


It started with a review a few weeks back of a few stray new (to me) protocols that I was seeing. I did a cursory review of each one and called it good.
It sparked a long discussion on LinkedIn about various protocol capabilities. That discussion suggested to me that another layer of detail was warranted. At that time, I didn’t know what I was in for, or else I might have found something far more tractable to take on, like, oh, squaring a circle or proving Riemann’s Hypothesis.
But no, I blissfully entered the void. You might expect a void to be empty, but this void is overfull; it’s just devoid of structure and clarity. While it’s often said that the Internet of Things (IoT) is in need of standards, the area we’re visiting suffers from too many standards. Each one solves a slightly different problem, so maybe we do need them all, but man… it can be overwhelming to wade through. That’s frankly the intent of this article: to provide some clarity on the different protocols.
The good news is, I learned a lot of things, some of which I hope to pass on here and some of which we might discuss in future topics. It’s entirely possible that I missed or misinterpreted some detail; I’ll count on readers more expert in a particular area to provide corrections in the comments below.
One challenge I’ve found in particular is that everyone comes to this discussion from a different place. For the server-oriented guys, the constrained-resource standards aren’t useful because they’re missing too many features. For the tiny embedded devices folks, the big, full-featured standards are simply non-starters. REST-oriented folks work RESTfully; everyone else works RESTlessly. So part of my goal here is to correlate world-views, if that’s at all possible. I will specifically not be judging.
Filtering Protocols
In order to keep to a reasonable scope, we’re going to focus on messaging protocols. As we’ll see, “messaging” is still an overloaded term, but at least we won’t be focusing on low-level PHY or mid-level transport issues. There are some new lower-level protocols coming about – especially when it comes to so-called Low-Power/Wide-Area (LPWA) protocols. We saw one, briefly, with SIGFOX; LoRa is another that we can dig into. But the issues at that level are very different from the issues facing messaging-level protocols, so I don’t want to mix them up. We’ll do them another time.
There’s also a class of… well, “protocol” isn’t quite the right word – perhaps “platform”? – that threw me for a bit of a loop. It tends to involve things ending with “MQ”, although not all of them. “MQ” stands for “message queue,” and, with protocols supporting publish-and-subscribe, you’re publishing to a queue. The queue resides in a broker, and the broker ensures that your message goes to all the subscribers.
That kind of broker may exist in the context of a single protocol. MQTT, for example, has brokers; CoAp would not. DDS can be implemented with or without brokers.
But I then got thrown when I came across something called RabbitMQ, which I came to via ZeroMQ and Nanomsg. While the latter two appear indeed to be messaging formats, the language describing RabbitMQ (and another I’ll list in a moment) didn’t seem to make sense. It sounded like it was implemented over messaging protocols like AMQP and MQTT. But AMQP and MQTT, as we’ll see, have very different characteristics. So what would a higher-layer be doing? Abstracting them both and… what, making them look alike?
A quick exchange with them exposed the origin of my confusion. RabbitMQ is a broker in a somewhat different sense. While it certainly maintains message queues, a big part of its job is to bring together parts of a system with different protocols. So a message coming in on MQTT destined for a server implementing AMQP gets translated in the broker.
Such a broker isn’t so much “atop” the other protocols as it is “between” them. As such, I haven’t included them in the comparisons. They’re implemented in servers, not devices or endpoints. They also tend to add features and have a commercial level of support.
Brokers I identified:
- RabbitMQ (largely an implementation of AMQP, but bridging to other protocols)
- ActiveMQ (which has its own wire protocol called OpenWire)
There are also a few standards out there implementing transport, either instead of or in addition to TCP or UDP. I struggled with whether they are really at the same level as the other messaging protocols. I decided they seem to be lower, so I’ll list them here and move on:
- Thread
- ZeroMQ
- Nanomsg
JMS also falls into the group that I’m not going to cover, since it appears to be a Java-only server-to-server protocol.
For the remaining messaging protocols, here’s how we’ll proceed. The goal is to get to a summary table, but first I’ll describe the features I’m going to include in the table (a sparse subset of all the possible features, believe you me!). Then I’ll do a quick summary of each of the protocols, and we’ll finish up with the table. Here we go…
The Features We’re Comparing
The table starts with the protocol name as well as its sponsor and the entity that has standardized it (not always one and the same). The features I’ve included might not be obvious, but the intent is to focus on some characteristics that would appear to make a difference in what you might choose. I’m sure there are other features that you’d like in the table, and maybe you think some of them are unnecessary. We’re happy to entertain all such thoughts in the comments.
Messaging “Pattern”
The most common one is publish/subscribe (or “pub/sub” – abbreviated “P/S” in the table). This pattern keeps endpoints at arm’s length, with a broker keeping track of who’s publishing what and who wants to see the data. Depending on the standard, the publisher may or may not know who is subscribing to its data. The “topic” is an important concept, since it forms the basis of a subscription, but it also gets to notions about whether or not you can directly “address” another device – something we’ll discuss in a minute.
The other common pattern is request/response (often abbreviated “req/rep”; shown as “R/R” in the table). This comes from the HTTP model: one side issues a request; the other side responds. It’s very different from pub/sub in lots of ways, not the least of which is that pub/sub tends to be data push; req/rep tends to be data pull. There’s probably a whole separate article about the differences in these approaches; for now we’ll keep this brief.
There are other patterns as well that are less commonly supported:
- Point-to-Point (or Peer-to-Peer), abbreviated “P-P” in the table
- ACTive (Availability for Concurrent Transactions) – seems unique to XMPP
- Pipeline (for aggregation and load-balancing, as examples)
- Survey (a single request for the state of multiple applications)
In fact, the only place I saw the last two explicitly mentioned was Nanomsg, which is lower level. That said, some protocols, like XMPP, allow for extensions, so you can sometimes build a new pattern over what already exists (which is how XMPP supports pub/sub).
Quality of Service, or QoS
Also called message reliability. This is a broad area with wide-ranging features. It deals with whether you just toss a message over the wall (in which case it may or may not get delivered) or whether you’re getting acknowledgments, with possible queuing in case a subscriber happens to be offline, and maybe with a time-to-live setting so that you don’t wait forever for that subscriber to come back in (and what should happen with undelivered messages).
There’s even some disagreement (surprise!) – one discussion says that MQTT’s highest level of reliability simply can’t work. We’ll defer a detailed discussion until another time.
Note that many protocols layer over TCP, and TCP itself has some level of delivery guarantee. So you might wonder why a protocol would need to do more. Well, apparently there are gaps in that guarantee, there can be delays in TCP realizing there’s a network problem, and there are certainly more elaborate schemes than TCP. So, in the table, you might see “TCP” as the QoS; that simply means that the protocol doesn’t specify its own QoS above and beyond TCP.
Security
As in, does the protocol define its own security? If not, how is security implemented? Many protocols rely on TLS/SSL; others push it to the applications; some use DTLS. We won’t get into the nuances of the different ways of doing this (yet another big topic); we’ll simply summarize.
“Addressing”
This came to me based on a newer proprietary protocol called SMQ from a company called Real Time Logic – and its prime motivator is that it makes it easy for one endpoint to address another directly. If you’re trying to turn on a particular device or get a specific measurement, then a general pub/sub topic (especially in a protocol without discovery) isn’t helpful – unless you want to have a separate topic for each device. And even then, without discovery, you may not know the IDs of any endpoints
In this context, if you want to implement code in a resource-constrained device, CoAp and MQTT are the obvious choices. If you don’t want the REST model (we’ll talk about that in a sec), then that leaves MQTT – and direct addressing is difficult with MQTT. So these guys created SMQ.
What I try to capture in the “addressing” column is this nature of addressing for each protocol.
RESTful or RESTless*
I struggled with how to represent this, because it really covers two related, but distinct, issues.
One is the style of programming. In general, I see RESTful APIs as being familiar and comfortable for web and server programmers who are used to dealing with HTTP requests and having to wrestle with load balancing and unreliable connections.
I associate the other style as being more familiar to embedded system programmers. These are “real” programming languages like C/C++ and Java. The difference is that, with REST, everything pretty much happens through four commands: PUT, GET, POST, and DELETE. Without REST, you have specific APIs that will depend on the protocol or implementation.
But language familiarity is really a surface-level difference. More fundamental is the difference in how application state is handled. With RESTless approaches, you assume either an ongoing connection or at least a predictable destination for sending messages.
State is implicit in RESTless messages: if you sent one message saying, “shut off the fan” and then another saying, “power down,” then you’re assuming a conversation over time, where first the fan was shut down and then the device was powered down. Your assumption is that the fan was indeed successfully shut down (just because the message got there successfully doesn’t mean that the action successfully completed).
The REST architecture makes no such assumptions. There is no such notion as a long-term connection or conversation. You request something, you get an answer, and you’re done. Call it the Dory factor: even though you might have just executed a “shut down the fan” instruction, the system has no memory of that after passing the message along. Each message is as fresh and new as the first one ever sent. “Oh look, a message! Cool! Oh, look, a message! Cool!” Not, “Oh, look, another message” – there’s no notion of “another” if you don’t remember the prior one. In fact, a load balancer might send the two messages to two different servers, which is why you don’t want to rely on one of them to remember what just happened.
You have to program differently in that case. In the RESTless case, you might have some sort of application-level acknowledgement. In a REST setup, by contrast, you might need, for instance, to test the fan first to make sure that you don’t accidentally power down without turning the fan off first. Another typical example is changing a setting – say, a temperature. If you say, “Decrease the temperature by 1 degree,” then it may or may not happen in an unreliable setup. If you say, “Set the temperature to 65 degrees,” then the endpoint can check its own current setting and either decrement or not (or even increment).
This is another big topic, with proponents and detractors on both sides. We’ll leave more depth for another day. Suffice it to say that you might not be happy if you pick the wrong approach for your application and programmers.
Constrained resources
Some protocols are specifically designed for devices with few resources, some are not, and some may allow for constrained implementations if you omit enough optional features. What constitutes “constrained” will vary by perspective. Some folks think in terms of a few thousand bytes of code; according to RTI, the constrained version of DDS can approach 500K bytes.
The Protocols (in the order presented in the table)
MQTT is intended for constrained-resource devices. It comes from IBM; detractors will say that it’s not getting any traction. It’s been implemented over TCP and Websocket. It needs an ordered, lossless, bidirectional connection.
It has basic QoS services:
– Deliver at most once (might not get there)
– Deliver at least once (might get a duplicate)
– Deliver exactly once – this is debated as not being possible to implement. We’ll revisit the debate another time.
Clients initiate connections; servers act as brokers. Topics serve for subscriptions. As far as I can tell, there’s no discovery process – which is why addressing a specific device is difficult. There are five packet types: connect, publish, subscribe, unsubscribe, and ping. There is some provision for abnormal events as well as some basic lifetime management for messages. Security is largely through best practices.
CoAp is the other well-attested protocol for small devices – and it uses the REST model. This is largely HTTP, with some modifications – in particular, the specific meanings of the four REST commands are slightly different from their HTTP meanings.
It runs over UDP, which has no delivery guarantees. This is where the REST nature can be useful. Messages can optionally be marked as “confirmable” if you want an acknowledgment of receipt (with a time-out and exponential back-off resend model). Messages can be uni- or multi-cast.
XMPP actually started as the thing you use to do instant messaging. It’s an XML-driven protocol that’s fundamentally point-to-point (via a server), but there’s an extension to implement pub/sub. You can confirm the presence or availability of a specific endpoint, and endpoints must support discovery.
Data is organized into “stanzas” sent via persistent XML streams over long-lived TCP connections. Addresses are global and are specified as JIDs (which stands for “Jabber ID” for historical reasons). A specific extension has been made available to improve on TCP.
AMQP is a big protocol. Period. It would appear more suitable for server-to-server messaging. It includes the following capabilities:
– Credit-based flow control (to slow traffic if a bottleneck is backing up)
– Queues (in case a subscriber is down)
– Persistence and availability features
– Transactions (series of commands executed atomically)
– Multiplexing (easier to get messages through firewalls)
– Trusted entity authentication through Kerberos
It has its own link and transport layers above TCP/IP. Messages are layered above all of that. There are sophisticated reliability features – far more than we could discuss here.
DDS, or distributed data service, is something we’ve talked about in more detail before. It can be implemented with or without brokers, and its central defining characteristic is data-centricity, as opposed to message-centricity. We discuss the distinction separately. It’s also intended to be extremely scalable; it’s an industrial-strength system.
Security has been one hole in the DDS infrastructure. It’s being addressed, and a security scheme is currently in beta pending finalization.
SMQ is the proprietary Real Time Logic protocol that responds to perceived weaknesses in both MQTT and CoAp for small devices. Its key distinguishing feature is the use of an “ephemeral ID” assigned by the broker and included in a message so that responses can be directed to that specific endpoint. The intent is that it’s much easier to control or communicate with a specific node this way.
Connections start via HTTP being “upgraded” to a Websocket connection (basically, TCP with a notion of higher-level packets; we’ll discuss in more detail another time).
The implementation is written in the Lua scripting language and is available as part of Real Time Logic’s suite of stackware for embedded devices. That said, they indicated that, if there’s interest, they might be willing to open it up.
HTTP/2 is the next rev of HTTP. Apparently too many people are using the “dot” or “v” or “rev” nomenclature now, so, in the way of any good hipster annoyed that their secrets have gone mainstream, now we’re doing “slash” to indicate revision.
This isn’t a messaging protocol per se, but there are suggestions in a number of blogs that some of the performance limitations of the past may be solved with this revision, making it appropriate for the IoT and communications with the Cloud. It supports streams and “server push” – while a server still can’t initiate a connection (only clients can do that – important for security), it can initiate streams within an open connection.
Headers were one of the big issues with HTTP; there’s a Huffman encoding scheme to compress them for small devices with limited resources; HPACK is an implementation of that capability.
AllJoyn implements a “proximity network” – a notion we discussed last year. It operates only on a local network, with possible future provision of gateways to Zigbee, Z-Wave, and the Cloud. This is for your stereo to talk to your speakers and other such point-to-point close-in interaction. It’s largely based on the remote procedure call (RPC) model, although their Data-Driven API allows pub/sub, with messages containing data or facts rather than commands, and with the data structure embedded in the message.
Each endpoint implements a router – except for small embedded devices, which, through the use of a thin client, can leverage a router on some other device. Discovery is implemented to the point of massive introspection: methods, properties, signals, objects, object paths, events, and actions can all query their own nature. The Internet of Navel Gazing.
There’s a base core library, over which they’ve implemented a higher-level Services Framework Library. The latter is not required, but it’s the only way to guarantee interoperability.
Finally, STOMP: I debated whether this belongs here or with the brokers (except that it is a protocol) or the transport protocols (although it does seem higher level than, say, ZeroMQ). In fact, it does feel more like a server-to-server enterprise-level protocol like JMS – not so much for the IoT. But it is language-agnostic, so I decided to include it here.
STOMP stands for “Streaming (or Simple) Text-Oriented Message Protocol.” Its focus is simplicity and interoperability. It’s referred to as lightweight, although my sense is that this means it’s easy to implement and get going – it doesn’t necessarily conserve resources in the way an embedded device would require.
The design philosophy is similar to HTTP, but it’s not RESTful. There is a relatively sparse set of commands: Connect, Send, Subscribe, Unsubscribe, Begin, Commit, About, Ack, Nack, and Disconnect.
For all of these protocols, high-level characteristics are summarized in the following table.
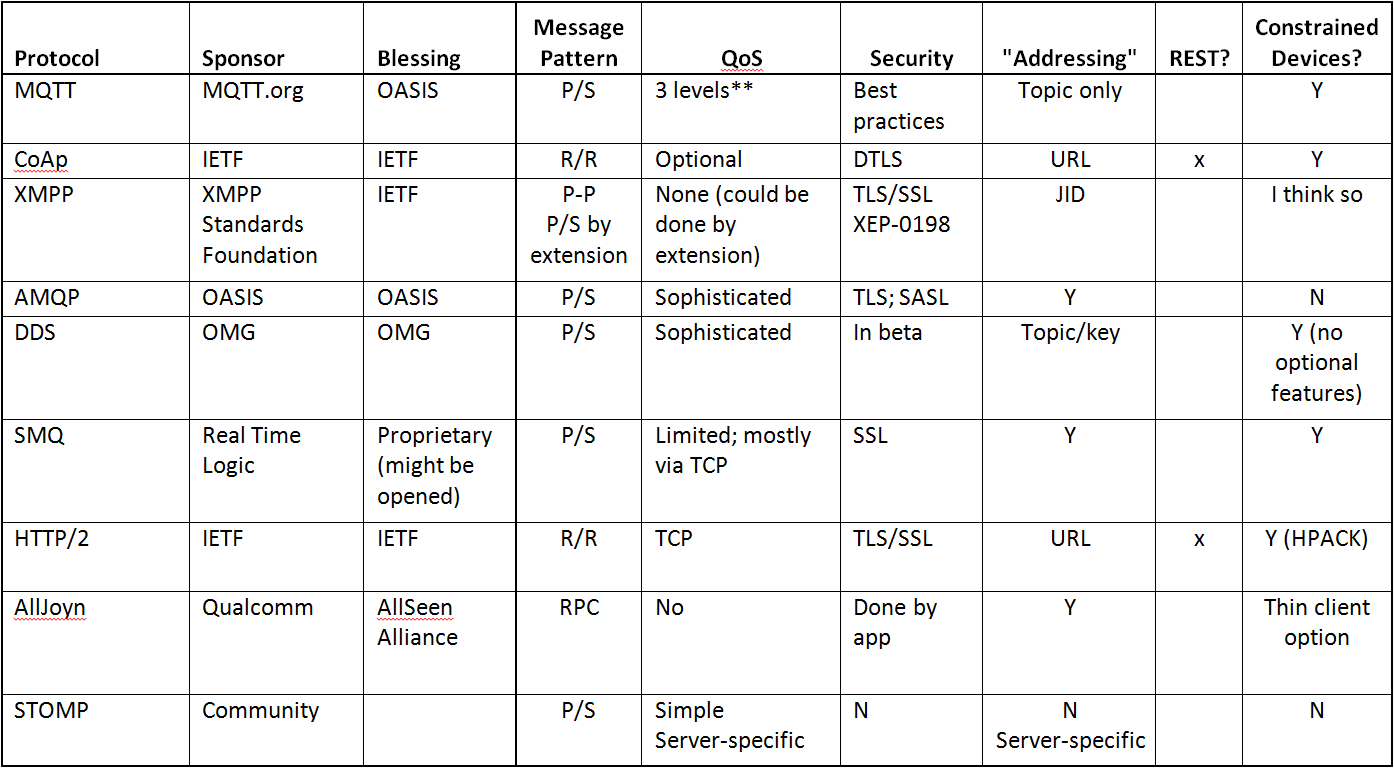
P/S=Publish/Subscribe
R/R=Request/Respond
P-P=Point-to-Point or Peer-to-Peer
RPC=Remote Procedure Call
* To be clear to any newcomers, there is such an official thing as RESTful; there isn’t such a thing as RESTless – that’s just me being a wiseass. But it’s also more efficient than constantly writing, “things that aren’t RESTful.”
** As discussed above, one of the levels is debated as unrealizable.
More info:





We covered a lot of messaging protocols (and associated concepts here). Would these cover your needs, or are there still unmet needs?