


Noooooo! Are you kidding me? How many times has this happened so far? You know tape-out is tomorrow, right? Dangit! <deep breath> Ok, what it is this time? … Yeah… ok… A timing problem… so in the bring-up sequence, you want to hold the 0 state in that stupid register for an extra cycle? In other words, you guys got the timing wrong and it’s now my job to cover your butts? And now if it doesn’t work or if we’re late, it’s my fault, right? Nice transfer of that hot potato. Jeesh… You realize this is going to need verification, right? I don’t even know if the regression suite can run in time even if we started now! And I need to find all the places where this needs to change… Ok, we’ll get star –
Oh noooooo! All the freakin’ drivers need to change! Oh jeez, how many people are working on that? And the lead customer… they’re doing their own, right? So now they all need to change their drivers? Man… OK, I’ll start letting them kno –
Oh, nooooooo! This is going to screw up all the test programs for when the silicon comes up. I need to call Joanne too – oh, wait, didn’t she just leave? Who’s in her place right now? Gah! I don’t even know whom to call!
Ohhh, and the documentation! <muffled sob>
OK, so, hopefully your development process is under better control than that one. Panicked phone calls and ad-hoc “Whom does this affect?” lists off the top of your head aren’t necessarily reflective of proactive planning… But then again, in some way, at some time, this has happened to all of us, right? Maybe you didn’t scream and wail into the phone, but you wanted to, right?
Of course, there is a way to avoid this whole thing, or at least some of it. It won’t eliminate the chance that some change will come down the pike at the eleventh hour, and it doesn’t mean there won’t be a scramble. But, with a little planning, much of the scramble can be avoided.
The problem here is a familiar one. One change triggers an avalanche of other changes. As depicted above, we might have two issues to contend with: an encapsulation issue and an abstraction issue.
Nothing strikes terror like knowing there’s some thing you have to change and you aren’t sure if you can come up with all the places that it needs to be changed. Good luck searching. Of course, the solution to this is straight out of Coding 101: take tasks and sequences that have a clear identity and put them into a separate routine. You then call (or instantiate) the routine from all the places where it’s needed. And when the change is needed, you make it once, and you’re good.
I know, I know, everyone knows this. Whether it’s creating subroutines, functions, chunks of hardware, objects, whatever, we all know to encapsulate routines for this kind of eventuality. And yet, when the time comes to write code, we all too often simply start writing code. Or so it would seem, since these problems still happen. (Or is it just me?)
But the big thing we’re dealing with here is abstraction. We’ve got this routine that has to happen, and we need to write it for our verification and validation routines; we need to write it for drivers; we need to write it into characterization and test programs. We need to document it. We may need to package it up for inclusion in an IP purchase.
All these places where the sequence is needed. And all these people, writing the same sequence, perhaps in different contexts and different languages, but otherwise executing redundant efforts. And hopefully all getting them right. And then, when changes come, all dropping what they’re doing and patching whichever version of the code they own. And hopefully getting it right.
What you want is one person to write the routine – once – and then deliver it to everyone else. Problem is, there is no one language to rule them all – at least not in the sense that you could ship one file and everyone’s good. No, this guy needs C, that guy needs VHDL, she needs Verilog, he needs IP-XACT…
Since there isn’t one super-language, then the next best alternative is for a tool to address this. Yeah, this is a really specific, narrow problem, and yet, for an SoC, the register set and how they participate in some very basic operations are fundamental to how the system works. Get one little thing wrong, and all kinds of behaviors can break down.
This is what Agnisys has tackled with their iSequenceSpec tool. Provide a way to specify the sequence to the tool and then auto-generate code in all those different languages.
Of course, we’re talking about sequences affecting various registers hanging off the bus. How do we define that register set? Well, you can do that in a few ways, perhaps in your own language, or you can extend the abstraction here as well, using their older tool, iDesignSpec. From one of those ways, you get the registers. Then you can refer to them in sequence definitions.
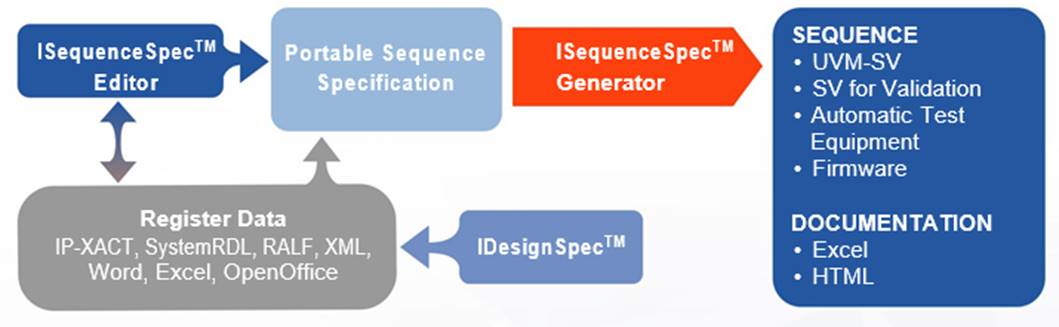
(Image courtesy Agnisys)
You might think of it as a crude language, although it’s built as a plug-in module for Word or Excel. What you’re getting is tabular structured text: this instruction goes in this row; the next instruction goes into the next row.
The format has enough power to handle loops (which can be automatically flattened) and decision branches. You can specify wait states. You can generalize further by providing arguments. You can even define sub-sequences that you can then invoke in other sequences for in-line instantiation.
This is where you need to spend the energy making sure it’s correct – everyone downstream of you is counting on you. There’s a possible opportunity for verifying sequences using formal technology, but that’s just in the discussion phase at this point; OneSpin has been taking a look at this. However you do it, proving your sequence clean at this level means that everywhere it ends up will be correct by construction.
So this abstraction gives you complete portability into all of the environments we’ve imagined (and assuredly more than those). But it also ties back into the encapsulation question. Given thoughtful definition, this series of sequences can act like an API: you’re taking low-level microcode, if you will, and building a set of routines so that no one else needs to build them from the lowest level. In whatever context, higher-level code can then simply refer to the routine.
If you plan that way, then whenever there’s a change, you make the change in one place, generate all of the actual code versions of the changed sequence, and ship them to the folks that need them. If the change affects only the contents of the sequence, then you can literally replace an old file with a new file and you’re done. If the change affects the interface, then, of course, the calls to the routine need to change as well. Abstraction and encapsulation for the win.
More info:



What do you think of Agnisys’s approach to register sequence specification?