


So you’ve got some compute-intensive work to do, and you need the results really fast. OK, well, here: I wrote some code that takes full advantage of the nifty multicore processor so that it can run multiple calculations at the same time and get it all done so much faster.
Oh, wait, you didn’t want to use the CPU cores? You wanted to use the GPU? Dang… OK, well, let me go recode this and get right back to you.
Oh, you wanted to use the GPU only for that one part, but not the other? Hmmm… OK, gimme a sec here to go recode that.
Wait, you want it to be portable?? Not gonna happen.
We spend a lot of time on these pages talking about the Internet of Things and other really small, low-power, moderate-to-low-performance widgetry, but way on the other end of the performance spectrum, where nuclear power plants are installed beneath raised floors to run the coolers that cool the other nuclear power plant that runs the servers and the coolers that cool the servers, performance takes a back seat to nobody and nothing.
But how you write your code has always had some tie-in to your computing platform. Yeah, SMP (symmetric multi-processing) architectures allow, in principle, scaling to a few or to many processors (which eventually breaks down if you actually want to access memory), but we’re talking much more sophisticated than that. We’re talking heterogeneous – different processors, perhaps. Or graphics processors (GPUs). Or hardware accelerators for dedicated functions. Or all of the above.
You start playing with those kinds of options, and you’ve got some recoding to do to migrate between platforms. Which is why the HSA Foundation has recently revealed a new environment that is intended to enable a single meta-architecture for use no matter what the underlying hardware might be. It establishes requirements for SoC computing platforms as well as a programming environment and a runtime environment.
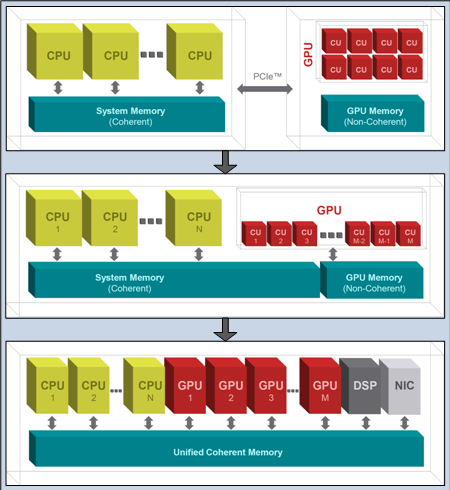
HSA stands for “Heterogeneous System Architecture,” and part of the motivation is clearly to unify the CPU and GPU worlds. They’re moving from an environment where the GPU lives off in its own private Idaho, writing home only via PCI Express or some other arms-length protocol, to one where GPUs and CPUs are siblings with equal standing – sharing a view of memory with other CPUs and engines.
(Image elements courtesy of the HSA Foundation)
And the goal is to do this while letting programmers continue in the languages they already know. This has required some give and take by various parties to make it work. In the end, the architecture has been flattened and simplified – even as new requirements are placed on the platform.
At a high level, the idea is that you have a main program with sections that are intended for potential parallel execution. Exactly what hardware will run those parallel bits of code may not be known to the programmer when he or she writes their code – that’s specifically the goal.
Software views, memory views, and not-so-secret agents
When I said that all engines are siblings, that’s not quite correct. There is a host CPU, and it’s going to run the main program as well as host the runtime routines. The trick then becomes: how do you take these parallel chunks of code (expressed in a language that has notions of parallelism) and defer the execution details so that we don’t fixate on a specific architecture too soon?
The answer to this lies in a new intermediate language: HSAIL (HSA Intermediate Language). HSAIL code is generated by compilers (it’s not code that must be manually written, so there’s no learning a new language). A complete program will consist of a mixture of native and HSAIL code. At some future time – it could be at final build, or it could be at runtime – the HSAIL code is “finalized,” or compiled into the native format of whatever the underlying execution engine will be. It’s a late- or just-in-time binding philosophy. Because HSAIL is independent of computing platform, the program becomes portable between platforms that share the same host CPU instruction set.
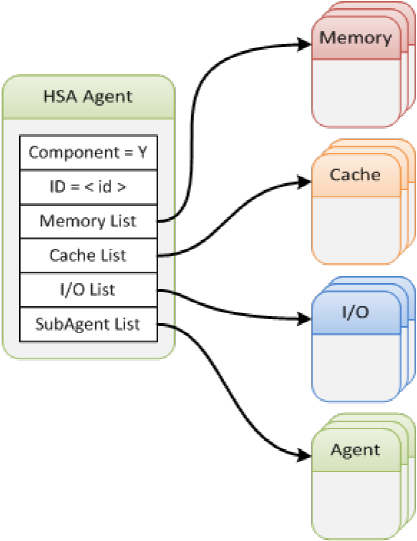
These engines for parallel execution are referred to as “agents,” and there are two kinds: kernel agents and… agents that aren’t kernel agents.
Kernel agents must support finalized HSAIL code, and they must be able to handle work item packets. These packets act as descriptors of what’s to be done and where the data and other resources are.
(Image courtesy HSA Foundation)
Kernel agents act, to a large extent, like SIMDs (single-instruction-multiple-data) on steroids. The biggest difference is that it’s not a single instruction; it’s a snippet of code. That snippet is a single thread and acts like it’s the only thing in the world. But by dispatching multiple jobs, you can run the same code on different data and chew through a “cube” of data quickly. This might mean that you have to focus on straight-line execution; branching (where a decision in one instance goes one way and that in another goes a different way) can force a rethink of how you partition the code.
Then there are the just-plain agents. These would appear largely to consist of dedicated hardware accelerators for things like encryption or calculating the femtopenny advantage to be gained by selling a stock option a few picoseconds ahead of the other guy.
From an SoC standpoint, kernel agents represent software instances; non-kernel agents are hardware. There’s no requirement that this stuff cohabitate on one piece of silicon, but memory considerations make it attractive to do so.
There are three types of memory envisioned in an HSA system: flat memory, registers, and image memory, which is handled separately for graphics. Memory can be allocated at different levels of hierarchy. At the main level, so-called primary memory is flat and coherent for all views. This has forced a change for GPU code that uses address offsets; HSA requires full memory addresses (but supports segmented addressing as an additional option).
In addition to primary memory, workgroups can be defined, with memory allocated to the group. This group memory cannot be assumed to be coherent with main memory. Memory can also be allocated as private to a single work item; it’s also not coherent with other memory views.
When dispatching a kernel agent, the calling program needs to populate the fields in the packet and then use what they call Architected Queuing to place the work item on the kernel agent’s queue. Creating a work item for a non-kernel agent is similar except that, because an agent’s function is fixed, there’s no need to point to a code location; only parameters are needed.
This Architected Queuing is a feature of the runtime, which handles kernel agent dispatch, non-kernel agent dispatch, and two kinds of barriers: AND and OR. The latter block further main program execution until either all or at least one (respectively) of the dispatched jobs has returned. Other runtime duties include error handling, initiation and shutdown, retrieving system and agent information, dealing with signals and synchronization, and memory management.
The HSA runtime typically would run below the language’s runtime facility. The language runtime would manage resources for the program; it would then call the HSA runtime for dealing with execution of HSAIL code.
SoC requirements
All of these software capabilities are possible only if the platform on which they run supports this model. So they lay out a laundry list of requirements for a conforming SoC (or SiP or however you cobble the system together), including:
- Shared virtual memory
- Cache coherency domains
- Flat memory addressing
- Consistent endianness
- Memory-based messaging and synchronization, including platform atomics
- Atomic memory operations
- Load
- Store
- Fetch-bitwise AND/OR/XOR-store (masking)
- Fetch-arithmetic op-store
- Exchange locations
- Compare and swap
- A uniform system-wide view of time and time-stamping (time should never go backwards or roll over)
- Low-latency user-mode queues
- Architected Queuing Language (AQL) support for enqueuing tasks
- Agent scheduling
- Pre-emptive kernel agent context switching with a maximum guaranteed latency
- Kernel agent error reporting
- Kernel agent debug infrastructure
- Kernel agent discovery
- Optionally, image operations
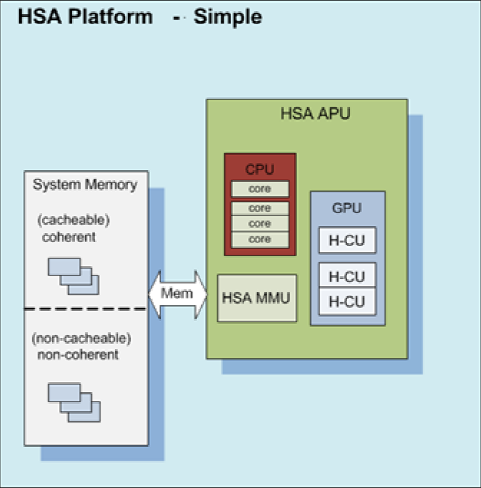
This set of capabilities can be applied to very simple platforms…
(Image courtesy HSA Foundation)
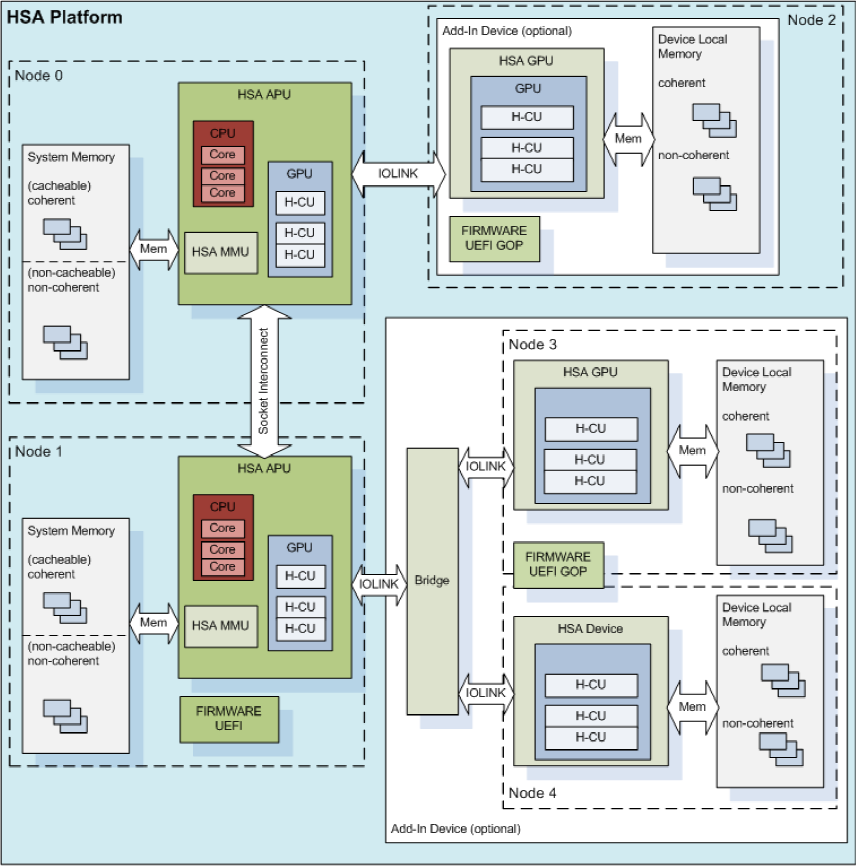
… or more complex ones. Architects have freedom to optimize as long as the requirements are met.
(Click to expand; Image courtesy HSA Foundation)
There are many more details available in the published specs, which are freely available. Tools are expected in the second half of this year, and actual products and conformance testing are expected later this year.
More info:
HSA Foundation (including specifications)





While HSA seems to focus more on the high-end of the spectrum, note that since years OpenComRTOS of Altreonic has delivered on the promise of transparent heterogeneous computing. See http://www.altreonic.com. Once the program is written (in C C++ or ADA), recompile and run to move Tasks from one node to another. Real-time is preserved through the use of global priorities, also at the communication layer.
Thanks for the heads-up. Do you see these two approaches as potentially competing or as focused on different problems?
In theory, once GPU’s are integral to the CPU and share the cache bus interface, then OpenMP would allow the C/C++ compiler to use both resources transparently.
The bigger problem is also teaching the OS to context switch those resources as well …. since as a peripheral the OS lacks the multi-tasking support necessary to share the resources transparently.
After that …. the compiler guys (vendor gcc teams) can fit OpenMP/C/C++ to the cpu/cores/gpu uniformly.
At that point, it’s really not that different than the typical floating point co-processor interface.