


A funny thing happens when things get cheaper. Suddenly they find a bazillion uses that no one ever thought of before.
The typical American trajectory of price reduction means that something rare and valuable will eventually become accessible and common and then, ultimately, will become disposable. Think razors, once the domain of the professional who knew how to wield one without drawing blood. Now? Not only the blade, but the entire unit is available in a disposable version.
But something else happens in the mid-range – the “accessible and common” portion of the life cycle. Suddenly we start finding new ways to use some product (or marketing sells us on the new ways). Take baking soda: is there anything it’s not useful for? I mean, heck, baking is passé, and we’ve all got one in the fridge (OK, so it’s been in there way to long, but never mind). But I’m sure that Hints from Heloise (which would now be called, “Household Hacks from Heloise that will Change Your Life Forever OMG!”) would have dozens of ways to put the lowly chemical to work.
Well, we’re entering that realm with MEMS. With today’s focus being microphones.
Mics used to be either super cheap (think those old cassette players in the 70s) or broadcast quality. We still have the high-end mics, and they make a difference, but the low end is being transformed by MEMS microphones. And here’s the kicker: as the price comes down, why make do with one when many will do?
The plain fact is that multiple mics, given suitable processing, can provide better sound than a single mic. But, as we’ve seen before, a single extra mic, properly positioned, can also be used to quash background or audience sounds. And multiple mics, judiciously aimed, can handle beam-forming (although, as we’ll see, there’s some nuance to that). The point is, however, that MEMS mics are bringing higher quality to less expensive applications.
So why are we talking about this now? Because XMOS has brought forth the ability to manage a microphone array – essentially, the capability of their xCORE-200 family to handle multiple audio streams, acting as what you might call an “audio hub” (by analogy with sensor hubs). For applications requiring always-on sound detection, for instance, the lower-power audio hub would wake a more substantial application processor only when necessary.
The real question that popped into my mind upon seeing this was, what would one use 32 microphones for? And why not 33 or 31? In other words, how do you know how many microphones to use?
Let’s start by saying that 32 isn’t a magic number, other than it’s what made sense from a die-size standpoint for XMOS’s chip. They’ve seen applications with 64 mics, but they would expect most to be less than 16, or even 10. That said, the question has inspired some further thought about sound processing.
One final clarification: this isn’t XMOS getting into the MEMS business. They don’t make the mics. Their angle in the game is the chip that processes the output from the mics. That’s fine as far as we’re concerned for this discussion, since it involves the whole audio subsystem.
Microphones as cameras
The immediate image that came to mind when picturing beam-forming applications was by analogy to a camera. A camera captures light signals; a microphone captures audio signals. But, compared one-on-one, they don’t quite align.
Cameras have a number of characteristics that are largely determined by the design and quality of the lenses. Key parameters are:
- Shutter speed/”film” speed: how sensitive is the sensor to light, and how long must it be exposed to the light in order to capture a high-fidelity image?
- Focal length: at what physical point is the image most in focus?
- Depth of field: what is the distance both behind and in front of the focal point that will also appear to be (mostly) in focus? A small aperture (f-stop) means long depth of field; a wide aperture means short depth of field.
- Resolution: how many pixels are there within a given space? In other words, what’s the smallest feature that can be captured with good fidelity?
- Contrast: what’s the range of intensity in the image? Ignoring color, or speaking solely in terms of color value, is everything more or less in the gray middle, or are there white whites and black blacks? Or, in the extreme, only blacks and whites and nothing in the middle?
- Noise: this is particularly evident with digital cameras; it’s the speckles that can show up, especially in low light with high ISO settings.
I’m sure there are other fiddly things to pay attention to, but I’m not a pro photographer, so I won’t wade where ignorant. (Much… ok, you got me…)
A single microphone does not have these characteristics. It simply registers every little vibration in air that it detects, regardless of source or direction or importance (within the limits of the mic’s capabilities).
But when you arrange multiple microphones, then it starts looking more like a camera. It’s tempting to make the analogy that a single mic is like a single pixel. The ability to combine the streams of two mics to get a higher-resolution single stream seems different from what happens with pixels, although it does seem to be similar to the super-resolution concept in computational photography. In that case, two successive images, with either the subject or the camera slightly moved, can be combined into a single higher-resolution image.
The idea with beam-forming is notionally simple. You place multiple microphones in some physical arrangement. Each will detect all the sounds around it, but each stream will be slightly different. They’ll have items in common, and by shifting the time base of each microphone, aligning the shared features of interest, and strengthening them while suppressing individual mic differences, you can literally focus your microphones on a specific target – one that might be far away, with lots of noise in between.
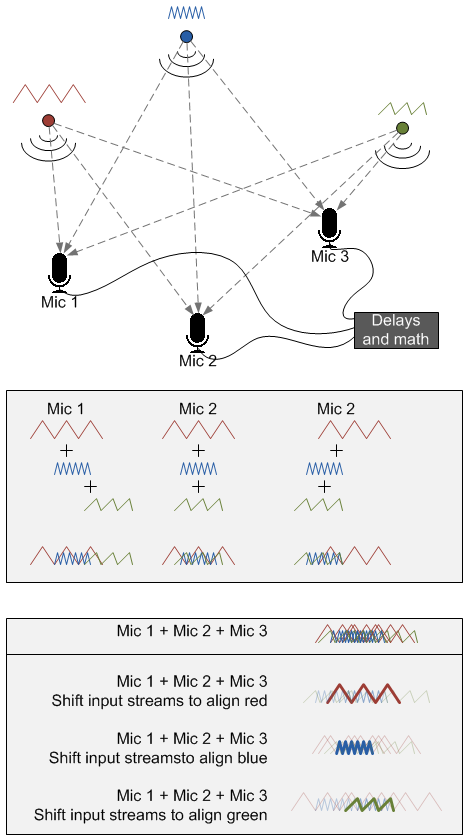
In the figure above, I try – conceptually – to illustrate this, with the caveat that I’m not an audio expert. But it’s possible to take a stab at this by gedanken. I show three sources, color-coded for your viewing convenience. Each of them makes a different sound (the mini-waveform). There are three mics as well. (That both sources and mics number 3 isn’t important – could be any numbers.)
All three mics hear all three sources, although the timing is different (as well as the amplitude). My big cheat here is doing “addition” by simply overlaying waveforms, which, of course, isn’t correct. But I’m too lazy to do the actual addition. So you can see the signal for each mic (as well as how it’s composed).
After adding the individual signals for each mic, I then add the mic signals together. If I just do it straight, it’s a jumble. But if I shift the timing around to align the waveform of interest (I show all three options), then you suddenly get a strong signal for what you want, while the rest becomes background (and could be filtered away). Note that, consistent with my cheat, I don’t show the aligned signal as having higher amplitude, but as having a thicker line. Graphic license… hopefully the point comes across.
To be clear, I don’t know what actual math is used. I used addition because it easily illustrates the point, but it may well be that addition is insufficient and that other more sophisticated techniques are required. The saying, “If it were that easy…” comes to mind. XMOS’s solution does include delay lines, so the time-shifting thing is likely part of the answer.
This is referred to as far-field audio sensing, and it aims to solve the so-called “cocktail party effect” problem. We humans can isolate a single voice in the middle of a cocktail party having lots of voices; this has been notoriously hard to replicate by artificial means. But we’re getting there.
OK, so having our setup in place, we can compare this microphone array to that of a camera, correlating the parameters I listed above.
- Shutter speed/”film” speed: this would be the microphone sensitivity. How readily can it detect a signal?
- Focal length: the point at which the array of microphones focuses; we accomplished this above by shifting the streams to align the signal emanating from the focal point across all mics.
- Depth of field: the farther apart the microphones are (that is, the wider the aperture), and the more they’re arranged in some sort of a semi-circular configuration (or parabolic? Or hyperbolic? – no wait, that would be marketing), the more it can isolate a specific point. With a long depth of field (small aperture), lots of things in a particular direction will be “in focus,” so you can really discriminate only the direction of the source of interest, not the distance. If you have a short depth of field (wide aperture), by contrast, you can figure out both the direction and distance.
- Resolution: Just as more pixels give more visual resolution, so more mics would provide more audio resolution (especially if arranged in three dimensions).
- Contrast: this is starting to stretch the analogy somewhat, but this can be related both to the dynamic range of the mics and the ability to distinguish the different streams. If all of the sources are making pretty much the same sound, or if the desired audio feature resembles the background, then there’s not much contrast, and isolation would presumably be more difficult.
- Noise: this would be embodied in the signal-to-noise ratio (SNR), and the SNR is all-important. It’s about amplifying the signal of interest and quashing everything else.
The XMOS approach
This is, of course, all conceptual. When discussing the topic with XMOS’s Mark Lippett, he said that specific placement and processing of mics is very much application-dependent, and finding the right formula for a specific task involves much real work.
He also noted that most applications that they see have the microphones placed close together. This gives a long depth of field, meaning that they can get direction, but not distance. Bear in mind, the concept of “narrow” is relative to the focal length. If you’re picking up sounds from 100 yards away, then your aperture would need to be somewhere on the order of hundred(s) of yards to determine distance. If your focal length is an inch away, then you can get short depth of field with a much narrower aperture. But… it would be hard to call that “far-field.”
Of course, when you talk microphones, the first gadget that comes to mind is the phone. But that’s not XMOS’s target. It’s a notoriously difficult platform to break into, and the XMOS power profile is better suited to “tethered” equipment – devices with a power cord connected to the mains. That said, he noted that the xCORE-200 family has rampant clock gating, so that, while you can’t literally power down individual cores, inactive ones consume very little power.
So if not phones, then what? They’re going for voice recognition as a user-interface mode in IoT devices like smart TVs. Their current hero appears to be the Amazon Echo. Part of the model is passing the audio stream up to the cloud, where heavy processing – and even machine learning – can generate the appropriate machine instructions that are sent back down.
Of course, this creates a situation where an always-on device is sending everything it hears up to the cloud. I’m sure no one would start rummaging through that or listening in for anything other than the intended, private purpose. No data will be sent to marketers, and the feds will never sue to force a company to hand over the audio streams, right?
Naturally, those considerations all depend on how an application is deployed and the intentions of the company (is the business model to sell equipment or to sell data afterwards?). But it’s something of an eye-opener for people with, say, a TV in the bedroom, to realize that every sound is being stored on a hard drive a thousand miles away…
The answer to this, of course (and perhaps this is happening), is to do the basic processing locally, contacting the cloud only when a relevant sound (like a command) is detected. (How to prove to people that you’re truly doing that might be trickier…)
As to XMOS’s involvement in voice recognition technology, they don’t consider themselves specifically in that business. They’ve been doing audio for years; what’s changed is that they now have xCORE-200 devices with improved DSP capabilities and with their own specific PDM-handling firmware, so they claim to handle the microphone processing from the bottom up. At some point, they hand over to voice recognition folks that are working from the top down.
They have put together a dev board that can accommodate up to seven microphones, for use in developing algorithms and applications.
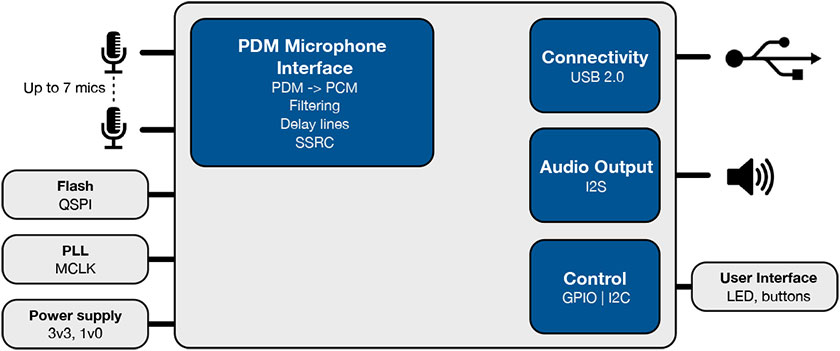
(Image courtesy XMOS)
The microphones are on the bottom, in fixed locations, so this isn’t so much for experimenting with the location of the mics as it is for optimizing the algorithms.

(Image courtesy XMOS)
XMOS will be announcing specific partnerships over time; for the time being, “partners” is an amorphous class of companies that work with XMOS to produce a variety of audio solutions.
But it’s with dev boards like this that tinkerers and inventors can start to explore the bazillion applications that might now be possible with high-quality, inexpensive microphones. Voice recognition could be just the start.
[Note: updated to reflect the fact that what looked like mic jacks for relocatable mics aren’t that. The mics are fixed on the bottom.]
More info:



So… what would *you* do with 32 mics?