


“One day you wake up and realize the world can be conquered…” – Austin Grossman
Dr. David Patterson, the newest recipient of the ACM’s A.M. Turing Award along with John Hennessy, launched into his opening remarks during his talk about the past, present, and future of processor and ISA (instruction set architecture) design at the annual dinner meeting of the IEEE-CNSV (IEEE Consultants’ Network of Silicon Valley). Meanwhile, I find that I’m sitting across the banquet table at Santa Clara’s China Stix Restaurant from Stan Mazor, who worked with Ted Hoff at Intel to define the ISA for the Intel 4004—the world’s first commercial microprocessor. You probably could not have a more appropriate dinner companion for a comprehensive talk about computer architecture.
ISAs were the central theme for the evening, and Patterson’s talk focused on where ISAs came from, how they’ve evolved over the decades since the 1940s, where they are now, and where they’re going. Some of the talk mirrored a similar presentation that Patterson presented earlier this year (see “Fifty (or Sixty) Years of Processor Development…for This? ‘Dennard Scaling and Moore’s Law are dead, Now what?’ – a 4-act play by Dr. David Patterson”) but Patterson had greatly expanded the present and future portions from his previous talk. Briefly, Patterson’s message is that we are now entering into a golden age for computer architecture.
Spoiler alert: Patterson’s version of the future for ISAs looks a lot like the future of the RISC-V ISA and processor architecture. No small surprise. Patterson is Vice-Chairman of the RISC-V foundation, and the RISC-V architecture grew out of Patterson’s work at UC Berkeley nearly a decade ago.
But first, a Review of Computer History.
Back in the early days of big iron, when mainframe design served as the computer industry’s focus, IBM found that it had evolved not one, not two, but four successful and mutually incompatible mainframe architectures serving four distinct markets:
- The 701 (later the transistorized 7094) serving the commercial scientific market.
- The 650 (later the 7074) billed as “the workhorse of modern industry.”
- The 702 (later the 7080) aimed at business computing.
- The 1401 (later the 7010) designed to handle large-scale accounting.
At this stage in computer evolution, long before there were industry standards for I/O interfacing, every mainframe computer system required a unique set of peripherals (printers, tape drives, disk and drum drives, punched-card readers, terminals, etc.) with unique interfaces. IBM concluded that supporting four unique ISAs, in four lines of mainframe computers, with four lines of peripherals, and needing different operating systems and software for each ISA was an unsustainable business model.
So IBM bet the company on one unified ISA for all of the markets that it served. It wanted one ISA that could stretch from low-end machines to high-end ones. It did this using an architectural innovation called microprogramming developed by Maurice Wilkes back in 1951. (Wilkes received the ACM’s A.M. Turing Award for his work in 1999.)
Microprogramming inserts an interpreter between an ISA’s machine instructions and the hardware. In effect, it breaks down ISA instructions into one or more simpler steps that are then executed in one or more clock cycles. In the early 1960s, which predated the large-scale use of ICs, logic hardware (gates and flip-flops) was far more expensive than memory—particularly ROM, which was also faster than RAM at that time. Microprogramming essentially trades off memory for hardware by breaking each ISA instruction into sequences that can be executed using simpler hardware.
IBM exploited microprogramming by developing one ISA—the IBM System/360 ISA—that it then realized using radically different hardware architectures to meet the cost requirements for each of the four markets served by previous-generation machines. Prior to this, no computer company had the vision or the moxie to create a market-spanning ISA.
IBM implemented the same ISA in a range of IBM System/360 machines as shown below:
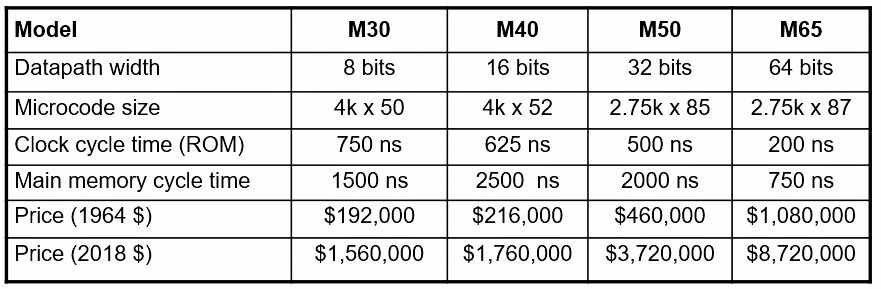
Note that the datapaths and microprogram-ROM clock cycle times for each of these IBM System/360 models range from 8 to 64 bits and from 750 down to 200 nsec. Wider datapaths and faster microprogram ROMs make faster, but more expensive, machines. (Fred Brooks Jr. managed the IBM System/360 project and received the ACM’s A.M. Turing Award for his work in 1999.)
IBM won the bet and its System/360 Series dominated the mainframe markets for a long time. Microprogramming was another big winner thanks to the IBM 360 project’s success, and this helped set the stage for what happened next.
The Rise of CISC
With the successful introduction of semiconductor memory ICs in the 1970s, memory chips enabled larger control stores, which in turn encouraged the development of much larger ISAs. This trend was perhaps best epitomized by the DEC VAX 11/780 minicomputer, which had a 5K-word microprogram store with 96 bits per word. Compare that number to the largest member of the original IBM System/360 Series—the M65—in the table above and you’ll see that the VAX 11/780’s microprogram store was about twice as large.
The VAX ISA included a huge number of programmer-friendly addressing modes and featured individual machine instructions that performed complex operations such as queue insertion/deletion and polynomial evaluation. These complex instructions were considered more programmer friendly at a time when programmers were still largely writing programs in assembly language.
Moore’s Law was also morphing the IC into the microprocessor as on-chip transistor counts grew. Gordon Moore observed this and decided that Intel needed to follow IBM’s lead and develop one instruction set to end all instruction sets for its microprocessors.
The resulting iAPX 432 ISA became the microprocessor industry’s great white whale. The architecture implemented an object-oriented, 32-bit, protected address space at a time when simple 16-bit address spaces with no memory protection was the norm. As a result of the design’s complexity, the first (and only) iAPX 432 microprocessor implementation required several chips because the IC process technology of the day just could not fit all of those transistors into a single IC. The multi-chip iAPX 432 implementation took six years to develop, and it ran very slowly. The iAPX 432 microprocessor was an elegant failure that ultimately produced Intel’s biggest success. (Gordon Moore won many awards but not an A.M. Turing Award.)
With the iAPX 432 project mired in trouble and delays, Intel needed to bring an interim next-generation processor to market to replace the aging 8-bit 8080 and 8085 microprocessors. In a crash 52-week project, Intel’s engineers developed the 8086 microprocessor—essentially based on a somewhat enhanced, 16-bit version of the 8-bit 8080 ISA. Architects spent a whole three weeks on defining the 8086 ISA. Despite its rush to market, IBM picked the 8086 microprocessor, in the form of the 8088 variant with an 8-bit bus, for the IBM PC. IBM expected to sell 250,000 PCs, but, instead, the company sold 100 million of them. The 8086 and the x86 ISA became an overnight success. It also became the one ISA that ruled them all (all PCs and servers, anyway) for decades.
The Rise of RISC
Meanwhile, a significant change to software development was beginning during the 1980s. Software engineers were switching from assembly language to HLLs (high-level languages) to achieve better productivity. Compiler output became more important than assembly language convenience when defining ISAs.
John Cocke, who had worked on IBM’s experimental ACS optimizing compiler in the 1970s, observed that compilers limited to simple instructions produced code that ran three times faster than compiled code that used more complex instructions running in the same machine. The reason’s rather simple, considering the widespread use of microcode at that point. Complex instructions require longer microprogram execution sequences, which in turn require more microcode clock cycles. For example, the DEC VAX 11/780 minicomputer averaged ten clocks per instruction.
Cocke led IBM’s 801 computer project starting in 1975. This project simultaneously developed an optimizing compiler in conjunction with a closely coupled hardware implementation of the ISA. The result is considered the first RISC machine. (John Cocke received the ACM’s A.M. Turing Award for his work in 1987.)
In a few years, RISC microprocessor architectures supplanted many CISC microprocessor architectures because of the superior results achieved with optimizing compilers. Intel perceived the threat to its x86 ISA and put 500 engineers on a project to convert the x86 CISC architecture into a RISC architecture by creating front-end hardware to convert x86 instructions into simpler operations ahead of the datapath. The result was a big performance jump. Since then, RISC architectures have come to dominate processors for desktop PCs and servers in addition to nearly every other microprocessor application.
There’s one more bit of processor architectural history that’s relevant to Patterson’s new golden age. If RISC is good, thought computer architects, then parallel RISC execution engines with wide instruction words built from multiple, concatenated RISC instructions should be better, thanks to the added parallelism. This thinking resulted in the development of VLIW architectures. VLIW microprocessors turned out to be very buildable, and the most famous VLIW architecture is likely Intel’s Itanium microprocessor series. Unfortunately, good VLIW compilers turned out to be impossible to write for a variety of reasons—and Itanium sank.
The Emperor’s New Clothes: DSAs, DSLs, and open ISAs
And so, said Patterson, the future’s not CISC and it’s not VLIW. It’s RISC. But the future will not look like the past. The industry has seen the end of Dennard Scaling; Transistors are not getting faster nor are they consuming less power with each new process node. The industry has also seen the end of Moore’s Law. Doubling time is stretching from years to decades.
At the same time, code security is in a sorry state. “It’s embarrassing how bad security is,” said Patterson. Computer architects have bet that there will be no software bugs. It’s a bad bet. It has always been a bad bet.
Microprocessors must be made more secure and must be able to deal with buggy software, said Patterson. The recent Spectre exploit performs an attack on speculative instruction execution, a feature that’s become common in many modern microprocessors. According to Patterson, the Spectre exploit can leak information to the outside world at a rate of more than 10Kbps. More such exploits can be expected in the future.
Welcome to the Golden Age?
If semiconductor technology offers a less expansive future due to the deaths of Dennard Scaling and Moore’s Law and if security is in a sorry state, how can this be the start of a new golden age for computer architecture?
Patterson’s answer: DSAs (domain specific architectures).
DSAs perform certain specific tasks better because they are not general purpose. Instead, they solve classes of problems that offer more opportunities to exploit parallelism. DSAs also use memory bandwidth more efficiently because data types can be matched to the problem being solved. For example, you don’t need to use floating-point numbers to represent everything. Sometimes, a small integer provides the needed accuracy.
The reduced size of the resulting data structures allows DSAs and domain-specific processors to be designed to directly manipulate higher-level data structures such as matrices and tensors. For example, Google’s TPU (Tensor Processing Unit) uses a massive array of 65,536 8-bit multiply/accumulate (MAC) units to accelerate one specific application: DNNs (deep neural networks).
DSAs require DSLs (domain specific languages) along with compilers developed specifically to address the unique needs of the targeted domain. Such DSLs already exist and include OpenGL for graphics, P4 for networking, and TensorFlow for machine learning.
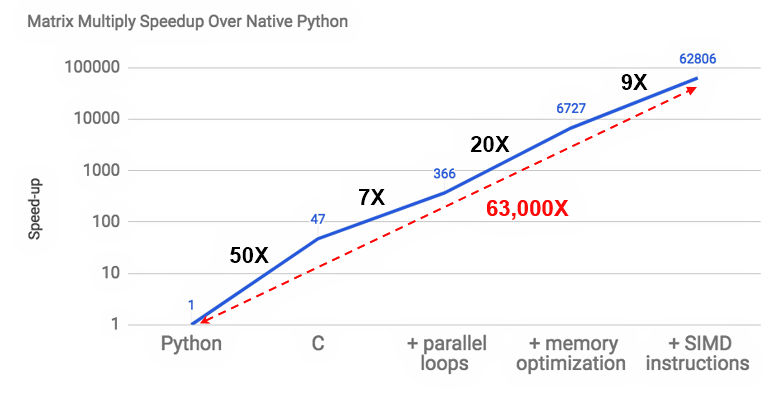
There’s a tremendous opportunity to speed the execution of domain-specific applications that exploit the targeted domain’s unique opportunities for parallelism and tailored data structures. Patterson projected this chart as proof that there’s a factor of 63,000x potential performance improvement for Python code using DSAs and appropriate compilers:
Then Patterson switched themes to address the security problem. His solution is open ISAs. “Why should there be open-source compilers but not open-source ISAs?” he asks. He answers his own question by saying that the open RISC-V architecture is proof that there can be one open-source ISA that can span applications from the replacement of simple control processors to DSAs augmented with domain-specific datapaths and instructions. Security people like things that are open, said Patterson, because trap doors are harder to hide if everyone’s looking for them in the open-source code.
Patterson concluded, “That’s my simple goal for RISC-V, world domination.”
Note: The full slide deck from Dr. Patterson’s talk is available here.



Well, he never got around to anything about RISC-V being the answer — only his pipe dream of world domination.
This quote “DSAs perform certain specific tasks better because they are not general purpose. Instead, they solve classes of problems that offer more opportunities to exploit parallelism. DSAs also use memory bandwidth more efficiently because data types can be matched to the problem being solved. For example, you don’t need to use floating-point numbers to represent everything. Sometimes, a small integer provides the needed accuracy.” can be translated to “Custom designed hardware can beat the pants off a CPU”
There are 2 basics that are at the core of computing: Assignment Expression evaluation and control condition evaluation. Control conditions enable assignments or blocks of expressions.
The AST(Abstract Syntax Tree) has everything needed to design hardware(DSA) from source code and certainly does not rely on any RISC ISA.
So the magic of RISC-V open source totally escapes me. And the number of memory accesses is another issue. i.e. Fetch a load instruction, fetch one operand , fetch a load instruction, fetch the second operand, fetch the add instruction, and finally fetch a store instruction and store the result. How many levels of cache does it take to feed a RISC-V?
IT TAKES A LOT MORE THAN AN ISA TO BUILD A COMPUTER.
It so happens that I am working on a programmable DSA that I call CEngine and the CSharp AST is at the core of it.