


When a lot of people hear the name Flex Logix, their knee-jerk reaction is to think eFPGA (“Embedded FPGA”). While it is certainly true that the guys and gals at Flex Logix have a commanding presence in eFPGA space (where no one can hear you scream), they are also making waves in artificial intelligence (AI) inferencing space (where AI systems will hear you scream).
As an aside, on the off chance you didn’t see the movie, “In space no one can hear you scream” is the iconic tagline of the 1979 science fiction horror film, Alien, which was directed by Ridley Scott and starred Sigourney Weaver as warrant officer Ellen Ripley, who battles a super-scary extraterrestrial lifeform. Swiss surrealist painter, sculptor, and set designer Hans Ruedi Giger won an Academy Award for Best Achievement for Visual Effects for his work on Alien (I still have nightmares).
Just to set the scene, eFPGA technology is FPGA IP that developers of System-on-Chip (SoC) devices can embed in their designs. As I discussed in an earlier column, Flex Logix Joins the Race to the Inferencing Edge, the folks at Flex Logix decided to wield their eFPGA skills with gusto, abandon, and panache to create an inferencing engine for use in machine learning (ML) applications. In the case of their first device, the InferX X1, I went on to say:
The InferX X1 chip boasts 64 reconfigurable tensor processor units (TPUs) that are closely coupled to on-chip SRAM. The TPUs can be configured in series or in parallel to implement a wide range of tensor operations. Furthermore, the programmable interconnect provides full speed, non-contention data paths from SRAM through the TPUs and back to SRAM. Meanwhile, DRAM traffic bringing in the weights and configuration for the next layer occurs in the background during computation of the current layer, which minimizes compute stalls. The combination of localized data access and compute with a reconfigurable data path, all of which can be reconfigured layer-by-layer (in 4 millionths of a second), provides mindbogglingly high utilization along with eyewatering throughput.
Before we proceed, it’s easy to get confused with terms like AI, ML, and inferencing, so here’s a quick summary. Many AI systems use a paradigm called ML, which involves two main aspects: training and inferencing. Designers start by creating an artificial neural network (ANN) framework using something like Caffe or TensorFlow. Training this network model, which is typically represented using 32-bit floating point values, is a computationally intensive process, which can take weeks or months, even when running on very high-performance hardware located in a large-scale cloud computing system. The output of the training process is a trained ML model.
Once created, this model can be optimized for deployment and used for inference processing (a.k.a. inferencing), which refers to the process of providing a response to a stimulus. Common inferencing tasks include object or face detection in images or video, understanding human speech, and identifying cancerous cells in X-Ray images.
One final piece to the puzzle is mini-ITX, which is a 170 mm × 170 mm (6.7 in × 6.7 in) motherboard form-factor that was originally developed by VIA Technologies in 2001. The size of mini-ITX boards, coupled with the fact that they are well suited to fanless cooling, has led to them being widely deployed in industrial and embedded systems requiring high reliability in challenging environments.
The reason I’m waffling on about all this here is that the chaps and chapesses at Flex Logix recently announced their InferX Hawk X1, which is a hardware and software-ready mini-ITX x86 system designed to help customers quickly and easily customize, build, and deploy edge and embedded AI systems.

Hawk X1 (Source: Flex Logix)
In addition to an AMD Ryzen Embedded R2314 SoC processor, the Hawk X1 boasts two of Flex Logix’s InferX X1 AI accelerator chips. Supporting the Linux and Windows operating systems, this application-ready drop-in upgrade for existing mini-ITX systems reduces risk, time-to-market, and development time with respect to creating and deploying edge and embedded AI systems.
At a high level of abstraction, the AI workflow for development and deployment may be visualized as illustrated below.

AI workflow for development and deployment (Source: Flex Logix)
The process commences by gathering data, labelling that data, and performing a bunch of other data-related tasks. The next step is to develop and train the AL model. As was previously noted, these models are usually represented using 32-bit floating-point values, and training them is a time-consuming and computationally expensive process.
Following training, the models are quantized (often into 8-bit fixed-point representations), optimized, and compiled into a form suitable for deployment. This where things get interesting because, once out in the real-world, in addition to performing its intended task, an inference engine may be exposed to data that is different to, and/or better than, the data upon which it was originally trained, so it may be that this data is “fed back up the line” to be incorporated into updated models for future deployment. This is very different to the traditional embedded life cycle, which might be summarized as “deploy and forget” (well, update once a year or “every now and then”).
The way in which the folks at Flex Logix fit into this workflow is depicted below.
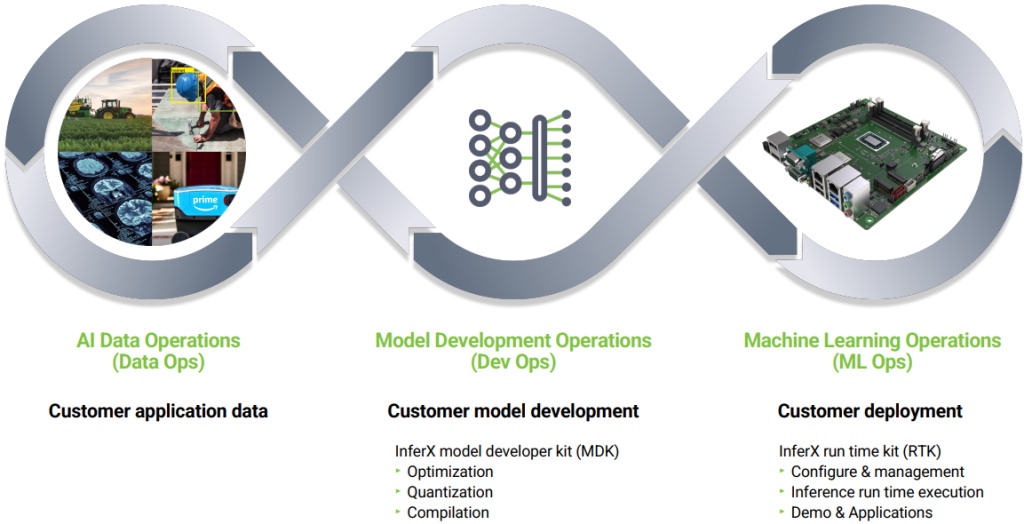
AI workflow for development and deployment with Flex Logix
(Source: Flex Logix)
As we see, Flex Logix takes over once the AI model has been trained. The InferX model developer kit (MDK) is used to perform the quantization and optimization. The two main outputs are a generic 8-bit fixed-point model that can be used to verify accuracy as compared to the original 32-bit floating-point model, and a focused version of this model that is tailored for deployment on the Hawk X1.
Newcomers to the AI arena are usually surprised to discover that 8-bit fixed-point representations are used for inferencing, but these models are much smaller, much faster, and consume only a fraction of the power of their 32-bit floating-point counterparts. If the quantization and optimization are implemented correctly, the inferencing performed by the 8-bit model will be within 1% accuracy of that offered by the 32-bit model.
Think of it this way; it doesn’t matter if an AI says it’s 97% convinced it’s looking at a chicken or if it reports that it’s 96% confident it’s looking at a chicken; either way, we can be reasonably confident that we have a chicken-related situation (some might say a “chicken correlated condition,” but I wouldn’t stoop so low).
The guys and gals at Flex Logix inform me that they’ve benchmarked the Hawk X1 against NVIDIA’s Xavier and Orin products. They say the Hawk X1 offers better performance, is more power efficient, and is lower cost when compared to Xavier. In the case of Orin, they say the Hawk X1 offers about the same performance but is more power efficient and costs less. Thus, the Hawk X1 has much to offer from an overall performance/watt or performance/dollar perspective.
Target markets and applications for embedded and edge-based machine vision systems that can benefit from AI are essentially unlimited. Examples include safety and security, manufacturing and industrial optical inspection, traffic and parking management, retail, robotics, agriculture, and… the list goes on.

Example target markets and applications (Source: Flex Logix)
Actually, another application that just popped into my mind is to equip municipal vehicles that travel all over the place—like police cars, school buses, and garbage trucks—with machine vision systems that can keep a watchful eye (no pun intended) for things that need looking at (again, no pun intended). If anything untoward is observed—broken traffic lights and street lights, missing or damaged signs, problems with the roads (potholes, dead animals, other debris), trees and vines impinging on power lines—the system could automatically alert the appropriate folks to come and sort things out.
I really do think that we are heading into some interesting times and that systems like the Hawk X1 from Flex Logix are going to take us there. How about you? Do you have any thoughts you’d care to share about any of this?


