


Many years ago, I ordered my first hard drive for my original IBM PC. It was a 5.25-inch Seagate ST-225 half-high, 20Mbyte hard disk drive (HDD). That’s a capacity of 20 MEGAbytes, not GIGAbytes. The ST-225 could barely hold one of today’s shortest compressed video files for YouTube but it represented enormous capacity back then, when IBM PC double-sided floppy disks stored only 720Kbytes. Unfortunately, that Seagate drive failed after just one or two months. Although such an early failure was somewhat unusual back then, reliability was a problem. Hard drives became increasingly reliable over time. They still fail, just not as often.
An HDD is essentially a stack of rapidly spinning, rust-covered (iron oxide coated) platters made initially of aluminum and then later of glass. (Actually, the magnetic coating material these days is cobalt, but the phrase “rust-covered” has stuck with me over the decades.) Read/write heads fly perilously close to the surfaces of these platters. The heads are mounted on a swing arm controlled by a servo motor. With two motors and several heads barely separated from a fast-moving surface, there’s plenty of room for mechanical failure. And failures do happen, catastrophically and without warning.
These days, I no longer have PCs with HDDs. Over the past several years, Flash-based solid state drives (SSDs) have supplanted HDDs as SSD costs have fallen. SSDs have many advantages over HDDs including faster performance, lower operating power, and better reliability. The improved reliability is welcome, but that does not mean that SSDs don’t fail. They do. However, because they’re not mechanical devices and because the wearout mechanisms of Flash memory are so well studied, because they’re endowed with wearout-protection mechanisms, and because they’re so well instrumented, SSDs generally have the good manners to fail on a schedule.
In fact, with the right software, you can query an SSD and find out exactly where it is in its life cycle. I use a program called CrystalDiskInfo. It gives me a comprehensive report on my SSD’s health. The report on the SSD in my work laptop PC looks like this:
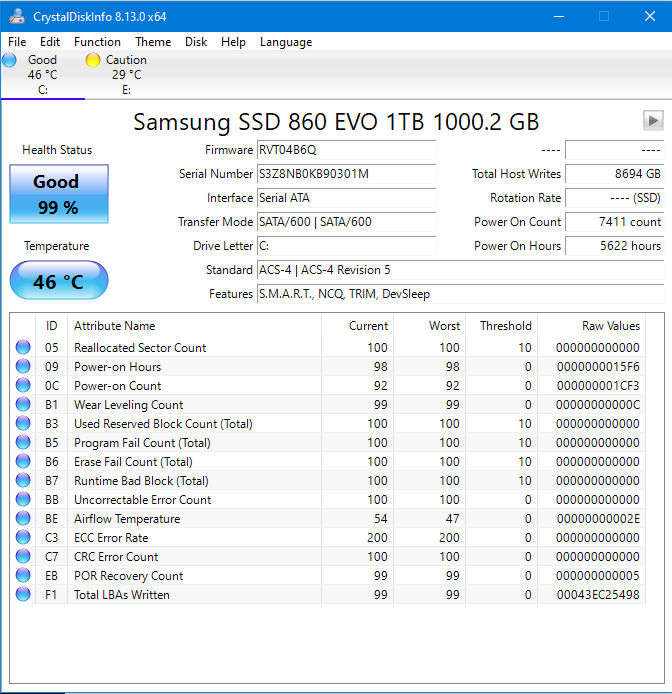
The report tells me that I have a 1Tbyte Crucial MX500 SSD in my laptop and that it thinks it’s in good health, with 99% life left in it. As I write this article, Amazon sells this SSD for less than $100. That’s much less than I paid for my Seagate ST225 nearly 40 years ago. The statistics in the CrystalDiskInfo report come from the SSD’s S.M.A.R.T. (Self-Monitoring, Analysis and Reporting Technology) data, which is generated by firmware that the manufacturer created for and installed in the specific SSD. The CrystalDiskInfo program merely extracts these statistics from the SSD and formats them into a report. (HDDs also generate S.M.A.R.T. data tables.)
The S.M.A.R.T. report shown above looks great. However, I buy my laptops as used computers. Take a look at a report from the Intel 1.6Tbyte SSD that was originally installed in another used laptop that I purchased.
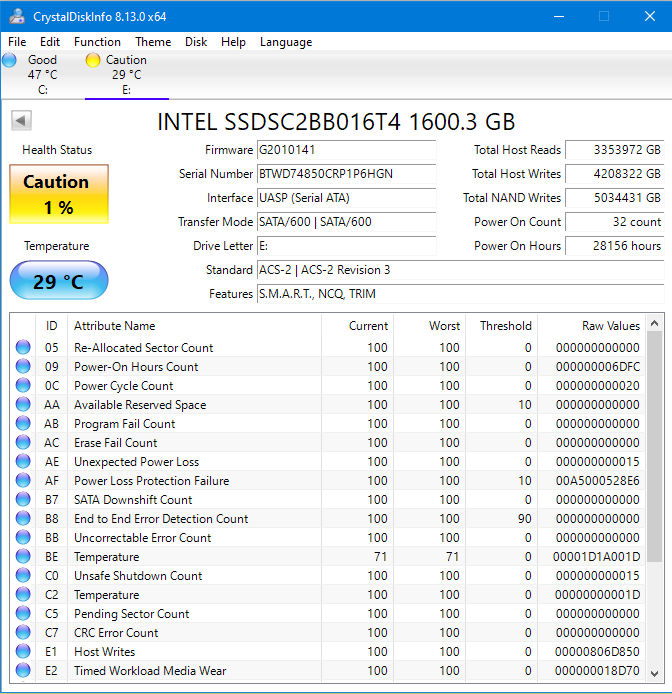
This SSD thinks it’s not very healthy. You can tell from the big yellow rectangle labeled “Caution.” The reason that the SSD doesn’t feel healthy appears in the reporting box labeled “Total Host Writes.” That box says that a host wrote 4,208,322 Gbytes to the drive. That’s more than 4000 Tbytes of data written to a 1.6Tbyte drive, which means that, on average, every Flash memory location on this SSD has been overwritten more than 2600 times. The SSD reports that it’s been powered on for 28156 hours. That’s more than three years of continuous operation, yet this SSD has gone through only 32 power cycles since it was manufactured. Even so, the SSD seems to be performing very well based on the other statistics in the CrystalDiskInfo report. There are no reallocated sectors, no erase failures, no CRC errors, and no end-to-end errors detected. I take that as a testament to the excellent hardware design and the ruggedness of the Intel SSD’s Flash memory. (Note: Intel completed the sale of its NAND Flash and SSD business to SK Hynix late last year, and the assets will move from Intel to SK Hynix over the next few years. Meanwhile, SK Hynix is putting the SSD assets from Intel into a new company named Solidigm.)
Nevertheless, the SSD itself reports that it thinks it has reached the end of its life. I suspect that warning is based far more on statistical assumptions built into the SSD’s firmware than on the failure indicators, which all look excellent. This SSD thinks that it has been written to death and so I replaced it immediately, because the replacement cost for the drive is far less than the replacement cost for the data.
Like any electronic subsystem, SSDs can fail for many reasons. Electronic components do fail. But the failure mechanism of interest here is the wearout failure that NAND Flash memory experiences after many writes. Flash memory chips can be rated for anywhere between 500 and 100,000 writes, or more, before wearout becomes a problem. That number, whatever it is, helps to determine the amount of data that you can write to an SSD before wearing out the SSD’s internal Flash memory. In addition, the SSD’s temperature over time also affects the wearout rate, so that, too, is accounted for.
SSD vendors employ many error-correction mechanisms to ameliorate the effects of NAND Flash wearout failures. Like HDDs, SSDs rely on CRC (cyclic redundancy checking) and ECC (error-correcting codes) to bring down the SSD’s error rates. SSDs employ wear leveling to ensure that write/erase cycles are evenly distributed across the NAND Flash chips in the SSDs and in the individual cells in each NAND Flash chip. If you’re really interested in this topic, you can read a paper that my friend Jim Handy (“The Memory Guy”) wrote for SNIA (the Storage Networking Industry Association) nearly ten years ago titled “How Controllers Maximize SSD Life.”
Because of these failure countermeasures, SSDs tend to fail gracefully after getting past their initial infant mortality stage. HDDs, on the other hand, tend to fail suddenly and catastrophically from mechanical failures such as bearing failures and head crashes. However, I have to say that the jury is still out on SSD versus HDD reliability because of a recent report from Backblaze, a company that runs large data centers. Backblaze published a report in 2021 titled “Are SSDs Really More Reliable Than Hard Drives?” that looked at failure rates for HDDs and SSDs used in its data centers and concluded that SSDs were too new to determine the relative reliability. The report’s final conclusion:
“Given what we know to date, using the failure rate as a factor in your decision is questionable. Once we controlled for age and drive days, the two drive types were similar and the difference was certainly not enough by itself to justify the extra cost of purchasing an SSD versus an HDD. At this point, you are better off deciding based on other factors: cost, speed required, electricity, form factor requirements, and so on.”
(Note: Backblaze published an update to this report days before this article appeared. Their new conclusion about SSDs: “At this point we can reasonably claim that SSDs are more reliable than HDDs, at least when used as boot drives in our environment. This supports the anecdotal stories and educated guesses made by our readers over the past year or so. Well done.”)
Finally, I asked Jim Handy if he’d updated his 2013 SNIA paper. He answered, “Thanks for asking, but no… The biggest change in all that time is that Data Center admins understand their workloads a lot better than they used to, and PC software has eliminated a ton of unnecessary writes. PC software got a lot more SSD-friendly too. For example, iOS used to defrag frequently. That made it perform better than Windows, but it was very tough on SSD write workloads. I heard that Windows started to notice whether storage was an SSD or HDD and eliminated excessive writes, too. All this changed the industry so that high write-load SSDs became less interesting to both applications.”



FYI – looks like you missed it by a few days (you published 9/16, Backblaze published 9/13), Backblaze JUST updated their SSD vs HDD reliability report to say that from their data they can confidently say SSD’s are more reliable than HDD’s.
https://www.backblaze.com/blog/ssd-drive-stats-mid-2022-review/
Thanks! I’ll amend the article accordingly.
I have two SSDs in my tower — my boot C: drive and a separate data D: drive. When I ca,e into work about 2 months ago, all three of my screens were black — I tried rebooting and got a “No boot media found” message. I took it to the local repair center and they said the C: drive was totally shot — they couldn’t get any response from it at all — they hadn’t seen anything like it (I was so proud to be their first 🙂
A sad story indeed, Max. What brand of SSD?
I hang my head in shame because I never thought to ask — now my tower has started to crash once every couple of days — I’m seriously starting to think it may be time to bite the bullet and invest in a completely new machine (I HATE bringing a new machine up) — sad face