

 We’ve looked at the DDS protocol before, but in a recent extended LinkedIn discussion that responded to a prior protocol article, RTI CEO Stan Schneider focused in hard on “data-centricity” as a key distinguishing feature of DDS. While that sounds good somehow, I had a hard time getting a good sense of what that actually means.
We’ve looked at the DDS protocol before, but in a recent extended LinkedIn discussion that responded to a prior protocol article, RTI CEO Stan Schneider focused in hard on “data-centricity” as a key distinguishing feature of DDS. While that sounds good somehow, I had a hard time getting a good sense of what that actually means.
Internet-of-Things (IoT) messaging protocols operate under a variety of “patterns” or styles. At this point, few use the old “remote procedure call” (RPC) style that might feel comfortable so an old-school programmer. Such messages consist of commands: “Set the temperature to 72.” “Turn off the fan.” “Report current humidity of 65%.” It’s like calling a function with parameters. You might expect an API to yield commands like, “SetTemp (Thermo15, 72);” or “SetPower (Fan25, OFF);” or “Report (‘Humidity’,65,CurrentTime(),MyLocation);”
By comparison, the more common publish/subscribe model is completely data-centric. Messages don’t have to have commands; they can simply publish new data, and both subscribers and Data Analyst can get access to that new data. So apparently “data-centric” is relative: pub/sub is more data-centric than RPC – and yet DDS is apparently more data-centric yet. So what does that mean?
I asked RTI for some code snippets so that I could see specifically what non-DDS and DDS code might look like. The example they did was of a calendar, and it illustrates a relatively nuanced situation. The scenario is one of having a meeting scheduled and then changing the date of the meeting.
The message-centric version of that is receiving, say, three emails over time. One sets the meeting date; the next provides the call-in details; and finally, another email changes the date. It’s up to you to manage what happens with that information – either sift through emails to figure out when it’s time to attend or manually add the details to your calendar.
The DDS-style data-centric equivalent (which they said implements a different pattern, called “Objective State”) would replace the messages with views of your calendar by others and by having DDS add a meeting, add call-in details, and then change the date.
In an abstract sense, the difference is who manages the state. In the email case, you (in the role of Application) are taking the messages, interpreting them (the equivalent of unpacking or “deserializing” or “unmarshalling” the contents of the message) and then manually changing the state of your calendar. In the DDS case, DDS manages the state for you.
Here is the equivalent comparison of “pseudocode” as written by RTI. For DDS, the code to manage the calendar and then view a meeting would look something like:

You’ll notice that there’s really no code for maintaining the calendar. Once you set up the “reader,” then all you do is read or view the state if you need to.
The MQTT snippet they submitted looks like this:
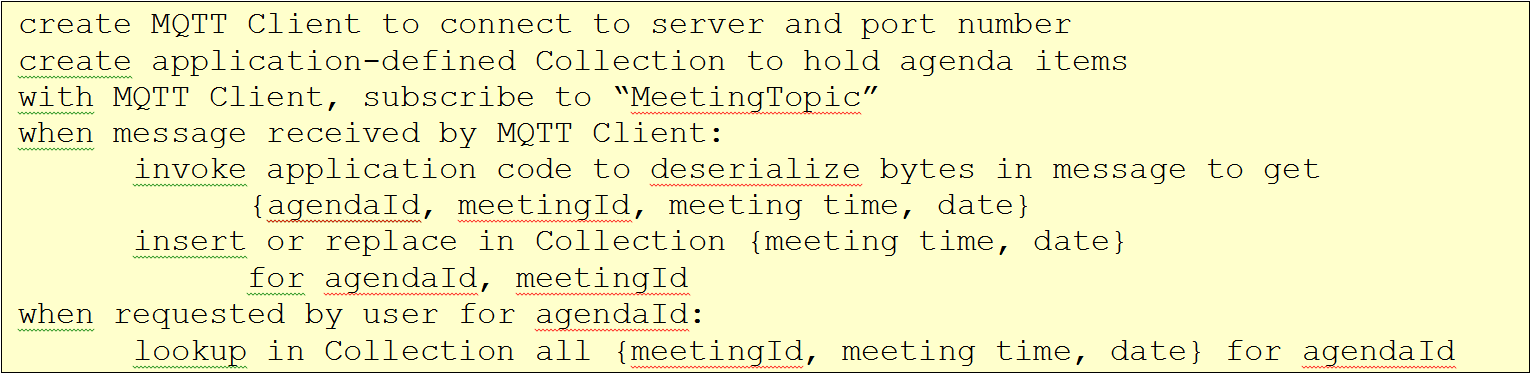
This has code to process messages as they come in – even though they’re the result of a “data-centric” subscription in a pub/sub system. It creates the Collection using standard memory-allocation techniques and then explicitly populates that data with information extracted from the messages. Those don’t show up in the DDS version because DDS handles that stuff opaquely.
That sounds good, but it still felt vague to me. In particular, I wondered about data ownership: with DDS, does DDS have to own all the data? If I use Outlook or gmail for calendaring, do I then have to relinquish it to DDS using some other format?
In a conversation with RTI, they clarified that DDS can link to other data sources via something akin to a symbolic link. So it’s not like DDS has to re-invent a complete new calendaring system – it can leverage what’s out there.
But it also gets more subtle since, as owner of my calendar, I need to be able to approve or reject meeting requests. So other people can’t just change my calendar willy-nilly. This is where we talk about topics.
Topics are the means by which data types are defined in DDS. “Temperature” might be one topic; “Calendar” might be another. You can associate keys for filtering so that you can distinguish between different thermometers or locations when subscribing to “Temperature” or between different people’s calendars when subscribing to “Calendar.” For each data type, there is a structure for that data within the internal DDS messages. That format could be different for different publishers of similar data, so when a subscription occurs, the data structure can be negotiated so that DDS knows how to parse updates.
So you might think, “Topic=’Calendar’; Key=’Bryon’” would give people access to my calendar for changes. But if you give them that, then they can simply change my calendar directly, without my intervention. So you might have two topics – “Calendar” and “Proposed Calendar” or something similar. Others can see your actual calendar; they then propose a meeting, publishing to “Proposed Calendar,” which you can see via the Proposed Calendar view; once you accept it, it gets added to your calendar and is now visible via the Calendar topic.
The difference boils down to where you’ll find the code that’s going to manage the data model. With DDS, the protocol middleware handles all of that. With many other protocols, the application code has to do it. That can make a difference if you have a big industrial setup with tens of thousands of nodes and a huge variety of applications to keep in sync (the scenario for which DDS is designed). If applications can simply reach in and read or write data without worrying about how and where it’s stored and how to keep it current, then there’s less that can go wrong and applications are easier to design.


