


The upshot: The Tide Organization tested password splintering and, in one study, found an increase of 14,064,094% in security as compared with “conventional, centralized alternatives.”
Passwords are this horrible thing that we can’t seem to escape. If we’re doing it right, each of the 300-odd passwords we need will be random, long, changed every month, and, of course, never written down anywhere. Yeah right. So… how can we make passwords more secure in the real world?
You want to be able to control your own passwords, but you have to trust the entity that’s storing your password – the merchant or group. And, while you might trust their intentions, that trust hasn’t always been well repaid, given the number of huge hacks of account databases. Is that something we simply have to live with as a modern fact of life?
Granted, any business worth its salt isn’t going to store your password in the clear. It will store a hashed version of the password. So, when you log in, they hash the password you enter to see if it matches their stored hash. The hash always returns the same value, so there can be a deterministic match that lets you log on.
That said, the longer the password, the more unique the hash will be. It’s literally possible for someone to establish a correlation between passwords and hashes to at least help to make better password guesses in many cases, even though it’s mathematically impossible to reverse the hash outright. So it’s still not good if someone hacks an account and gets the hashed version of your password. This aspect of password length will turn out to be important for the whole splintering thing. But I’m getting ahead of myself…
The Tide Foundation has an idea to mitigate this risk. They’ve proposed a decentralized password storage scheme that largely removes the need for trust. They call it password splintering. It’s layered over another notion of secret sharing, and I’m going to try to motivate how they work here.
I’ll start by saying that the details of this whole thing are pretty daunting. Each time I thought I understood what was happening, I’d try to describe it – and take myself into some contradiction or something else that made it clear that I didn’t really understand it as well as I thought. There’s a pretty beefy white paper that gets into lots of detail, as well as a research paper documenting their results; I’ll link to both below so that you can immerse yourself if you wish.
I’d like to start, though, by inoculating early against a couple of possible points of confusion (yes, guilty as charged). First, we’re going to talk about some secret that’s stored in a decentralized fashion via secret sharing. For example, it might be a private key needed for decrypting a message. Then we’re going to talk about the password that authorizes you as the person who is allowed to access that secret.
It’s easy to confuse those two things – or, at least, it was easy for me to get confused (I know, not news), so I thought it best to establish this outright. The secret isn’t the same as the password, even though the password should be secret. So secret sharing is about the secret, and password splintering is about the password.
We’re also going to see lots of splitting up of things. The secret will be stored in a distributed fashion, and the password will also. These aren’t the same splitting, and they’re mathematically different. So we need to keep those two notions separate.
The context of the paper is that of a crypto-wallet, which gives access to blockchain-oriented assets, but the password splintering isn’t about cryptocurrency per se. That said, there is an unrelated blockchain element to password splintering, so it’s easy to conflate the blockchain currency application with the use of a blockchain for password splintering. The only blockchain element we’ll discuss here is the latter one.
Also, just for clarity, I’m going to define a term that I use frequently: the “owner.” This is the owner of the secret. If this is about a crypto-wallet, then it’s the owner of that wallet. It is the owner that has a username and password for accessing the system.
So, with those cautionary notes, let’s dig in.
Secret Sharing
The fundamental notion of secret sharing involves a distributed form of encryption. The idea is that a secret can be run through a reversible function that generates a unique polynomial. You can pick an arbitrary number of points off of the polynomial, and, if you have some threshold number of those points (without having the whole curve), you can then interpolate the curve and, from that, recover the secret. This is known as threshold encryption.
Instead of storing the secret in one place, the different points from the curve can be sent to different services called Orchestrated Recluders of Keys, or ORKs. These are nodes in an authentication network. If you authenticate correctly to an ORK, it will provide a partially decrypted version of a snippet of the secret that it stores. It would appear that the splitting math is distributive, such that combining the decrypted snippets gives the same result as decrypting the full secret. Although the secret is only partially decrypted at this point.
The whole notion of threshold encryption means that you don’t have to get a snippet from every ORK, since they may not all be available. You need only enough to rise above the threshold, from which you can then interpolate the curve. The issue of a threshold isn’t a vote, however; it’s just a quorum. The “vote,” if you want to look at it that way, has to be unanimous. If many more than the threshold return a result and even one of them fails authentication, then the whole thing fails, regardless of whether the number of passing ORKs is above the threshold. We’ll talk more about what “failure” means in a sec.
Because each ORK has only part of the secret, it can return only a partially decrypted snippet of the secret. Once some number of snippets exceeding the threshold are received, they can then be used to interpolate the polynomial curve and recover the full partially decrypted secret. From there, the secret can be decrypted the rest of the way. (I refer you to the study below for the math.)
What happens if the authentication in one or more of the ORKs fails? It doesn’t send back an alarm declaring the failure; instead, it returns a random result instead of the partially decoded snippet. So, for instance, in the case of a private key, you’ll go through all of the work to reassemble the key, only to have it fail in decrypting a message. And you won’t know which ORK failed. That makes it much harder to game the system.
Splintering
Now we come to the matter of the password, which is important to this whole authentication thing. This is what the owner uses to log into the system and to get access to the secret. Used on its own, secret sharing would have the hashed password stored on all of the ORKs for authentication to the secret. But I mentioned above that longer passwords tend to have more unique hashes, while shorter ones tend to “collide” more. This brings us to the concept of splintering, which refers to the breaking up the password into shorter splinters.
Each splinter is sent to a different ORK. Authentication on each ORK is via the splinter that it contains, not the full password. To further improve security and hinder collusion between malicious ORK operators, each splinter is hashed and salted with the username and the ORK identifier.
There’s no way for anyone but the owner to know which splinters went where. But the owner is accessing all of this through a stateless web application – accessible by multiple computers and phones and such – meaning that the application has no persistent knowledge of what went where. So, when we try to authenticate to each server, how do we know which splinter to use with which server? In fact, in a scaled-up network of millions of ORKs, how do we know which subset has the splinters for a particular user?
This is where we invoke the blockchain thing. The public blockchain is used by the ORKs as an immutable repository, but entries aren’t in the clear. ORK-specific entries – like the password splinter that it has – are encrypted and indexed by a hash of the username, salted with the ORK’s identity. That means that an ORK can read only entries that pertain to itself.
In addition, information on participating ORKs – a list of ORKs that have secrets for a specific user – is also on the blockchain, indexed by a hash of the username alone. Any ORK can pull that list off of the blockchain, although it can’t get to the deeper ORK-specific information for the other participating ORKs (due to the extra salting). The owner can reassemble the knowledge of which splinter went where through a mathematical function of the username, password, and the list of participating ORKs. (That math is in the white paper.)
The whole process is shown in the following figure, although, apparently, that drawing is somewhat outdated. You get the idea, but they’ve moved beyond this but haven’t documented it yet. In this figure, the consumer is what I’ve been calling the owner. The “vendor” is some company that wants to release some encrypted info, but needs to authenticate you first to ensure that you should have that info. Today, without this system, that vendor would have the hash of the owner’s password.
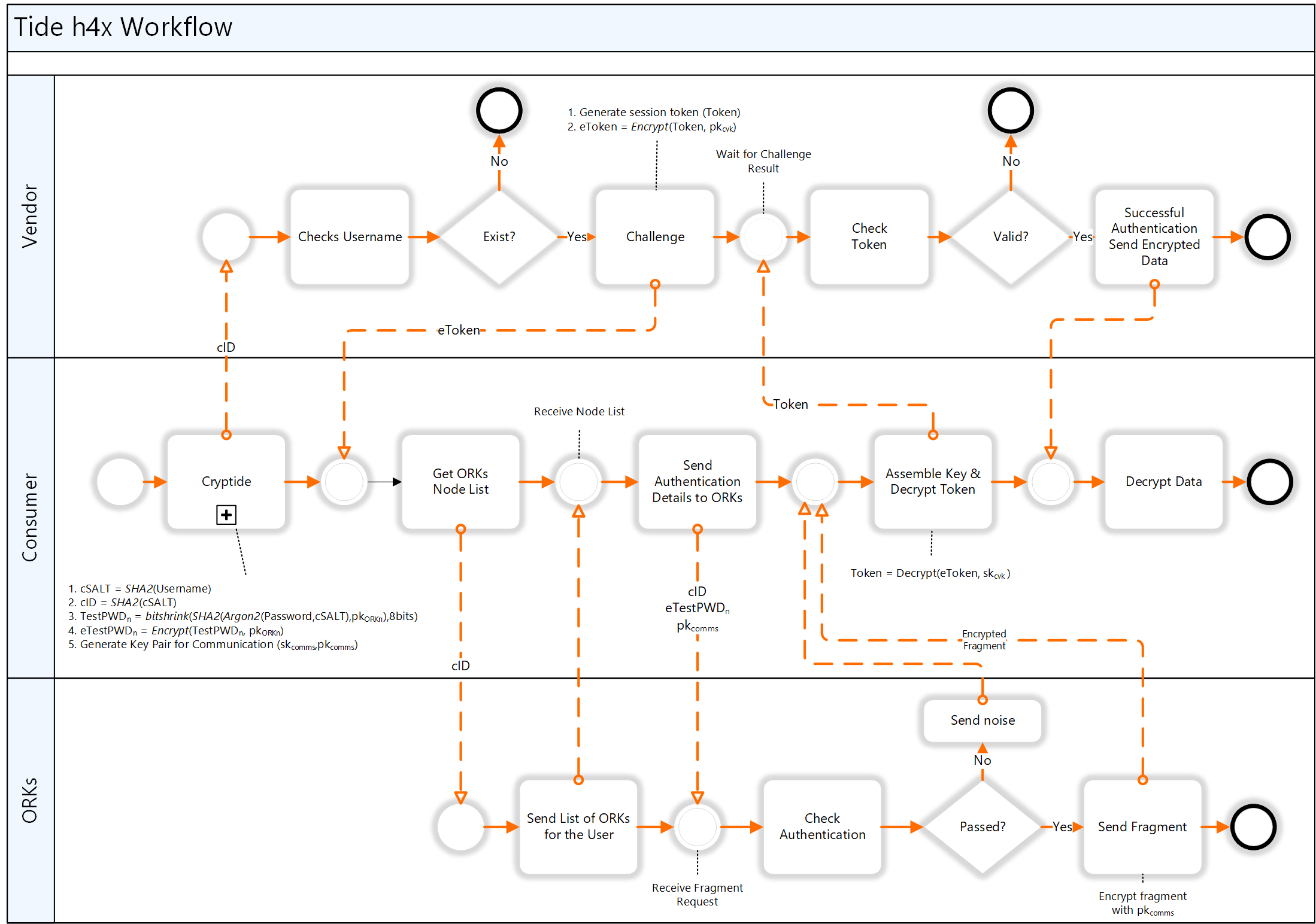
(Click to enlarge. Image courtesy the Tide Foundation.)
Because the username is critical to authentication, you might think that would be a weak point. But, in this system, there is no database containing usernames. Only the owner has the username and password. If one of that owner’s local systems (laptop, phone, whatever) is hacked, then the gig is up. But that’s a lot harder for an attacker to do with multiple users – there’s no grand list to pull down – so they consider this to be much tighter security. And two-factor authentication can help to protect against unauthorized access in the event of such hacking (although, to be clear, that’s an optional aspect unrelated to the main discussion here).
The basic idea, then, is that, rather than a single uniquish hash residing on each ORK, each ORK gets a not-so-unique hash, and you have to pass authentication in each ORK to get it to release a partially decrypted snippet of the secret. Where authentication fails, you get the fake snippet.
Since shorter splinters create more hashing collisions, what’s the optimal splinter length? They did a study – the ultimate subject of the research paper – that looked at this question using a pre-publicized LinkedIn hack with usernames and passwords. This was, in essence, a case study, trying to figure out what the optimal splinter size was. The smaller the splinter, and/or the less common the password, the higher the security.
It was through this effort that they came up with a 14,064,094% improvement using 8-bit splinters. That’s not a hard, fixed number characterizing the whole technology. Nor is it a measure of improvement over some other approach; it’s as compared to no security. It reflects just the one study, comparing what could have been done with splintering against the known table of values they had.
They use other techniques to boost security, such as the use of the intentionally resource-intensive Argon2 key-derivation function to slow down anyone trying to throw lots of guesses at the system. And ORKs will throttle any DDoS attempts.
You can think of secret sharing and password splintering as root technology. The Tide Foundation has built a number of scenarios for how this could work for online wallets, cryptocurrency, smart contracts, and other digital transactions that need signatures or authentication to a password. The owner might have to approve each transaction, or a system could be created with policies and choices that the user creates so that transactions can proceed without intervention each time. But all of those things are beyond the scope of the basic password-splintering scheme.
There is more – oh, so much more – available in the links below.
More info:
Sourcing credit:
Yuval Hertzog, Co-Founder at the Tide Foundation



What do you think of this approach to splitting up passwords for better security?