


“Ticking away the moments that make up a dull day.” – Pink Floyd
This definitely falls into the “red pill” category. What if I told you that you don’t need a camera to take pictures? Or even an image sensor? Or light? Or that you can capture high-resolution images – with just a single pixel?
Remember, all I’m offering is the truth, nothing more. Follow me.
A team of researchers has developed a way to take pictures – three-dimensional pictures, no less – using nothing but a single point sensor. It can be almost any kind of sensor: laser diode, radar receiver, audio microphone, ultrasound transducer, or a Wi-Fi antenna. Anything that receives an incoming signal that can be measured and timed. The algorithm they’ve developed then uses time, not light, to assemble a 3D image based on nothing but the arrival time of that signal. No light, no megapixel array. Just one sensor and a lot of ML software.
It seems impossible, then weird, then spooky. Maybe it’s all three. But it definitely works, and the researchers have filed a patent application and are currently looking for commercial partners.
“It’s really surprising to me that they can get anything out of this system because there’s absolutely not enough information coming out of it,” says Laura Waller, a CS/EE professor at UC Berkeley and unconnected with the project, speaking to Science magazine.
As the team points out in their recently published paper, photography has been around for a long time and it’s pretty well understood. You expose film or electronic sensors to incoming light. The greater the number of sensors, or the larger the film surface, the larger, sharper, and more detailed the image. Alternatively, instead of exposing thousands or millions of sensors at once, you can use a single sensor and scan it around. Lidar sensors (in automotive collision-avoidance systems, for example) emit and capture a single laser beam but physically move the sensor around to gather an image from multiple pixels. The scanning process takes a lot more time, but it requires only a single sensor instead of thousands or millions.
Photos are two-dimensional. If you want depth information – 3D images – there are a couple of ways to do that, too. Stereo imaging uses two identical cameras spaced apart (like mammalian eyeballs) to capture the same images from two slightly different vantage points, then uses software (visual cortex) to infer depth information from the parallax angles. Easy.
Or you can take a normal 2D image and supplement it with distance information measured separately, using anything from a tape measure to lasers, radar, or a flashbulb. These latter techniques depend on precisely measuring time of flight (ToF) as the light leaves some sort of emitter, bounces off objects in the scene, and is captured by a receiver. It’s basically echolocation combined with photography.
You’ll notice that all these techniques use millions of image sensors but only a single distance sensor. What if you removed the megapixel image sensors – the camera – completely and left just the lone distance sensor? Can you take a photograph with no camera?
Turns out, you can. But it’s tricky.
Shining a light (for just about any definition of “light”) at a roomful of people and objects produces a lot of reflections. The distance from the light source to the object, and then to the detector determines the timing of those reflections. But if you have only a single light source and a single detector, and neither of them moves, all those reflections get smushed together. The nightmare case, as the researchers point out, would be a hollow spherical room where all reflections from every direction arrive all at once. There’s no way to tease spatial information out of that data.
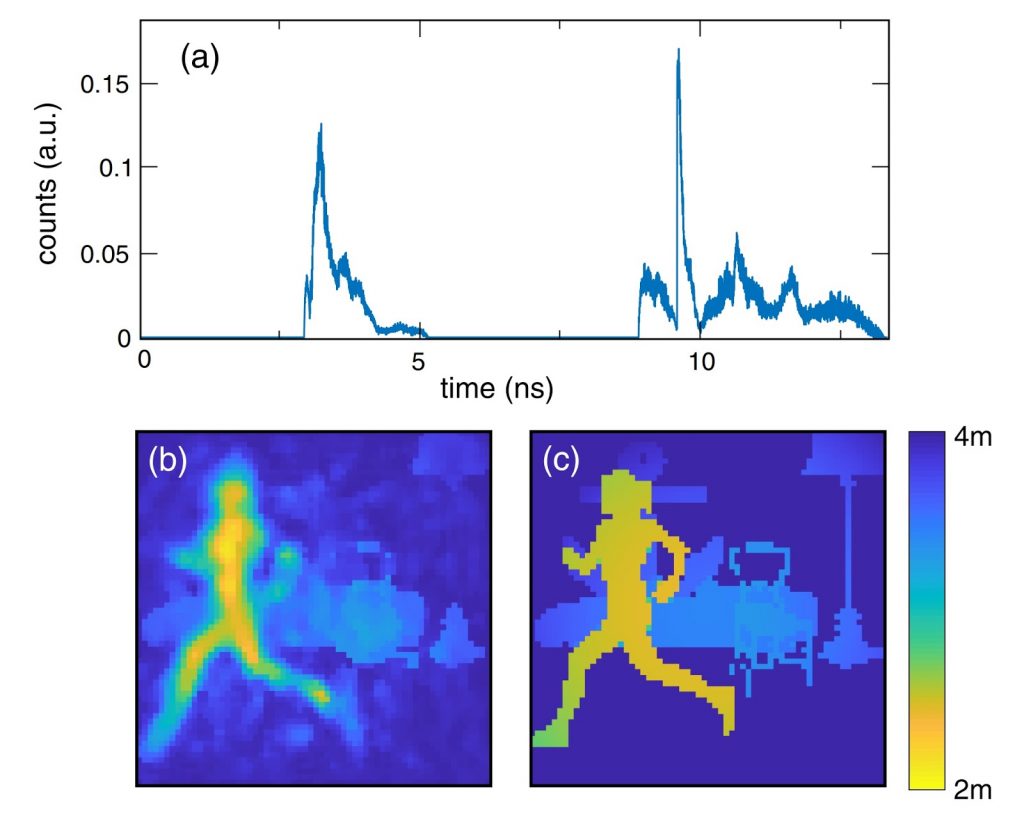
But apart from pathological corner cases like that, the team was able to glean spatial information based on ToF histograms from a single source to a single detector. In their experiments, they used a pulsed laser to illuminate their lab space and a single-photon avalanche diode (SPAD) to detect the reflections.
The keys were short pulses and a good neural network. Like all neural nets, this one required training. First, they illuminated the lab space and recorded histograms of the background reflections. Then, they introduced new objects, both moving and static. The algorithm was able to isolate the new items from the known background, and it could distinguish between moving and stationary objects, all based on ToF histograms from a single sensor.
You can see a video of the lab team moving around the room and waving objects in front of their “camera.” Oddly, the algorithm had a hard time resolving the image of a big cardboard letter T, yet did just fine with moving people.
Like any photography, the resolution of the images depends on the wavelength of the light and the accuracy of capturing it. The research team used a 550nm laser with a 75ps pulse width, which they admit isn’t very good. Really high-end commercial sensors would improve resolution significantly, they suggest.
Later, they replaced the laser with radar equipment and got similar results. And they theorize that a radio-frequency antenna would work just as well. Almost any source of radiation will work, including sound waves. No special hardware is required. The magic is all in the ML algorithm, which they’re in the process of patenting.
I spoke with the research lead, Dr. Alex Turpin, Lord Kelvin Adam Smith Fellow in Data Science at University of Glasgow. He’s optimistic that the technology will have commercial uses that allow people to repurpose existing sensors. An average laptop, for example, has one or more microphones that could be used to detect incoming audio signals. Cars have ultrasonic parking sensors. Some high-end cellphones already have a ToF sensor for detecting distance to the subject. Compatible sensors are cheap and ubiquitous. On the other hand, cellphones already have good cameras, so using Turpin’s time-based image reconstruction technique seems needlessly complicated. Non-photographic devices, however, could gain a whole new feature set.
Either way, the technique is remarkable, and remarkably subtle. Turpin admits that the system needs to be trained on each room or scene. It can’t figure out objects in an unfamiliar place. But training takes just milliseconds, even using average hardware. It’s not difficult. Just… not what anyone expected.


