


The upshot: Mindtech provides a capability for creating fully annotated synthetic training images to complement real images for improved AI training.
We’ve spent a lot of time looking at AI training and AI inference and the architectures and processes used for each of those. Where the AI task involves images, we’ve blithely referred to the need for training sets; that’s easy, right?
After all, if you’re trying to train your algorithm to recognize a dog, then just give it a bunch of pictures of dogs (OK, tag them with, “This one contains a dog”) and then a bunch of pictures without dogs (“This one contains no dog”), and off you go! Right?
And the behemoths like Google and Facebook have oodles of images and videos (videos being collections of frames, each of which is an image), thanks to the free stuff willingly served up by unsuspecting users (including images now and 10 years ago to help improve aging algorithms). That will easily give those guys an edge in AI so that they can, at no cost, once and for all, eliminate all competition for anything ever. Right?
Harder than it Looks
Well… maybe not quite right… for any of those. Even with the last one, the fact that they have images is a benefit, but there’s still a ton of work to do. According to Mindtech, there are six big challenges with assembling a training set of images.
- It can cost a lot to assemble and annotate a set of images. Yeah, the big guys may already have free images, but they aren’t useful until annotated.
- Annotation takes a long time. Mindtech says that it can take 75 minutes per frame to edit a video. You’d think you could just tag it with “dog,” but no. You have to tag all of the images in the video for use in multiple jobs. So, one or more dogs; a car; a house; stairs; a window… all called out in each frame with the locations of each item. For 1D items, you have to specify pixel by pixel.
- You need to be sure that the images are free of copyright infringements and that it’s ok to use and store them without running afoul of GDPR rules (at least where Europe or Europeans are concerned).
- You have to make sure that the training set doesn’t introduce bias into the resulting trained model. If most of the images are of golden retrievers, that’s a poor way to train for dog recognition.
- Annotation accuracy is hard to get 100% right. It takes more time and money to do that; mistakes will mistrain a model.
- It can be hard to obtain some real-world models. For automotive model training, Mindtech gave a couple of examples where it’s either hard or unsafe to create a scenario:
- Creating a video showing kids riding bicycles right on the edge of a sidewalk (important for a model to catch, since, if that happened, the bike is more likely to fall into the roadway).
- Having a horse run across a roadway. Probably not a likely scenario in the middle of town (unless a police horse or one of those tour carriage horses got loose); it’s much more relevant in the country (along with cows, deer, elk, etc.)
So… what’s the answer? Is this just a tough problem that’s part of the AI reality? Not according to Mindtech. With their Chameleon tools, they provide a capability for creating synthetic images that will be suitable for training. Does this mean you can punt entirely on the real images? Well, that’s not necessarily what they’re recommending. They see synthetic images as a complement to real images, but in a way that can significantly bulk up a training set with less – but definitely not no – work.
Synthetic Images
To understand what they do, we need to define a few terms that, for them, have very specific meanings. You start by obtaining what they call “assets”: models of… things. Buildings, people, cars, lightpoles, animals – pretty much anything. You’re going to use these in a simulation.
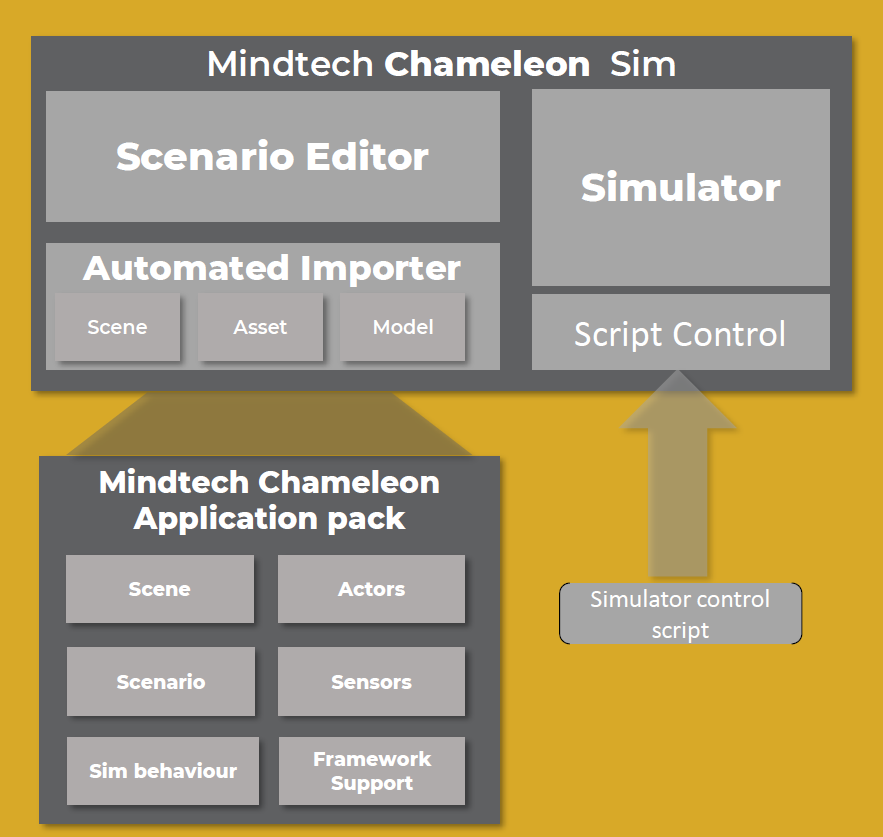
(Click to enlarge. Image courtesy Mindtech.)
You start by creating a “scene”: this is, if you will, the background or the locus of activity in the simulation. The scene is built out of assets, but it’s static. Next, you select “actors” from the assets. These are elements that will do something. You might have a child that runs into the road. There might be a ball that bounces across the road. There might be a car parked along the side of the road that suddenly opens its door in front of a driver. Yeah, lots of these are automotive. They’re not restricted to automotive, but it’s a hot field these days, and it’s easy to visualize.
Once you have the scene and actors placed, then you create a “scenario”: this is where the actors perform some specified act. Because the assets include behaviors, you can have them “do” something. For instance, that car parked along the side of the road can open the driver-side door into the roadway. If it’s a really good model, you’ll even see the interior of the car once it’s been opened (useful for an algorithm that’s supposed to do this in the real world).
Finally, you establish some initial conditions that can be automatically implemented. You may set the time of day (for varying the illumination); you can assign a geographic location; you can set the weather. Once you have this, you run a simulation. That simulation executes the behaviors in a synthetic video. Because all of the assets are explicitly placed and operated, the simulator can identify where everything is within each frame and annotate it accordingly.

(Click to enlarge. Image courtesy Mindtech.)
All of this takes some time to do. Creating assets – 3D models of things – is also time-consuming, although these may already be available from Mindtech or a partner. But you get leverage from the time spent. Mindtech ran the following numbers: “… for one basic scene, with 5 different scenarios, each being replayed with ten different times of day and four different weather settings, you get 200 variations. Capture 1000 images from each variation and you get 200k images from that single simulation run. If you place multiple cameras, that number is multiplied up again.”
These synthetic images can then be merged with real images to improve the training data set. Together, training proceeds as normal. Reporting helps to assess the quality of the set, including bias. It’s up to the person creating the scenario to add diversity so as to reduce bias, but Mindtech suggests that it’s easier to do synthetically than it would be to create real-world images with little bias. I have this niggling feeling that, the more images you generate from a single scene, the more the collection is biased to that scene, so you probably need to generate lots of scenes to keep that from happening.
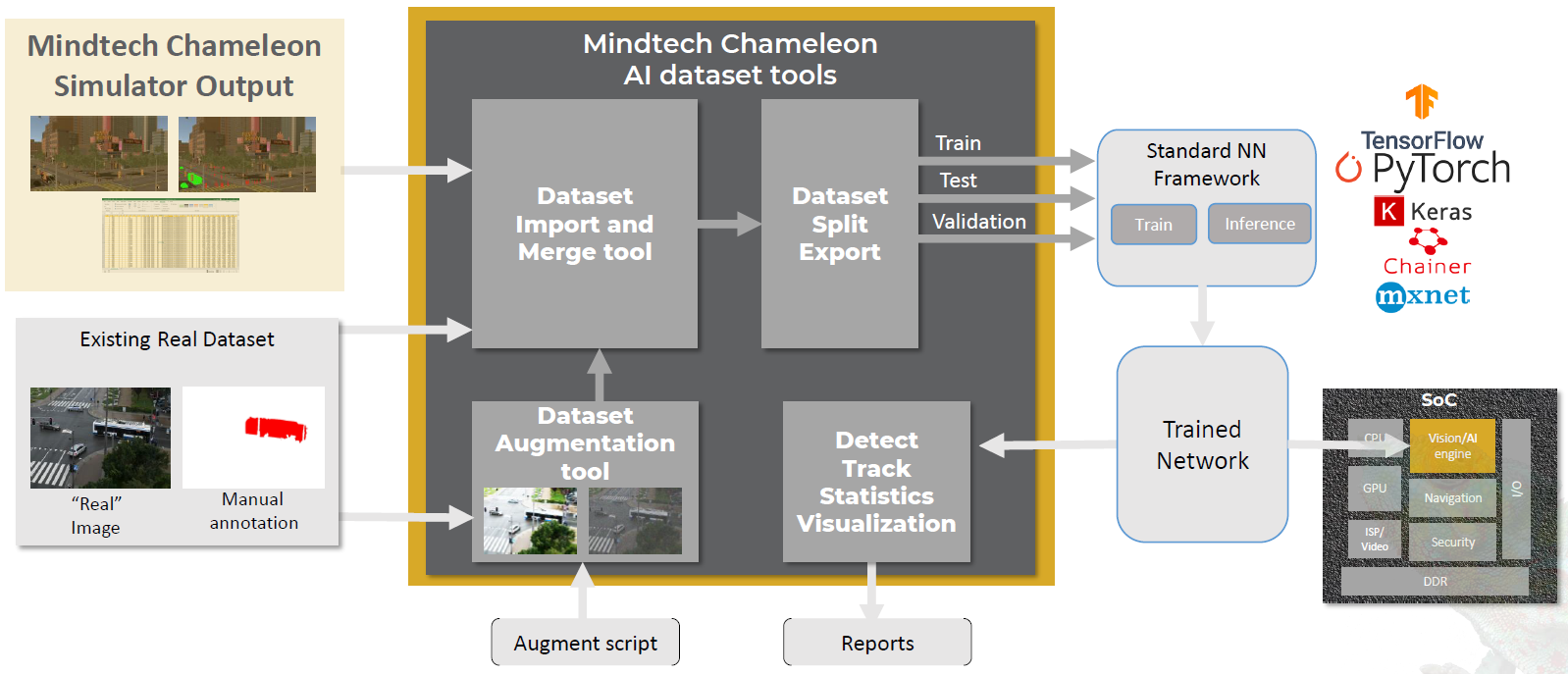
(Click to enlarge. Image courtesy Mindtech.)
Improved AI Results
They showed some results both for facial recognition and for automotive applications. When recognizing faces, adding one million synthetic images to some number of real images gave a significant boost in accuracy. Note that using both real and synthetic images provides better results than synthetic alone, even though the number of synthetic images is larger – sometimes far larger – than the number of real images. It’s probably obvious that the more real images there are as a percentage of the total, the less improvement the synthetic images provide.
It’s important to note that the data below was not generated by Mindtech; it’s from a paper unrelated to their specific product (see the attribution note). Their goal was to show, from independent work, that using synthetic images is a legitimate way to improve accuracy.
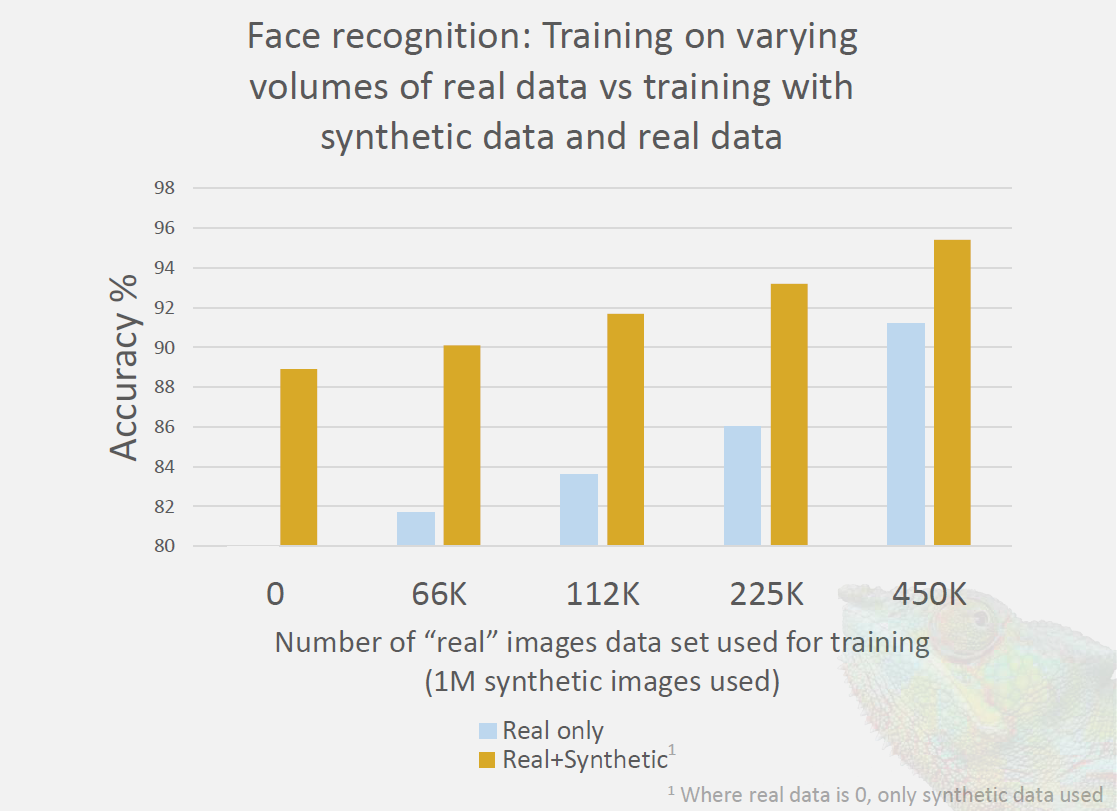
(Click to enlarge. Image courtesy Mindtech.
Data source: “Can Synthetic Faces Undo the Damage of Dataset
Bias To Face Recognition and Facial Landmark Detection?” Kortylewski et al https://arxiv.org/pdf/1811.08565.pdf)
Meanwhile, they compared automobile and pedestrian detection using only an industry benchmark set (KITTI*) versus supplementing with synthetic images created from their Highwai pack of assets. They didn’t specify the number of images, but over half of them were synthetic. Car detection improved by 6.9%; pedestrian detection by 8.4%.
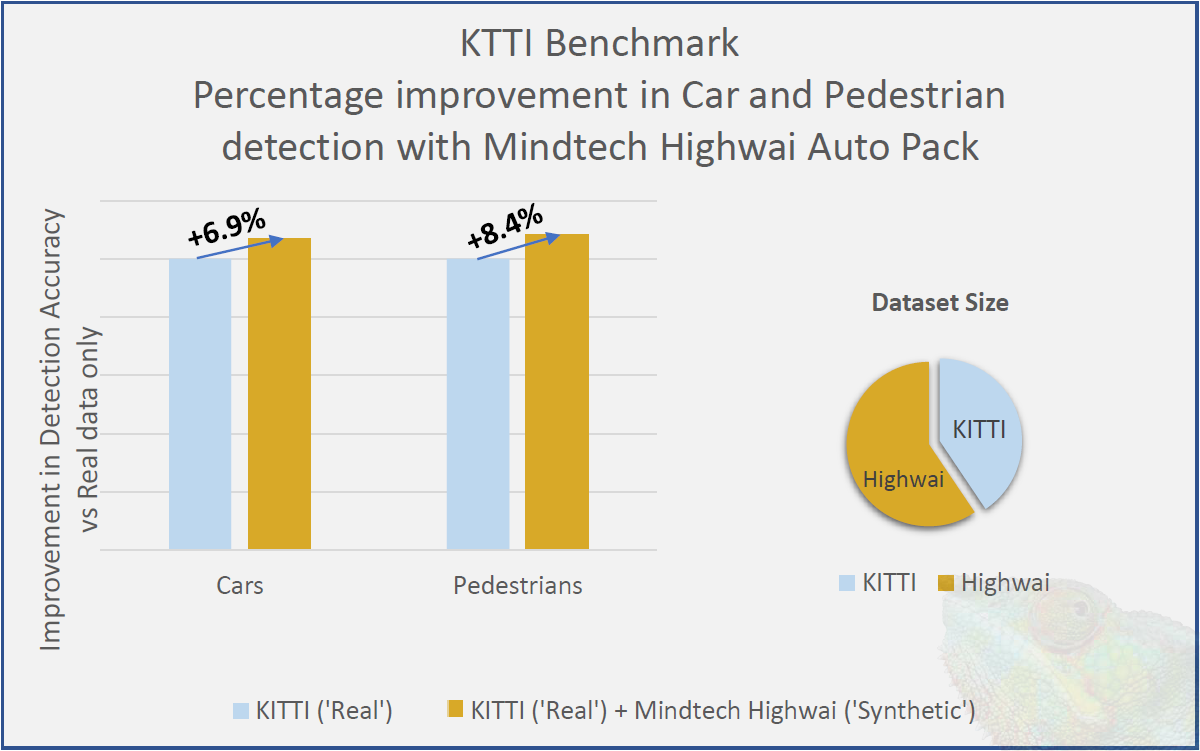
(Click to enlarge. Image courtesy Mindtech.)
I’m going to take it on faith that the quality of results will be a function of the quality of the assets. If people are drawn as stick figures and trees as lollipops, then it’s probably not going to be helpful. A wide variety of realistic images and complex scenes and scenarios takes more time to create, but you get a better bang for that buck than trying to find, get permission to use, and annotate images that cover all of the possibilities that you can get by rolling your own.
*KITTI is a combination of KIT – Karlsruhe Institute of Technology – and TTI – Toyota Technological Institute.
More info:
Sourcing credit:
Chris Longstaff, VP Product Management, Mindtech



What do you think about Mindtech’s approach to training with synthetic images?