


There are a lot of reasons why we can create so much circuitry on a single piece of silicon. Obvious ones include hard work developing processes that make it theoretically doable. But someone still has to do the design. So if I had to pick one word to describe why we can do this, it would be “abstraction.” And that’s all about the tools.
In fact, my first job out of college came courtesy of abstraction. Prior to that, using programmable logic involved figuring out the behavior you wanted, establishing (and re-establishing) Boolean equations that described the desired behavior, optimizing and minimizing those equations manually, and then figuring out which individual fuses needed to be blown in order to implement those equations. From that fuse map, a programmer (the hardware kind) could configure a device, which you could then use to figure out… that it’s not working quite like you wanted, allowing you to throw the one-time-programmable device away and try again.
I got to Monolithic Memories right as their PAL devices were taking off as the first high-volume programmable logic chips. There were two keys to their success: the fixed-OR architecture, which provided higher speed at lower cost, and their new PALASM software. That software allowed users to specify their designs not at the fuse map level, but at the Boolean level, with the software figuring out the fuse map. Logic manipulations and minimization were still done by hand.
That is, until software tools improved to include minimization. And then, to my amazement, I watched newcomer Altera’s MAXplus software convert between D, T, and J/K flip-flops automatically to minimize resource usage and allow functions that I thought wouldn’t fit to work quite nicely.
So, first came the new abstraction level – Boolean – and then came the ability to optimize at that level.
This has been going on for years with chip design. Like a Russian nesting doll: each layer of abstraction eventually gets abstracted itself into something yet higher. But each such transformation involves a modicum of friction. That’s because each new abstraction comes about thanks to newly-minted algorithms that can push current computing technology to its limits.
So it might take hours on beefy machines to achieve the conversion from one level to another, but that beats weeks of error-prone manual work. Even so, especially early on, you have to check your work. The algorithms have bugs or holes or whatever, and sometimes you have to take the result and dink with it manually to get a correct or more efficient result. So optimizations typically happen at lower levels. Which is unfortunate, since it breaks the link between the lower-level design and the original abstracted version.
But here’s the thing: high-level optimizations will be much more effective than lower-level ones. A better algorithm will save way more silicon than tweaking gate widths will, as suggested by the following anti-pyramid. Those highest-level optimizations tend to be done manually; below some line, the tools can automate it.
From a tools standpoint, you also reduce the number of logical objects you have to work with at higher levels, which creates efficiencies in memory and processing; that’s what’s behind the “#Objects” scale on the left.
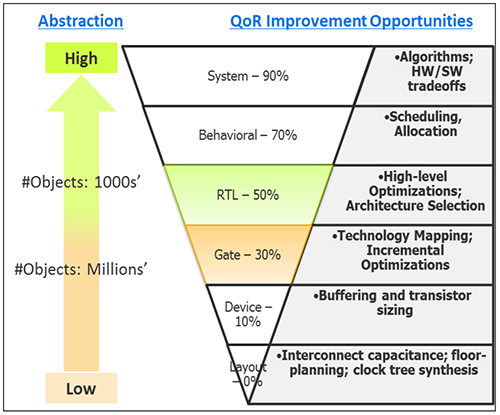
Image courtesy Mentor Graphics
So chip designers, who have benefitted from automated optimization at the physical and gate levels, might look forward to that automated-optimization line moving yet higher, from the gate level to the RTL level.
And that’s exactly what Mentor claims they have now with their new RealTime Designer tool. What lets them do this today, when it wasn’t a thing before? Well, looked at simplistically, it’s because we’ve had lots of time since the emergence of basic RTL synthesis. In that time, algorithms have improved, and computing capability has ballooned enormously. So what would have been ridiculous to consider back then becomes tenable now.
We’ve already seen it with timing analysis, which used to be a big batch process that you ran all at once. Afterwards, you sorted through the results to see what needed fixing. Today, timing analysis engines run in real time, communicating with compilation tools so that timing-related decisions can be made by feeding smaller bits to the timing engine and making choices according to the results.
You may recall Oasys, a start-up company that made a name through much faster synthesis – and was then bought by Mentor. Just as happened before with timing analysis, this has enabled Mentor to speed up synthesis. Then, by keeping a placer running in the background (in the same spirit as keeping the timing engine handy), they can perform optimizations at the RTL level by seeing what their impact is during synthesis, rather than having to wait until synthesis is complete.
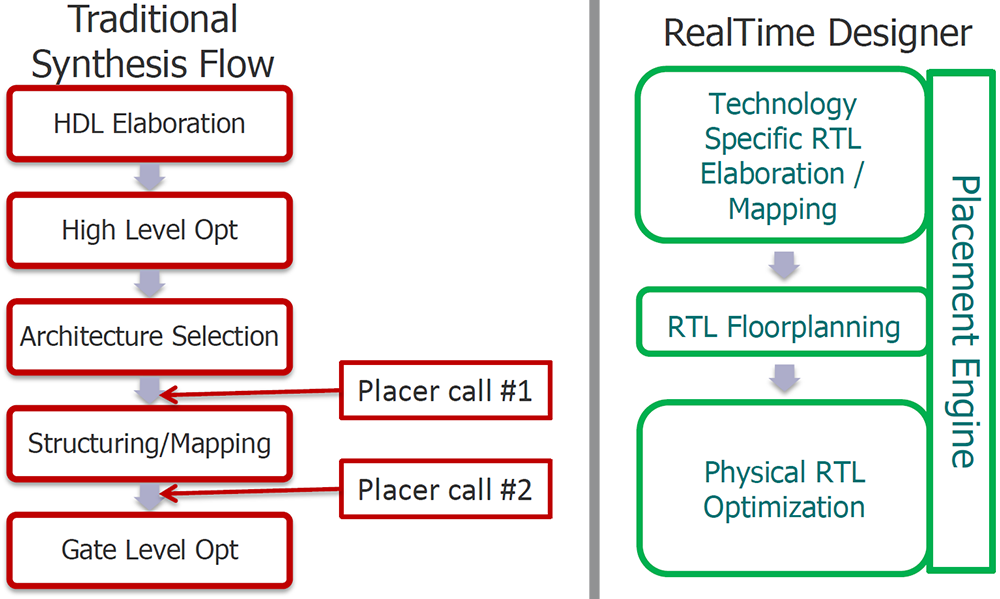
Image elements courtesy Mentor Graphics
It’s not just about pure synthesis, however; there are a number of things going on here, as described by Mentor. They characterize the existing process as one of doing basic synthesis first, using the results to cobble together a floorplan, and then using the floorplan to do “physical synthesis,” which is synthesis that takes into account more of the physical characteristics of the resulting layout. All with lots of iteration.
With their new flow, floorplanning and physical synthesis come together to deliver a result to the place-and-route engines that should provide far better results, ostensibly with no (or at least reduced) iteration. Mentor refers to this as a “place-first” approach.
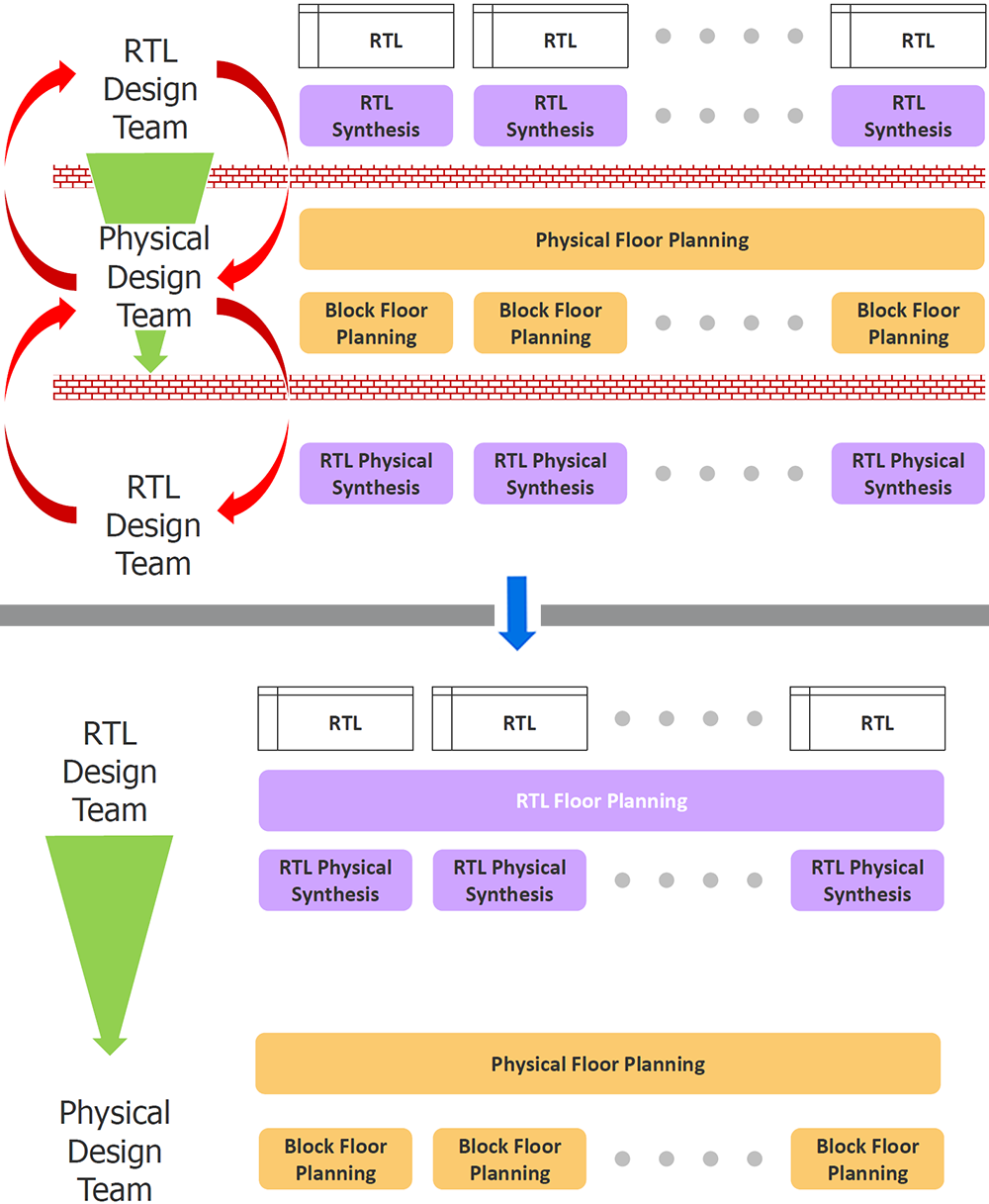
Image elements courtesy Mentor Graphics
Other tricks that improve results include automated dataflow-driven floorplanning and design-space exploration, both of which overlay the core synthesis.
If you haven’t run across the latter before, it’s a brute-force technique that acknowledges the reality that not all optimization can be done algorithmically. Sometimes you simply need to try a bunch of things and see which one ends up providing the best result. That means running a bunch of variations and then graphing the results to select the best one. This can be used for a lot of different optimization problems, but, in all cases, it relies on having fast enough processing to be able to run through all the versions in a reasonable time.
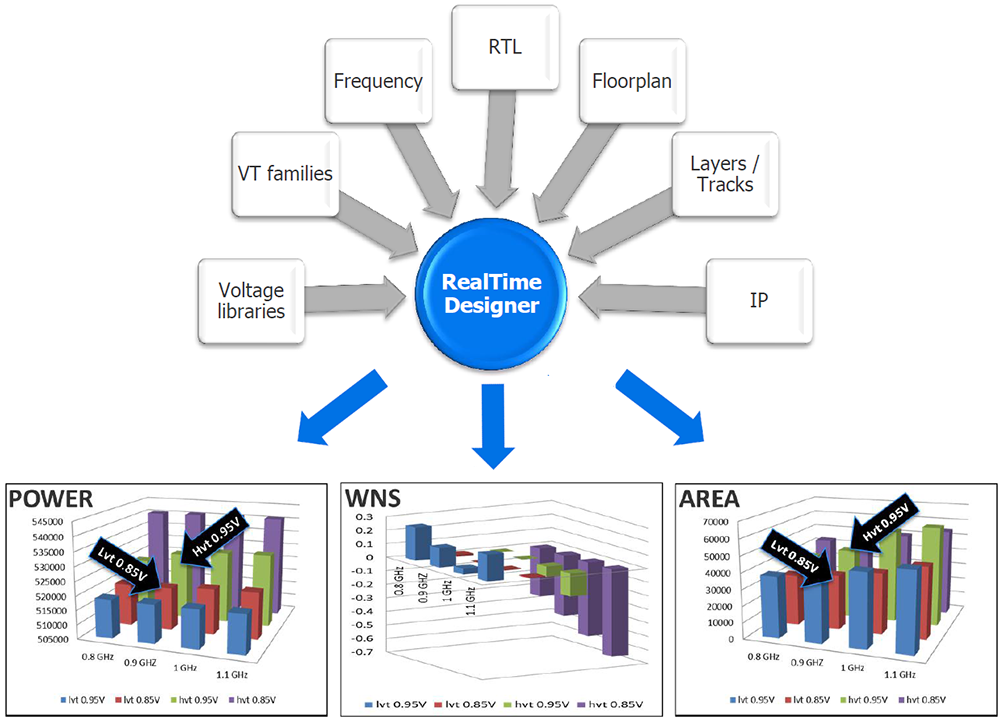
Image courtesy Mentor Graphics
“WNS” = Worst Negative Slack
The other caveat with design-space exploration is that the notion of “best” may not be well-enough specified for a computer to select the winner. If, for instance, speed is the only consideration, then the highest frequency (or lowest delay) wins, and a computer can do that (perhaps with the help of some tie-breaker rules). But if, as in the case of synthesis, you’re balancing power, performance, and area (PPA), then it may require a human to determine the best balance and make the final decision – at which point the processing can continue automatically.
This is indeed how Mentor implements their design-space exploration: it runs the variations, presents you with the results, and you pick one.
Put this all together, and they claim as much as 10 times faster runs and the ability to handle 100-million-gate designs (which they say might be exemplified by a big Tegra graphics engine from nVidia or a highly-integrated network processor). They say that they’ve run this on production designs at the 28-, 20-, and 14-nm process nodes.
Looks like our abstraction doll may have just been enclosed by yet another one.
More info:
Mentor Graphics’ RealTime Designer





What do you think about Mentor’s RTL-level optimization?