performed well (even after derating for SSO’s) to accelerate VERY large simulations.
Today I do better running the simulations on my desktop … An Alienware R2 with an E5-2686V3 that has 18 cores, 36 threads with full sse/avx support and a large cache. GCC supports the vector extensions. When that’s not enough, the three large nVidia cards with an SLI bridge and CUDA will generally step up to meet the challenge. It’s been tempting at times to switch to a dual-cpu E5-2686V3 motherboard. ASRock Rack EP2C612D16C-4L.
It’s also been tempting to do some more 8 or 16 tile FPGA boards with faster memory and storage, probably using large Polarfire FPGA’s when they are available, and extend the Hypercube using fast serial across 2 or 4 boards. There are certainly some problems that are faster on FPGA’s, especially a dense fabric of FPGA’s.
Languages are just that, languages, …. it’s what you want to talk to that defines the best choice(s). A BIG CPU chip, or a BIG FPGA chip, alone are nearly worthless for most applications … it’s what they are tied to that provides value … memory, communications, storage, and other resources. Some relatively simple projects we bundle small amounts of these resources on a single chip (SOC) to cost effectively solve relatively simple problems.
BIG computation problems come in different flavors, generally classified by the number of instructions needed and the amount of data to be processed. A particular class is generally called Single Instruction Multiple Data (SIMD in Flynn’s taxonomy) where we optimize the architecture (and the language used) to do the same processing (instructions) on a very wide swath of memory objects (data).
In the old days, we built special purpose super computers for this task, like the Cray’s. Today we have SIMD instructions in most desktop processor CPU’s, and we build specialty SIMD processors like GPU’s (or custom FPGA designs) to do that even faster than many CPU’s. OpenCL is a good language for describing SIMD operation on memory data sets … and is useful for both GPU and FPGA designs for processing SIMD optimized solutions. The size and organization of the data, leads us to making the best cost effective choice for a particular data set … sometimes after looking at the total overall solution, rather than narrowly focusing the large part of the data.
If you are in France, you probably want to speak French … although English, German, or Spanish will probably get you around with locals in the tourist trade. If you are working with data sets that are SIMD optimal, then a CPU with SIMD instructions, a GPU, or an FPGA may yield the optimal system level instruction. If the OpenMP C has SIMD optimization for a particular CPU architecture, then you may find that CPU to be a good fit for the problem with large caches and multiple cores. If it’s not enough, then adding a GPU or FPGA to the system, and using OpenCL may solve the problem in a cost effective way.
Using C, C#, or C++ isn’t normally the best language for doing SIMD processing … unless you have a library of functions that access the SIMD functions natively. That’s not to say they don’t work, as there are a lot of SIMD C applications that use an ASM macro to invoke native SIMD instructions in the CPU.
C as a language, is something of a Swiss army knife … rarely do you have to write external functions in assembly to get near optimal performance … just a little thought and a couple ASM statements will typically solve the problem if the C compiler doesn’t instantiate particular architecture optimal instructions natively. And when using GCC … sometimes the correct solution is to add that support to the compiler for the particular architecture, and submit upstream to the maintainers.