


The robots I grew up with on the silver screen were big clunky affairs like Robby the Robot, who first appeared in the 1956 film Forbidden Planet. Similarly, on the small screen, we had hulking contraptions like the B-9, Class YM-3 Environmental Control Robot, simply known as Robot, on Lost in Space.
Later, I was introduced to the concept of humanoid robots in the short stories by Isaac Asimov, which were gathered into two books: I Robot and The Rest of the Robots. I recently re-read both these tomes, and they are as enjoyable today as they were when I was a young sprout. While humanoid in general form, most of the robots in these books couldn’t be mistaken for human beings, unlike R. Daneel Olivaw, who appeared in Asimov’s later works, The Caves of Steel and The Naked Sun.
As I’ve mentioned on previous occasions, my wife, Gigi the Gorgeous, often inquires when we will be able to have our own household robot. Gigi envisages a humanoid-looking, AI-powered device that can help her with housework and gardening tasks, and accompany her to the grocery store, where she can instruct it to track down obscure, hard-to-find (occasionally nonexistent) items. I don’t know why she’s so fixated on this, since she already has me doing all these tasks (especially, now that I think about it, desperately searching for imaginary items in stores).
Just a short decade ago, I would have said that general-purpose humanoid robots were still a long way in our future. However, we’ve seen tremendous strides (no pun intended) within the past couple of years, both in terms of the electromechanical body—motors, actuators, sensors, balance systems, and lightweight structures—and the AI “mind” that allows these machines to perceive, reason about, and interact with the world around them.
Of course, making a robot walk, wave its arms, or perform carefully choreographed demonstrations is hard enough. But the really hard part—the part that has stubbornly resisted automation for decades—is enabling robots to intuitively interact with arbitrary real-world objects. Picking up a shiny metal component is different from grasping a transparent plastic bottle, which is different again from manipulating a floppy bag of vegetables or a screwdriver hiding in a cluttered drawer.
This is precisely the challenge that CynLr (Cybernetics Laboratory) is tackling. I just had a jolly interesting chat with CynLr’s co-founder and CTO, Gokul N A, who argues that robots need something far beyond conventional machine vision: they need what the folks at CynLr call “Object Intelligence.”
CynLr’s main R&D is based in Bengaluru (previously Bangalore), India, but the company has a global footprint, with a presence in Europe and the US to work with OEMs and large plants. I shared with Gokul that I was fortunate enough to have visited Bangalore, deep in the mists of time we used to call 2010, when I was invited to speak at the Embedded Systems Conference (ESC).
What I remember most were the wonderful people, the amazing food, the juxtaposition of gleaming technology campuses and grand old colonial buildings—vast red-brick edifices that looked as though they’d been designed by people who considered subtlety a personal weakness—and, of course, the utterly terrifying traffic.
Roads seemingly designed for two lanes of traffic in each direction somehow managed to accommodate three or four, accompanied by a rich supporting cast of scooters, tuk-tuks, buses, wandering pedestrians, and the occasional cow. Meanwhile, traffic lights appeared to be regarded less as mandatory instructions and more as cheerful signs of encouragement.
Gokul replied that a lot has changed in the one-and-a-half decades since my visit. Bengaluru’s technology boom has shifted into overdrive, the skyline has erupted with new developments, and the traffic has somehow contrived to become even… more exciting.
But we digress… The aim of object intelligence is to allow robots to understand and manipulate previously unseen objects in much the same way humans do. Think of a baby presented with a tray of objects of different shapes, colors, and textures. The first thing it will do is reach out, pick one of the objects up, squeeze it, rotate it, examine it, and… well… stick the object in its mouth, but CynLr isn’t asking its robots to go that far just yet.
Sitting on top of this object intelligence layer are systems such as CyRo, CynLr’s robotic manipulation platform, and CyNoid, a more generalized robotic embodiment concept intended to free robots from rigid, task-specific form factors.

The CyRo robotic manipulation platform (Source: CynLr)

The CyNoid robotic embodiment concept (Source: CynLr)
But let’s take a step back before we charge further forward. The problem with most current machine vision systems is that they are fundamentally based on recognition through repetition. Show the system enough images of an object—under different lighting conditions, from different angles, partially obscured, upside-down, scratched, shiny, dirty, or wrapped in reflective plastic—and it will (well, may) eventually learn to recognize that object reliably.
The snag is that this often requires absurdly large numbers of tagged training images. Worse still, the object may look radically different depending on viewing angle, illumination, reflections, shadows, or whatever happens to be sitting nearby. A computer mouse viewed from above looks nothing like the same mouse viewed edge-on. A shiny spoon reflecting surrounding objects can appear visually different from one moment to the next.
People, by comparison, handle these situations effortlessly. We don’t need to study ten million images of a spoon before we can recognize one lying in a cluttered kitchen drawer (this is one of my skills I’m most proud of, although I certainly don’t want to boast). Yes, I agree, this is certainly a good time for us to feast our orbs on a video of this in action.
One of the more fascinating aspects of my conversation with Gokul was his observation that humans may not actually understand their own visual systems nearly as well as we think we do. We make assumptions about how we recognize objects, then build machine vision systems based on those assumptions, only to discover that biological vision doesn’t appear to work the way we imagined.
For example, many people assume we primarily recognize objects using color. But color is astonishingly subjective. Consider the famous “blue-and-black or white-and-gold dress” internet debate that divided humanity into warring factions back in 2015. Or a little closer to home (by which I mean “my home”), my wife and I can stare at the same watering can, with me insisting it’s green while she remains adamant that it’s blue. Trust me, it’s green! (Take a look at my Do You See What I See? column.)
Similarly, we often assume that we recognize objects by their edges and outlines. Yet our brains effortlessly identify partially obscured objects, reflective surfaces, transparent materials, and oddly lit scenes that would leave conventional machine vision systems thoroughly bamboozled.
Gokul and his co-founder, Nikhil, have been working together for more than 16 years. They were building high-speed industrial vision systems tackling brutally difficult real-world problems long before today’s explosion of perceptive, generative, and agentic AI (see also What the FAQ are Perceptive, Enhancive, Assistive, Generative, Agentic, and Physical AI).
One example involved automated grain sorting. Imagine attempting to inspect and classify hundreds of millions of grains per hour as they tumble through space at high speed. The system had to identify damaged grains, stones, glass fragments, insect contamination, and other unwanted material in real time, then selectively blast the offending items away with carefully timed jets of air.
According to Gokul, the system had only around 56 microseconds to identify each grain, determine its trajectory, and decide whether it should stay or go. That’s “microseconds” with a “micro,” not “milliseconds” with a “milli.”
What makes this especially interesting is that so much of this work predated today’s AI frenzy. Back then, machine vision systems relied on techniques like template matching, convolutional filters, clustering algorithms, and support vector machines (SVMs) rather than today’s enormous neural networks.
According to Gokul, today’s robotics systems suffer from a fundamental architectural flaw: they insist on identifying and labeling an object before interacting with it. Humans don’t work this way.
As I noted earlier, a baby doesn’t freeze when presented with an unfamiliar object because it lacks a perfectly labeled training dataset. Instead, it reaches out, grabs the object, rotates it, squeezes it, taps it, waves it around, and generally uses it to annoy nearby adults.
In other words, the baby learns through interaction. CynLr’s systems employ a similar philosophy. Rather than relying purely on static images, the robot actively manipulates objects to gather more information. Motion becomes part of the sensing process. In many ways, this mirrors biological vision, which appears to rely heavily on continuous motion and active exploration rather than isolated static snapshots.
One demonstration Gokul showed me genuinely made me sit back and mutter, “Good grief, Charlie Brown!” The robot was presented with a tray full of reflective metal cutlery—spoons, forks, knives—the sort of visually chaotic scene that tends to give conventional vision algorithms nervous breakdowns.
Initially, the shiny overlapping objects formed a confusing jumble of reflections and highlights. But the robot selected one spoon, lifted it, and moved it through space while observing how the visual scene changed over time. Within moments, the system isolated the spoon from the background clutter. By actively manipulating the object, the robot effectively separated “what changes” from “what stays the same.”
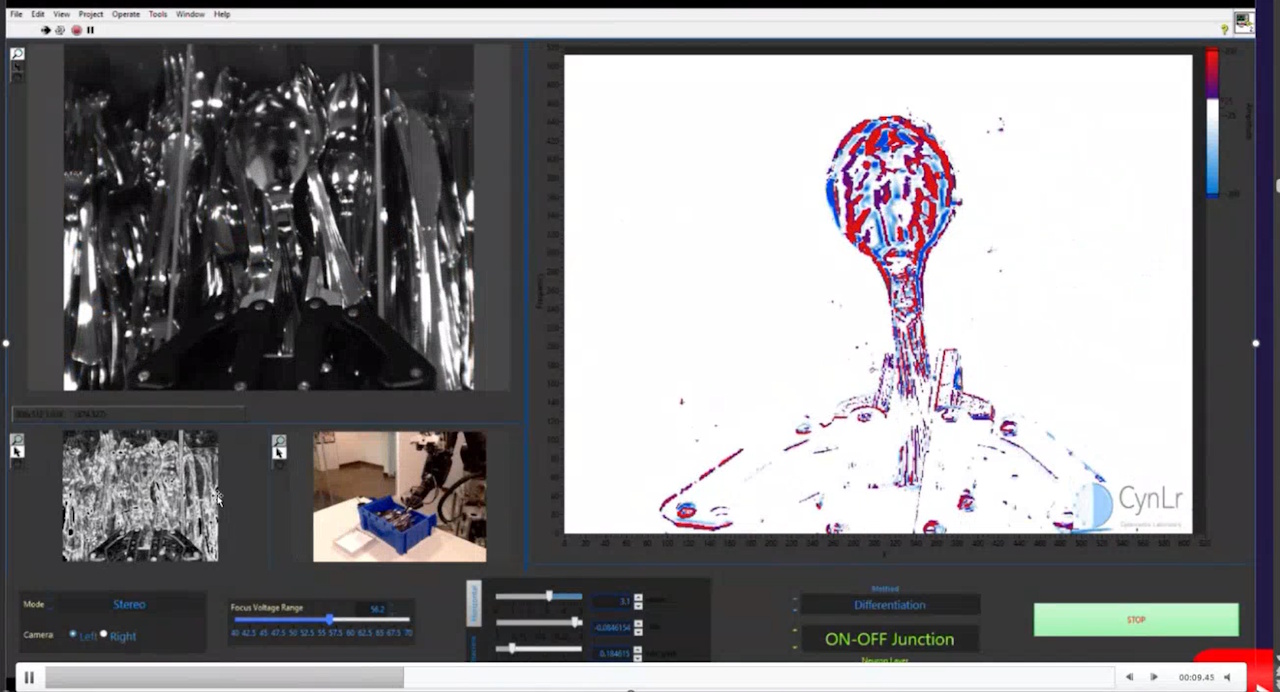
Visually isolating one spoon against a background of cutlery (Source: CynLr)
The really clever part is that motion itself becomes part of the vision algorithm. The guys and gals at CynLr believe this approach could fundamentally change industrial automation. Today’s robots excel at repetitive, carefully controlled tasks in highly structured environments. But factories increasingly need flexible automation capable of handling changing products, variable orientations, mixed inventories, reflective surfaces, deformable packaging, and partially unknown objects.
Instead of requiring painstaking reprogramming every time something changes, CynLr’s approach aims to create robots that can adapt on the fly—more like skilled workers and less like glorified animatronic toasters (don’t ask).
For me, the really important point here is that CynLr appears to be shifting robotics from simple recognition toward genuine interaction. Instead of merely labeling objects, the company’s systems attempt to decompose them in real time—shape, motion, texture, reflectivity, grasp affordances, and physical behavior—allowing robots to figure out how to pick, align, manipulate, and assemble unfamiliar parts with minimal prior knowledge.
Will this instantly lead to humanoid robot butlers wandering around our homes, folding laundry, and making cups of tea? Probably not by next Wednesday, although I’ve learned not to make predictions, especially about the future. Even so, technologies like this may ultimately prove to be one of the missing pieces required to move robotics beyond carefully scripted demonstrations into the gloriously messy real world the rest of us inhabit.
If you’d like to learn more, please feel free to visit CynLr to explore their videos, demonstrations, and documentation, and then reach out to them (tell them “Max says Hi”). In the meantime, I shall continue training for my future role as “backup household assistant” in case Gigi eventually upgrades to a robot model with better navigation and fewer complaints.


