

On the one hand, I’m tremendously excited and enthused by all of the amazing things I’m currently hearing regarding deployments of enterprise-level artificial intelligence (AI), machine learning (ML), and deep learning (DL). But (and there’s always a “but”)…
Actually, before we hurl ourselves headfirst into the fray with gusto and abandon, someone asked me earlier today to explain the differences between AI, ML, and DL. Well, in a crunchy nutshell, AI refers to any technology that enables machines to simulate (some say “mimic”) human behaviors and decision-making abilities. Meanwhile, ML is a subset of AI that has the ability to look at data, automatically learn from the data, and then use what it’s learned to make informed evaluations and decisions. In turn, DL is a subset of ML that employs algorithms structured in layers to implement artificial neural networks (ANNs). With architectures inspired by the networks of neurons in biological brains, ANNs can learn and make more sophisticated evaluations and decisions than can more traditional ML models.
Apropos of nothing at all, it’s my habit to ask Alexa to “Tell me a stupid cat joke” each evening shortly before I close my eyes and let the Sandman convey me to the Land of Nod. Her joke last night went as follows:
Q: Why did the cat cross the road?
A: Because the chicken had a laser pointer!
I laughed. My wife (Gina the Gorgeous) laughed. Alexa laughed…
As a somewhat related aside, did you see the article on HuffPost about how a Google engineer was recently placed on administrative leave after he started telling people that the AI program on which he was working had become sentient?
And, as a totally unrelated aside, have you heard about the startup in Australia that is growing live human neurons and then integrating them into traditional computer chips as described in this video (now I can’t help thinking of the “It’s alive! It’s alive!” scene, which has to be one of the most classic lines in the history of horror movies).
When it comes to using live neurons, the term “mindboggling” seems somewhat inappropriate. On the other hand, having the playing of Pong—which was one of the first computer games to be created—as one of the first tasks for these bio-machine-brain hybrids does seem kind-of appropriate in a wackadoodle sort of way.
“But what has stirred your current cogitations and piqued your present ponderings?” I hear you cry. Well, I was just chatting with Mark Richards, who is Senior Product Marketing Manager at Synopsys.
As a reminder, in 2020, Synopsys launched DSO.ai (Design Space Optimization AI), which is described as being “The industry’s first autonomous artificial intelligence (AI) application for chip design.” As the folks at Synopsys say, “DSO.ai searches for optimization targets in very large solution spaces of chip design, utilizing reinforcement learning to enhance power, performance, and area. By massively scaling exploration of design workflow options while automating less consequential decisions, the award-winning DSO.ai drives higher engineering productivity while swiftly delivering results that you could previously only imagine.”
DSO.ai makes its presence felt right at the beginning of the System-on-Chip (SoC) and multi-chip module (MCM) design process. Another tool in the Synopsys arsenal is SiliconDash, which hangs out in the post-silicon portion of the process. SiliconDash is a high-volume industrial big data analytics solution for fabless companies. It delivers comprehensive end-to-end real-time intelligence and control of SoC and MCM manufacturing and test operations for executives, managers, product engineers, test engineers, quality engineers, sustaining engineers, device engineers, yield engineers, and test operators.
All of which leads us to the latest offering from Synopsys, DesignDash, which addresses the main digital design and analysis portion of the project process (think “RTL to GDSII”).
I’ll try to convey everything Mark told me as succinctly as I can. Let’s start with two of the biggest industry-wide challenges. The first is the growing shortfall in design/designer productivity caused by ever-increasing design/system complexity, evermore challenging PPA (power, performance, and area) targets, the designer resource crunch (there aren’t enough of them), and inefficient debug and optimization workflows, all of which challenge time to market (TTM) goals.
The second major challenge is poor visibility and observability into the design process, which has long been opaque if we’re being generous, and whose opacity is increasing in step with the capacity and complexity of the projects. Designers and managers typically have a limited view into the entire design process, making it difficult to track exactly what’s going on and equally difficult to improve the situation.
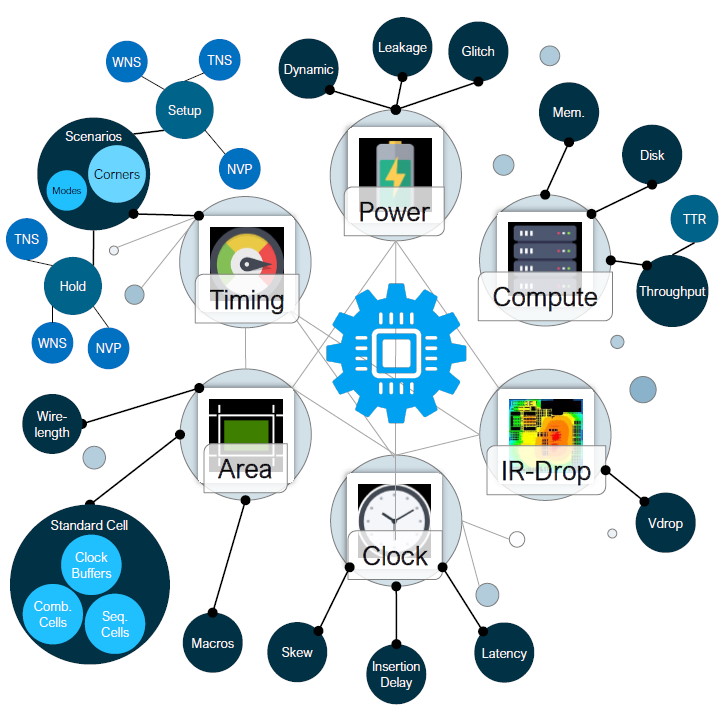
One of the interesting things to contemplate is the vast amounts of data that are generated by the various tools. A typical project involves thousands of tool-flow runs for tasks like design space exploration, early feasibility analysis, architectural refinement, block hardening, signoff, regression tests… and the list goes on.
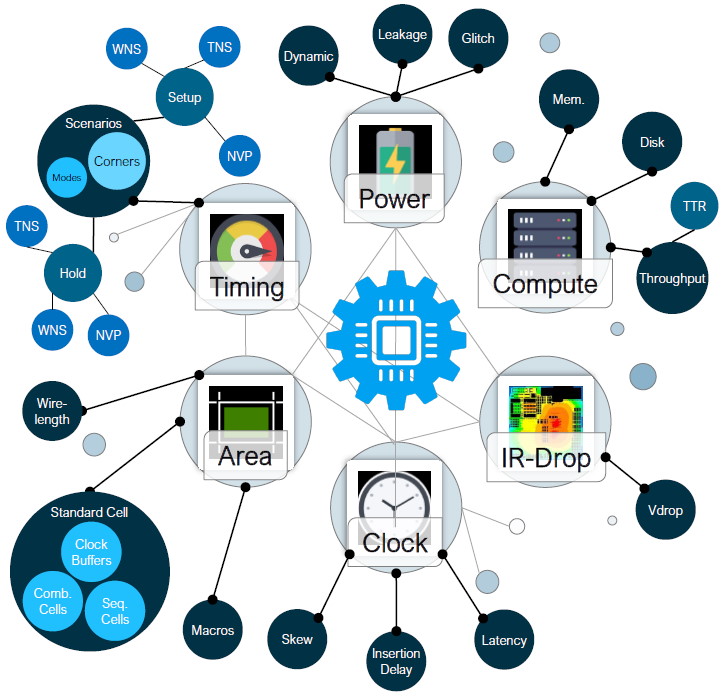
A head spinning amount of data is generated during the process of designing an SoC or MCM (Image source: Synopsys)
As the Hitchhiker’s Guide famously says: “Space is big. Really big. You just won’t believe how vastly hugely mind-bogglingly big it is. I mean, you may think it’s a long way down the road to the chemist, but that’s just peanuts to space.” I feel much the same way about the amount of data generated during the course of an SoC or MCM design. It’s a lot. It’s really a lot. You just wouldn’t believe how much data there is.
In turn, this reminds me of the “holistic detective” Dirk Gently who makes use of “the fundamental interconnectedness of all things” to solve the whole crime and find the whole person. My point here is that all of the data generated by all of the SoC/MCM design tools are fundamentally connected. The trick is to understand all of the connectiveness and dependencies. Gaining this understanding is crucial with respect to designing and debugging effectively and efficiently.
Like most things, this sounds good if you speak loudly and gesticulate furiously, but how are we poor mortals going to gain this deity-like understanding? Well, if you’ve been paying attention, you might recall my mentioning that the folks at Synopsys have just introduced DesignDash, which provides a comprehensive data-visibility and machine-intelligence (MI)-guided design optimization solution to improve the effectiveness, productivity, and efficiency associated with SoC/MCM design.
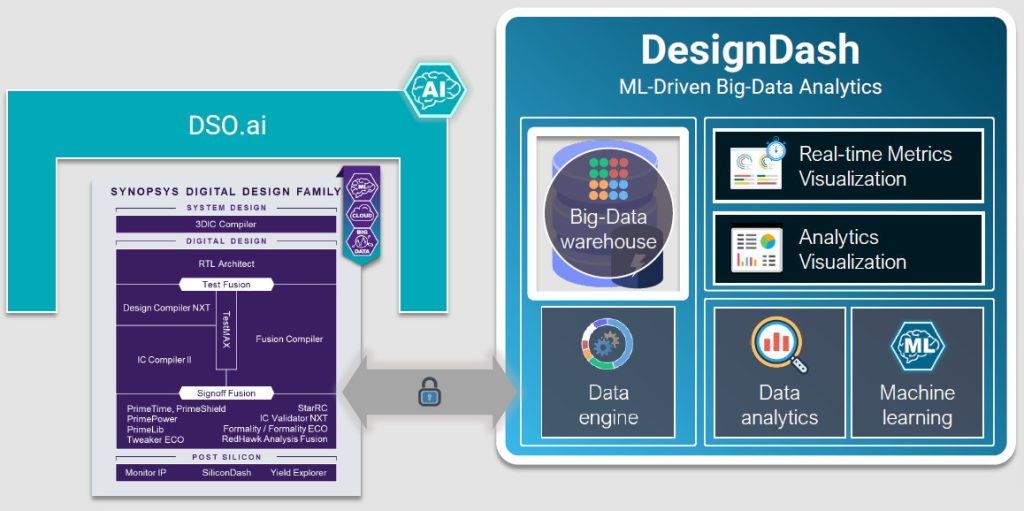
DesignDash: product debug and optimization, evolved (Image source: Synopsys)
DesignDash provides a combination of big data + analytics + learning. Fully integrated with the Synopsys digital design family (and including easy third-party tool support), DesignDash offers native extraction of full-flow data from RTL-to-GDSII implementation/signoff tools and provides comprehensive visualizations to view data from all of the tools together. Furthermore, it deploys deep analytics and ML to deliver a real-time, unified, 360-degree view of design-implementation activities. It leverages the vast potential hidden in the data to improve the quality and speed of decisions, and then it augments these decisions with intelligent guidance.
This is where things start to get interesting, because this capability opens the doors to all sorts of insight-to-action possibilities, including business intelligence (resource planning, resource usage trends, overall resource efficiency), project intelligence (PPA trend/status, QoR causation and closure, design efficiency profiling), and predictive analytics (historical pattern extraction, cross project insights, prescriptive closure guidance).
One example that caught my eye is the ability for the ML to detect patterns, identify anomalies, and determine relationships across time and across tools. This means that DesignDash will be able to provide root cause analysis (RCA), allowing the origin of a problem that manifests itself downstream in the process to be identified and addressed in this and future projects. Things will get more and more interesting as DesignDash gets more and more designs under its belt, which will allow it to identify problems and predict outcomes earlier in the development process.
Unfortunately, this is where my mind starts to run wild and free through the labyrinth of possibilities. Could it be that, at some stage in the future, managers spend part of their day documenting the perceived mood and state of mind of each of the members of the team? For example, “Sally seems to be in a good mood,” “Henry seems to be a bit grumpy,” and “Jack and Jill were dating but they just broke up.” What I’m thinking is that, when something in the design goes pear-shaped, the system might identify the fact that—six months earlier—Cuthbert (who is terrified of going to the dentist) discovered that he had a cavity, resulting in a lack of attention and concentration. I can also envision the system reporting that better results are obtained when certain designers work together (“You can expect a 5% reduction in area if A and B are teamed up), while other combinations of team members tend to have less salubrious effects.
And this leads me to… but no! I refuse to be drawn into the possibility of “Mood Forecasts” on the nightly news along the lines of “A wave of depression is sweeping down from the Northeast. It will arrive in our area around 3:00 p.m. tomorrow, so that would be a good time to break out your happy pills.” How about you? Do you have any thoughts you’d care to share?


