


“The medium is the message” – Marshall McLuhan
Distinguishing between a live human speaking and a recorded version of the same person is trickier than it sounds, and it has a lot of developers scrambling for solutions. Amazon’s Alexa team, for one, has published some of its research results along with some ideas for improvement. The techniques range from the simple to the complex, with detours into the creative and the slightly creepy.
Voice recognition as a whole just keeps getting tougher. It seems like the problems keep flip-flopping. At first, the trick was to get a machine to respond to any kind of voice activation at all. Then the challenge became to make it recognize a few words. After that, we tried making them speaker-independent. Then we reversed course by making them speaker-dependent again.
Now the challenge is to recognize the difference between a live speaker and a recording of a live speaker. In short, how do we stop Alexa taking orders from the TV?
Which has already happened, of course. Burger King’s April 2017 TV commercial remotely commanded a bunch of Google Home devices, causing widespread embarrassment to Google and near-panic among users. It wasn’t long before people started plotting widespread spoofs and takeovers of virtual assistants worldwide. The robot uprising never seemed closer.
Since then, we’ve more or less mastered the technology behind getting Alexa, Siri, Google, Cortana, and other voice-activated devices to recognize their names as triggers or wake words. But the more-subtle problem is avoiding false triggers coming from the TV, radio, MP3 player, or 180-gram vinyl if they happen to utter the same wake words. It’s fun to speculate on the trouble you’d cause by releasing a #1 hit single with the lyrics, “Hey, Siri, cancel my cable subscription. Alexa, order a million pounds of gravel, and Cortana, text my boss telling him he’s an idiot.” Oh, the quiet joys of modern technology.
Amazon’s Alexa team takes a multi-pronged approach with its products. Unbeknownst to most users, Alexa products already try to distinguish between real commands and those coming from the little man inside the radio.
The first line of defense is a cache of known recordings of the word “Alexa.” It’s basically a blacklist. These are stored locally on your Amazon Echo Dot, Echo Show, or similar device. If the device hears Alexa’s name (Amazon developers internally refer to Alexa as “she”), it compares the incoming audio to the local samples. If there’s a match – that is, if it’s overhearing a prerecorded TV or radio program that’s known to include the word Alexa – then the device will ignore that input. From a user’s perspective, nothing happens. An Echo Dot, for example, won’t wake up and won’t blink its colored lights. There’s no outward evidence that Alexa even recognized, but ignored, her name. The comparison is done locally, using only the device’s CPU and memory, so there’s no communication with the Amazon mothership required.
Interestingly, Amazon regularly updates this cache of blacklisted audio samples based on regional broadcast media programming. If there’s a TV commercial airing in your area that mentions Alexa, Amazon will direct all your neighbors’ devices to ignore the ad.
The next step of rejection relies on the wisdom of crowds. If three or more Alexa devices in the same general area but not in the same house all hear exactly the same thing at the same time, Amazon assumes it must be a media broadcast that it didn’t know about. This would happen during any live TV or radio broadcast, where Amazon has no opportunity to record and download an audio fingerprint. In these cases, Alexa devices do connect to Amazon’s servers to compare notes. Outwardly, your Echo Dot will appear to wake up, pause, and then shut down again.
The third line of defense is still in development, and it relies on machine learning, a lot of training, and some hardware that’s already in place. Amazon is trying to teach Echo Dots and other devices the subtle difference between a live speaker it should obey and a recorded speaker it should ignore – not an easy task.
Personally, I figured the tinny sound of TV speakers would be a giveaway, but that’s apparently not the case. Halfway decent home audio systems, home theaters, and TVs with sound bars produce full-spectrum sound that easily fools Alexa and devices like her… it. Distinguishing between a recording and the real thing is complicated if you’re not human.
Amazon is applying fully acronym-enabled machine-learning techniques to the problem, describing a parallel CNN-GRU-FC classifier architecture in this research paper and this one. Briefly, they’re combining two separate and unrelated techniques, each of which improves recognition by a measurable percentage. Combining the two improves things still further, although it’s far from perfect.
Helping the issue is the fact that broadcast media sources tend to make noise constantly (TV shows, radio broadcasts, movies, etc.), while humans tend to talk in short bursts. Complicating the issue, however, is that said humans will probably be talking over the aforementioned media broadcast. Alexa has to pick out the wake word from the background noise, while also rejecting wake words that are part of the background noise.
Recorded media sources also tend to be stationary (TV on the wall, radio on the table, etc.), whereas human speakers sometimes move around while they’re talking to Alexa. It’s not a foolproof test, but it helps.
Amazon’s two-pronged ML approach combines the potential motion aspect with careful frequency filtering in an attempt to separate its master’s voice from recorded facsimiles. An Echo Dot is less than 4 inches (100 mm) across, yet it has seven microphones arranged in a ring. Given the speed of sound through room-temperature air, that means there are about 200 microseconds of delay from one side of an Echo Dot to the other. That’s enough to triangulate the direction of arrival (DoA) of the audio source. More important, it allows an Echo Dot to tell whether the speaker is moving or stationary. If the wake word came from the direction of a stationary, constantly noisy source, it’s probably a media unit (TV, radio, et al.). If, on the other hand, the speaker is moving and hasn’t been talking nonstop for an hour, it’s probably human.
The more-complex part involves audio frequency filtering. Amazon’s researchers factored in LFBE (logarithmic filter bank energy) to break apart the incoming audio spectrum into energy bands. Filter banks are common enough, but Amazon breaks theirs into 64 very unevenly sized bands, starting with narrow bands at low frequencies (beginning at 100 Hz), moving to wider bands at higher frequencies (up to 7200 Hz). (For a description of LEBEs in speech recognition, see pp. 152–158 in this book.) There is considerable overlap between adjacent bands, as is typical in audio filtering.
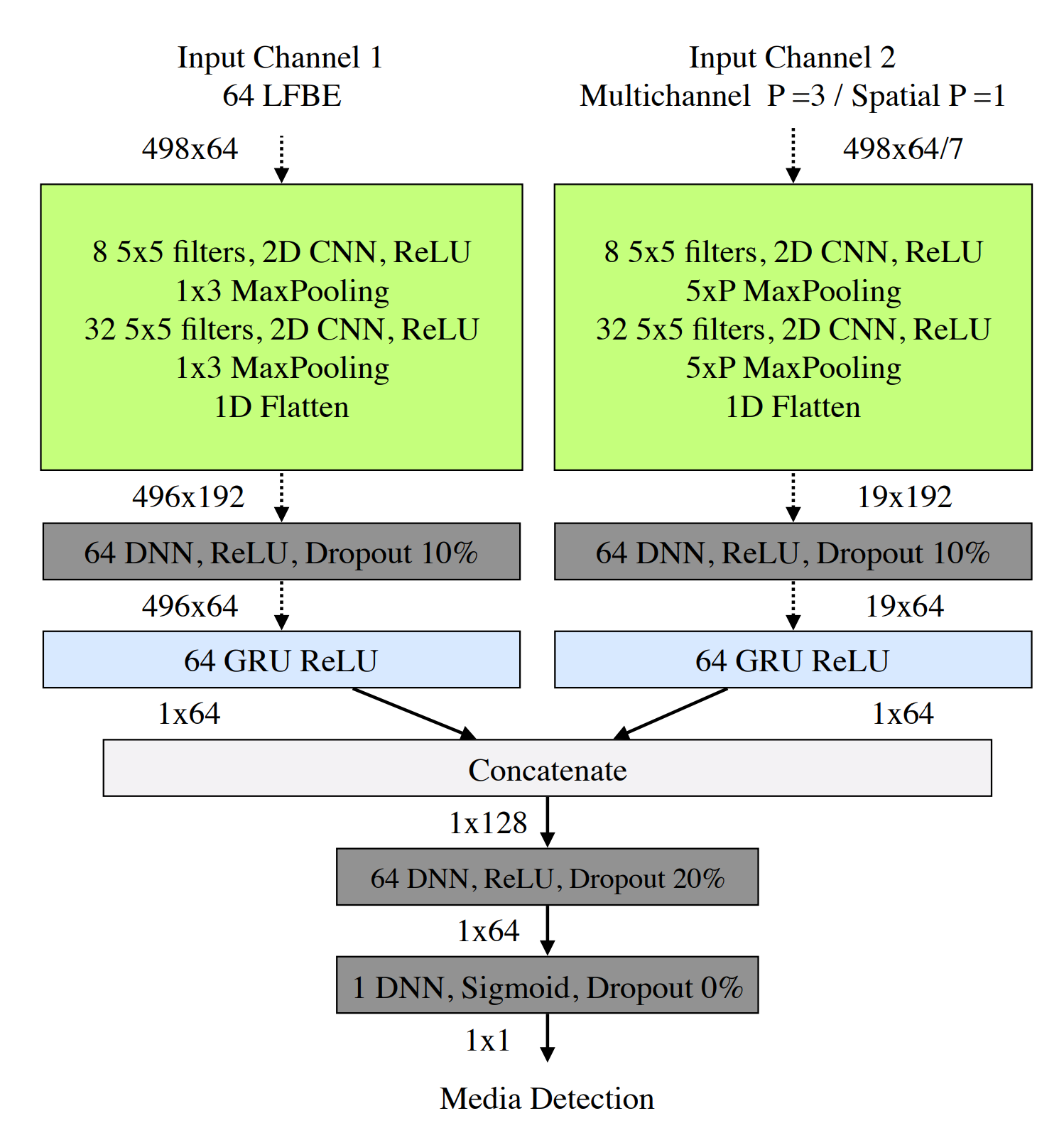
Through this they fed 378 hours of both live and prerecorded audio, including a mixture of spoken conversation, recorded music, and “other.” The filter was very good at telling the difference between live and recorded singing, but less accurate at “other” sounds, and least accurate of all at simple spoken words. That’s because of speech’s limited bandwidth compared to music. So, if you want Alexa to know it’s really you, sing to her.
Combining directionality with filtering improved accuracy even more, and this seems to be the route Amazon is likely to take with future products. They call this a split long/short term (SLST) model, and the table below shows the improvement over “baseline” accuracy, which in this case means the audio filtering without the directional microphone array. The bottom four rows highlight the challenge that remains. When singing, speaking, and other sounds are all present at once, Amazon’s SLST is 100% accurate at telling the difference between media sources versus live sources. After removing the “other” component, accuracy remains at 100%. But removing the singing while replacing the “other,” accuracy drops slightly to 97%, although it’s much better than the 90% baseline. Finally, removing all other recorded sounds and leaving just the recorded voices, accuracy dropped substantially, to just 76% (but still better than the 68% baseline). There’s a lot of work still to do.
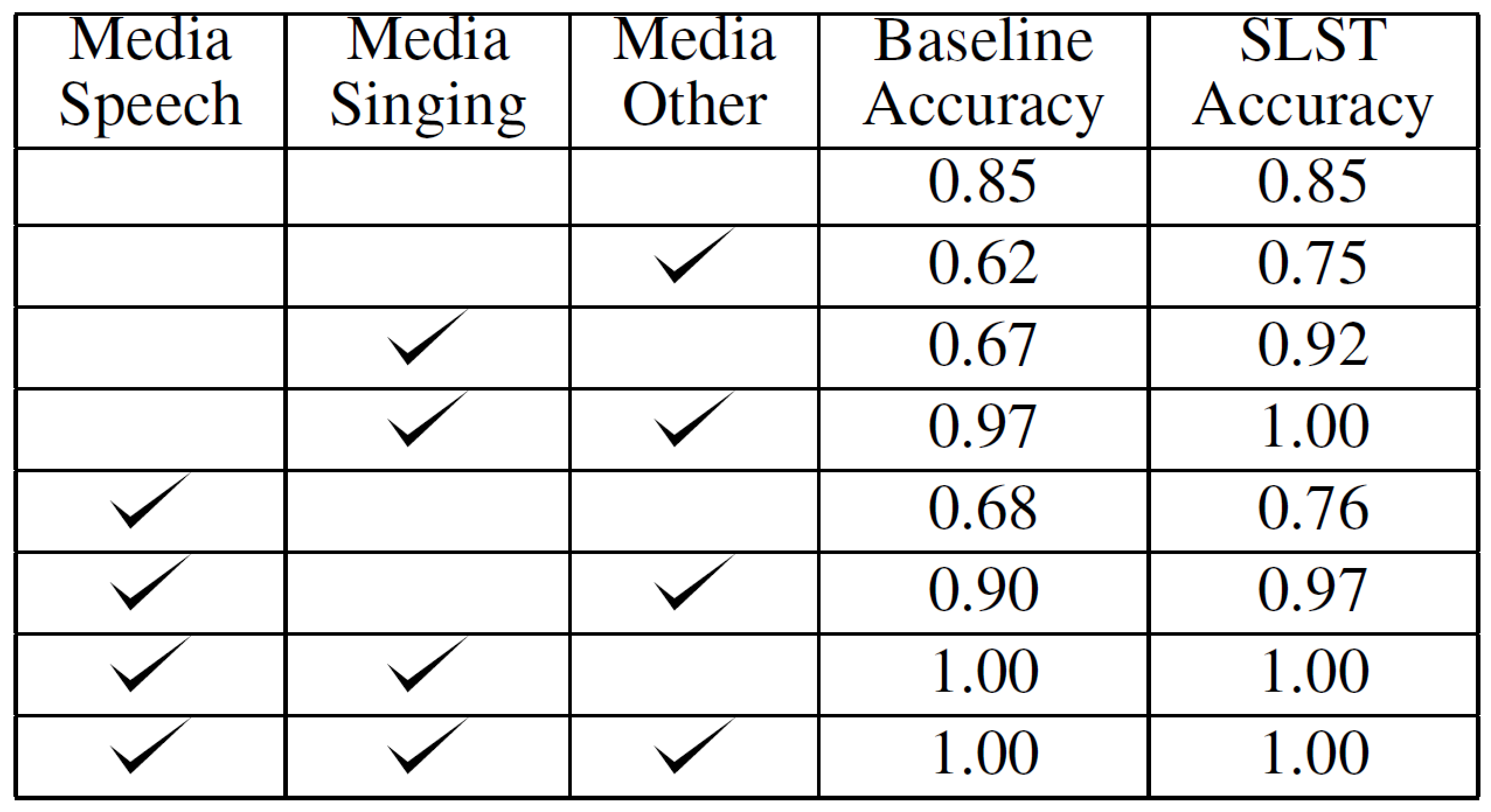
Bear in mind that this wasn’t a test to recognize specific wake words; only to distinguish between live audio and prerecorded or broadcast audio. In other words, the outcome of this elaborate analysis is a single bit.
Humans are good at solving the “cocktail party problem” of filtering the relevant speech from the background noise. Machines aren’t. Anyone who’s played around with a tape recorder has likely been surprised by how much background noise it preserves. Sounds that we didn’t notice at all seem like they’re amplified on tape. There’s still a way to go before Alexa can become like us and ignore the TV.



One thought on “Teaching Alexa to Ignore Your TV”