


Do you remember the song Blinded by the Light? This composition, which was originally written and recorded by Bruce Springsteen, first appeared on his 1973 debut album, Greetings from Asbury Park, N.J. Bruce is, of course, a legend. As awesome as his rendition is, however, I will always associate Blinded by the Light with Manfred Mann’s Earth Band, who released their version three years later as a track on their 1976 album, The Roaring Silence.
I was just perusing and pondering the lyrics. I still don’t have a clue what they mean, but I truly do love this song. The Manfred Mann version includes the “Chopsticks” melody played on piano near the end of the bridge of the song. That was one of the first tunes I learned to play on the piano. I’m not a great pianist, but if Manfred and his chums ever need a hand, I could certainly cover this part for them. I can’t help myself—I must watch the YouTube video—I’ll be back in a minute.
Wow! That was a trip down memory lane for sure. I was a young, bright-eyed, bushy-tailed student at university when this came out. Now I feel like an old fool (but where are we going to find one at this time of the day?).
Thoughts are sparking like fireworks in my poor old noggin. For example, The Color of Magic and The Light Fantastic by Terry Pratchett (RIP) just popped in and out of (what I laughingly call) my mind.
The reason for my meandering musings is that I was just chatting with Maurice (Mo) Steinman, who is VP of Engineering at Lightelligence. We commenced by contemplating a couple of images we’ve all seen before:
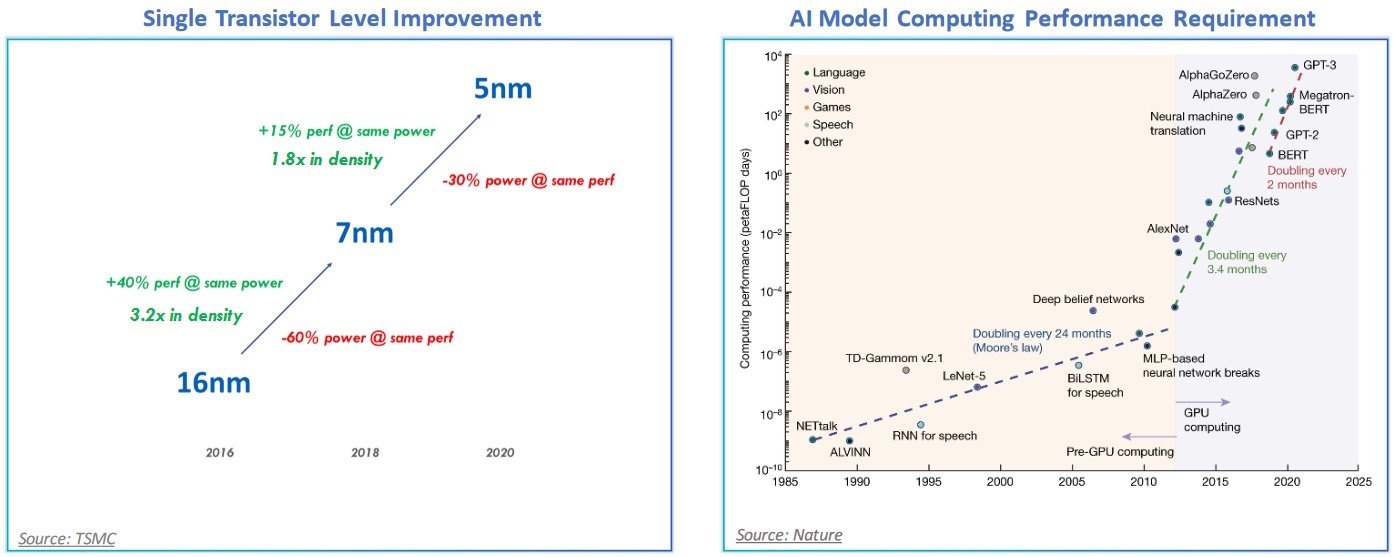
Transistor scaling is falling behind demand (Source: Lightelligence)
On the left, we see an illustration reflecting an example of the scaling of process nodes, which—amazingly enough—is still roughly tracking Moore’s law (remembering that Moore originally postulated a doubling of transistors per unit area of silicon every 12 months, then revised this to every 24 months, and then adjusted it again to every 18 months; so, not so much of a “law” as a flexible rule of thumb, but there we are).
I do have to admit that the chart on the right caught my eye. This depicts the computational performance requirements of artificial intelligence (AI) and machine learning (ML) models. This chart was originally published a couple of years ago by OpenAI (the creators of ChatGPT). At that time, they divided things into two eras.
During the first era, which commenced with the Dartmouth Workshop in 1956 and lasted until around 2012, the computational requirements for AI/ML roughly tracked Moore’s Law, which was convenient. In 2012, we experienced an inflection point, after which AI/ML computational requirements started to double every 3.4 months. The reason I make mention of this here is that the updated version of the chart shown above indicated that the computational requirements are now doubling every 2 months (look at the upper-right-hand-corner). Eeek Alors! (And I mean that most sincerely.)
One important point to note is that it’s not only computation and the processing of data that’s important—we also need to worry about communications bandwidth and moving vast quantities of data around. Happily, the folks at Lightelligence are on a mission to cover us at every stage in the game, from optical-based computation in the form of their oMAC server, to optical network on chip (oNOC) technology, to their optical networking (oNET) solution.
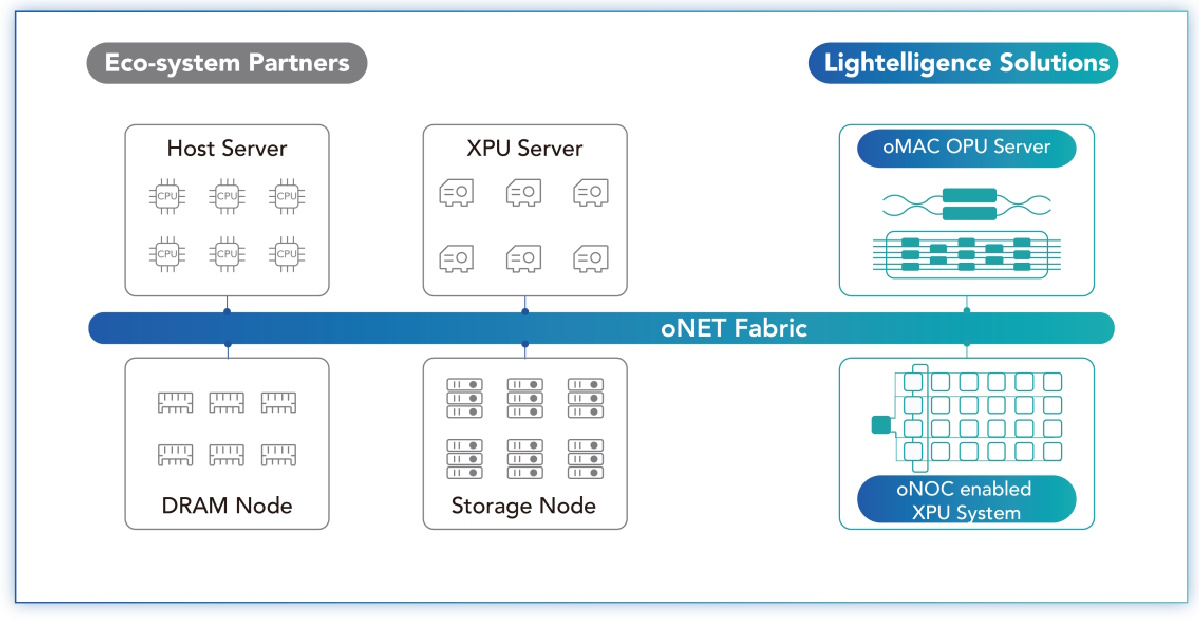
Scaling compute and communication with photonics (Source: Lightelligence)
A somewhat more corporeal representation of these technologies is illustrated below. On the left we have optical compute in the form of the oMAC—Lightelligence’s first fully integrated photonic computing platform—which is more properly known as the photonic arithmetic computing engine (PACE). The core of PACE is a 64 x 64 optical matrix multiplier that can address NP-complete problems 100X faster than an equivalent GPU-based solution.
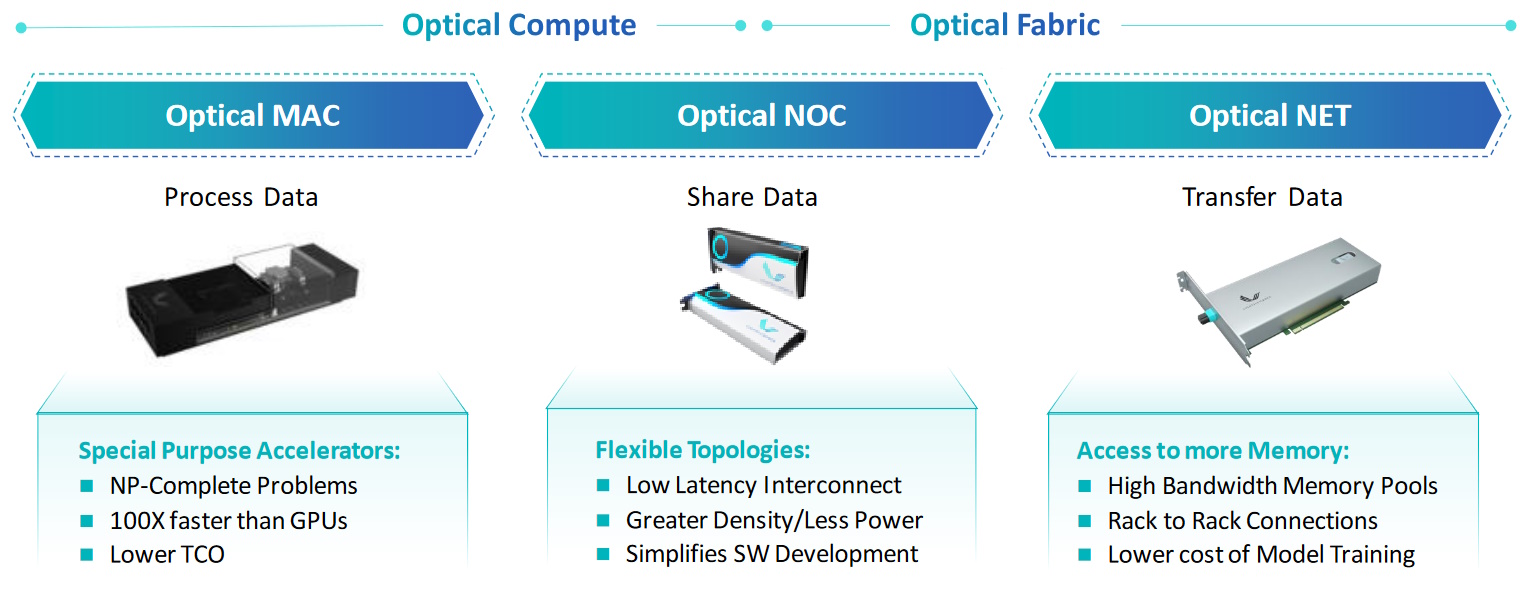
Scaling compute and communication with photonics (Source: Lightelligence)
On the right, we have optical communication in the form of oNET, whose bandwidth is orders of magnitude higher than an electrical equivalent while consuming a fraction of the power and providing minimal latency.
And, in the middle, with a metaphorical foot in both the optical compute and optical communication camps, we have Lightelligence’s oNOC technology. As fate would have it, it’s the oNOC we are going to focus on for the remainder of this column.
As we discussed in a recent column—Are You Ready for the Chiplet Age?—if you want to build a silicon device with 100B+ transistors, then chiplets are your new best friend! One thing I hadn’t really considered until I penned that piece was how all these chiplets would communicate. As I wrote in another column—Cheeky Chiplets Meet Super NoCs—a lot of people are looking at extending regular network on chip (NoC) technology to create “Super NoCs” that facilitate die-to-die (D2D) communication.
Just to remind ourselves, there are all sorts of NoC topologies available to us, a few of which are illustrated below.
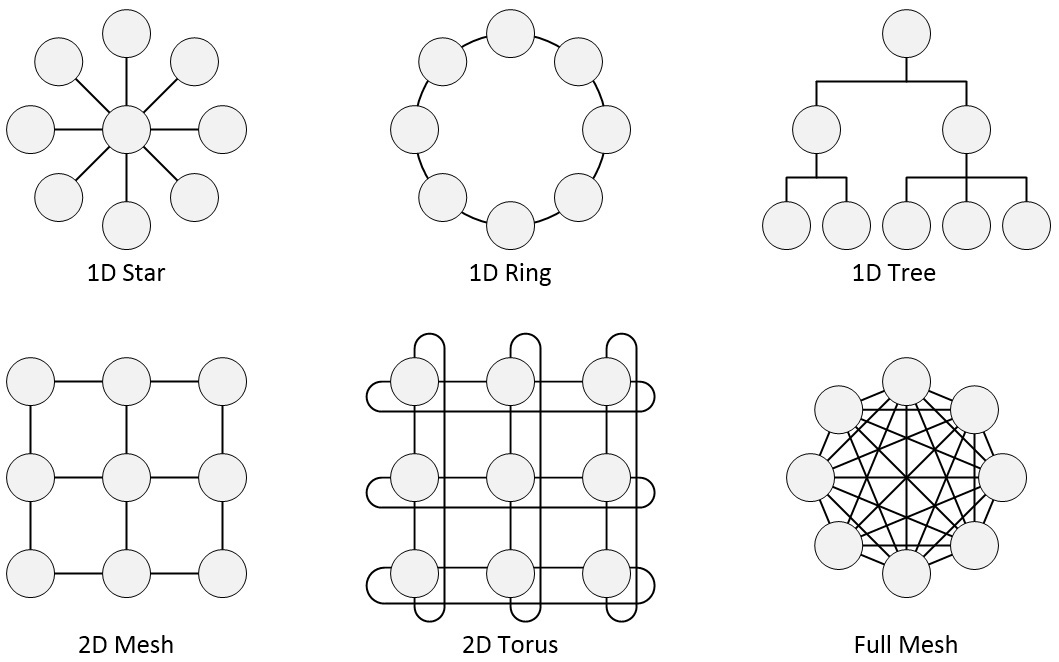
Some example NoC topologies (Source: Max Maxfield)
Until my chat with Mo, I’d always considered NoCs in the context of electrical (eNOC) implementations. Now, Mo has opened my eyes to the concept of optical (oNOC) realizations in which one or more electronic integrated circuits (EICs) are mounted on top of a photonic integrated circuit (PIC), with everything being presented to the outside world in the form of a system-in-package (SiP). A key point to note here is that all of the NoC typologies depicted above (and more) can be implemented as oNOCs.
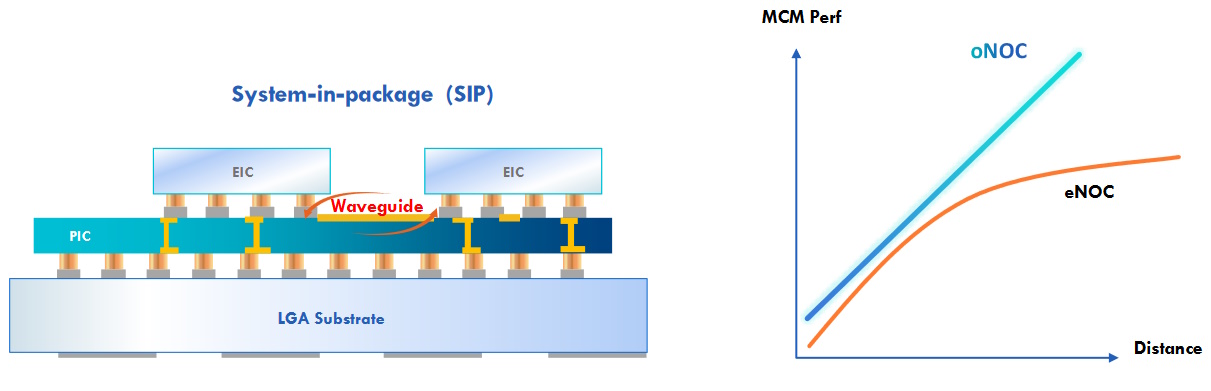
Optical Network on Chip (oNOC) (Source: Lightelligence)
All of which brings us to Hummingbird, which the folks at Lightelligence describe as, “The world’s first Optical Network-on-Chip (oNOC) processor designed for domain-specific artificial intelligence (AI) workloads.”
Hummingbird is the first in what will be a family of products. In this case, there is a single EIC mounted on the PIC. The EIC contains 64 cores connected using a low-latency optical all-to-all broadcast network employing 64 transmitters and 512 receivers.
Hummingbird’s electronic and photonic ICs are co-packaged and integrated into a PCIe form factor ready for installation in industry-standard servers. Coupled with the Lightelligence Software Development Kit (SDK), AI and ML workloads can be optimized to take full advantage of the oNOC. Furthermore, the oNOC and Hummingbird IP can be customized for other unique workloads and applications.

The Hummingbird SiP (the large device to the right of middle) featuring an oNOC presented on a PCIe card (Source: Lightelligence)
As an aside, since it started in 1989, HOT CHIPS has been known as one of the semiconductor industry’s leading conferences on high-performance microprocessors and related integrated circuits. This event is held once a year in August in the center of the world’s capital of electronics activity, Silicon Valley. The reason I mention this is because…
…I know that your next questions about Hummingbird are going to be “How fast does it go?” and “How much power does it consume?” I’m so glad you presented me with these posers. The short answer is that I don’t know. The longer answer is that, when I asked Mo, he said he was keeping this information under wraps because the folks at Lightelligence are going to blow everyone’s socks off at this year’s HOT CHIPS conference. This august event is scheduled to take place 27 to 29 August 2023, which is just next week as I pen these words. All I can say is that if you are planning on attending HOT CHIPS yourself, then you may wish to sport elasticated socks. Now I’m waiting in dread antici…
…pation for all to be revealed (I love the I See You Shiver in Anticipation scene in the Rocky Horror Picture Show). Meanwhile, while we are waiting for HOT CHIPS to slake our curiosity, you may be interested to learn that, earlier this year, my colleague Amelia Dalton interviewed Mo for a Fish Fry podcast about Photonics and the Future of Optical Computing. How about you? Do you have any thoughts you’d care to share about anything you’ve read here?


