


“If [a small business’s] cashflow dries up, the impact is fatal.” – Theo Paphitis, entrepreneur
What if FedEx replaced its delivery vans with a fleet of Ferraris? That’d be cool. They could deliver packages way faster than now. On the other hand, they’d be able to deliver only small packages; shipping a big bookcase would be a problem. Sportscars don’t have big trunks because speed, cargo capacity, mass, and a high center of gravity just don’t go together.
It’s the same with computer memory chips. You can have fast ones, or you can have big ones, but you can’t have big, fast ones. It’s just the nature of chip-making science that speed and capacity are at opposite ends of a sliding scale. And this causes problems for computer designers.
All computers, from Amazon’s massive cloud-computing datacenters down to the smartphone in your pocket or the thermostat on your wall, have both processors and memories. The processor chip(s) runs the software and the memory chip(s) stores the software and all its data. The processor reads software instructions and data out of the memory, and it stores the results back into the memory. This back-and-forth conversation happens nonstop, millions, even billions, of times per second.
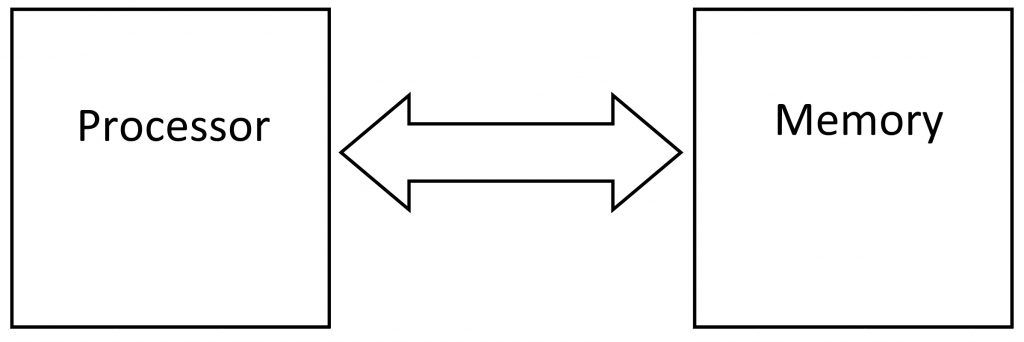
Trouble is, the processor is faster than the memory – by a lot. That slows things down. It’s like a hyperactive poodle* straining at the leash held by its 300-pound owner. It wants to race, but the owner isn’t built for speed. So, what do you do?
You hire a dog walker who can keep up with the dog. Sure, it adds a third person to the party, but everybody wins. The dog gets to run at full speed, the dog walker gets some aerobic exercise and makes a few extra bucks, while the owner gets to plod along at a comfortable and familiar pace, trading money for convenience.
In the computer world, we fix this problem by adding a third chip to the mix, in between the processor and the memory. It’s called a cache memory and it’s about the only thing that FedEx trucks and dog walkers have in common.
Memory chips can be either big or fast, but not both. Since we all want lots of storage in our phones, computers, cameras, and other gizmos, gadget makers almost always opt for the big, slow kind. That boosts the number of photos you can store, but it also means that new cutting-edge processor chip you paid extra for is running dog-slow because the memory can’t keep up with it.
Enter cache memory. It’s a small amount of the fast type of memory, and it alleviates some (but not all) of the problem of speed mismatch between the processor and the big main memory. (Oh, and the word is pronounced “cash,” not “cash-ay,” which is a completely different French word meaning charm, elegance, or prestige.)
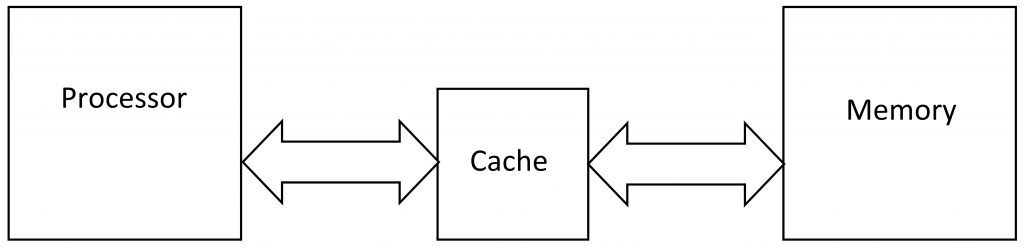
Like Robinson Crusoe, your processor stores a few of its favorite and most often used items in a cache – that is, a small local stash away from the main storehouse. The cache is nearby – it’s physically closer to the processor silicon than the memory is – and it’s made of the fast kind of memory, so it’s just as quick as the processor.
There are only two downsides. First, cache memory is expensive, so adding a cache adds cost to the product. Second, caches are small. They can’t possibly hold as much stuff (software, photos, music, documents, passwords, etc.) as the main memory can. So, you’ve got to make some tradeoffs.
You and I haven’t got a clue what should go into the cache and what should go into the main memory, so nobody asks us. Instead, the cache makes that decision all on its own. And this is where the magic happens.
Everything going in and out of the processor passes through the cache (as the diagram shows), so it gets to snoop on every transaction. When the processor requests new data from the memory (from right to left in the diagram), it passes through the cache, which keeps a copy. If the processor happens to request that same data again later on, the cache springs into action and supplies the processor with its own local copy, not the one stored all the way back in the main memory. This speeds things up considerably. The cache is like an attentive butler who always knows what you want before you want it.
It also works in reverse. When the processor stores something into memory (data moving left to right in the diagram), the cache snags a copy of the data as it passes through on its way to main memory. The benefit here is that the cache stores the data much sooner than the main memory could, so it can tell the processor to go back about its business a bit sooner. Later, the data will make its way from the cache into the main memory.
So… a win-win, right? Caches make everything better? Well, yes and no. There are some real tricks to make a cache work right, but on the whole, yes, caches are good things and nearly every modern gizmo has one or more cache memories inside.
What are the tricky parts? Caches work on the basis of probability, meaning that they play the odds and take small risks with our data in exchange for faster speed. Because the cache is small and can’t possibly hold as much as the main memory, it has to guess which bits to store and which ones to ignore. The methods for this are abstruse and arcane, and sometimes carefully guarded company secrets, but they all basically rely on something called a least-recently-used (LRU) algorithm.
The LRU algorithm basically says that the cache should always keep a copy of any new data that passes through it, until it gets full. Then, it should find the oldest – the least-recently used – piece of data, and erase that to make room for the new data. Sounds reasonable.
The problem is that the cache can’t simply erase data. If it did, we’d lose our photos, documents, and sanity all the time. The cache needs to store that data in the main memory so that it doesn’t get lost, and as we know, that takes time. But it’s the cache’s responsibility to make sure every bit of data finds its way safely into the main memory – no exceptions.
The small size of the cache means that there’s lots of competition for space. This can lead to cache “thrashing,” as old data continually gets evicted to make way for new data. Making the cache bigger can reduce the thrashing, but it also increases cost and reduces speed.
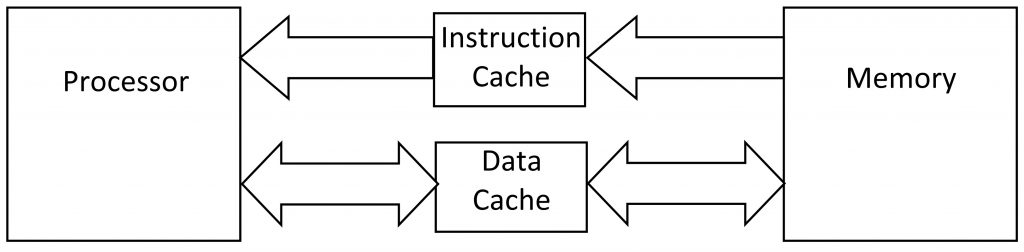
Some processors have more than one cache: one just for software and a separate cache for data. This reduces thrashing even more but adds still more to the cost. Note that instructions always go from memory to the processor; processors don’t write software, they read it. Data can go both ways.
If you want to get really fancy, you can have multiple levels of cache memory: caches on top of caches. The cache closest to the processor is called the level-one cache (L1), with the level-two (L2) cache behind it. The L1 cache is extremely fast (and extremely small), while the L2 cache is a bit larger and a bit slower, but still faster than the main memory. Your high-end Intel Xeon or AMD Epyc processors even have three cache levels: L1, L2, and L3.
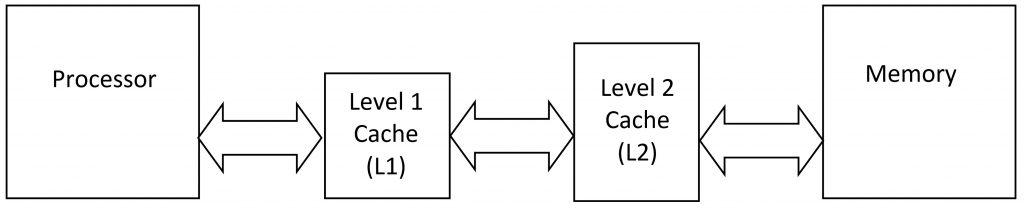
The idea behind these multilevel caches is, as always, to keep up with the high-speed processor. A single cache would be either too small to be useful or too big to keep up, so the L1 cache gets its own cache (the L2), which might get its own cache (L3) for good measure.
Which brings us to a new problem: cache coherence. All caches store data (and software), but it’s important that they all store the same data. Whenever the processor writes something new into the cache, that update will eventually make its way back into the main memory. Until it does, the data in main memory is old and out of date. It’s stale data, and we have to make sure stale data is never used again. There’s a time delay between when the new data goes into the cache and when it’s propagated out to main memory. That time delay presents a risk.
With a single cache, you’ve got two places the data could be stored: in the cache or in main memory. With a two-level cache there are three possibilities, and with a gonzo three-level cache you’ve got four possible locations for any piece of data. Somehow the computer has to keep track of which copy is current and which one(s) are stale. This involves a lot of back-channel communication between the caches to keep everything coherent, meaning they’re all in sync with each other. Remarkably, this all works automatically without you, me, or the processor knowing anything about it.
As complex as this all is, we haven’t even started on the exquisite complexities of cache-allocation algorithms, line eviction, dirty bits, multiprocessor systems, cache snooping, or… well, let’s save those gory details for another day.
*Redundant, I know.



You can work around the problems of cache-coherency –
https://youtu.be/Bh5axlxIUvM