

I remember the heady days of the 1970s, when new and exciting 8-bit processor architectures were sprouting like metaphorical mushrooms. I’m sure that, like me, you are thinking of little beauties like the 8008 (1972), 8080 (1974), and 8085 (1976) from Intel, the 6800 (1974) from Motorola, the 6502 (1975) from MOS Technology, and the Z80 (1976) from Zilog.
However, there were many other contenders that deserve mention, such as the 8-bit PPS-8 (1974) from Rockwell International, which succeeded the 4-bit PPS-4 (1972). As an aside, Rockwell Automation, which spun off from Rockwell International in 1985, will forever be associated with its Retro Encabulator, the likes of which we’ll never see again (if we’re lucky).
One of the reasons those days were so exhilarating is that no one really knew what they were doing. I don’t mean this in a derogatory way—the designers of those early processors were extremely innovative and clever—it’s just that this was a nascent field and everyone had different ideas of how to do things.
For example, when I encountered my first processor, an Intel 8080, I didn’t give much thought to the fact that it had only a single accumulator. It all made sense, and I simply assumed this was the way things were meant to be. So, you can only imagine my surprise and delight when I was introduced to the Motorola 6800, which brazenly flaunted two accumulators. I was still reeling with the implications of dual-accumulator architectures when I met the Zilog Z80 with its eight 8-bit registers and associated instructions that operated on register-to-register data.
I’m constantly discovering new nuggets of knowledge and tidbits of trivia about these foundational machines, such as the fact that—even though it predominantly had an 8-bit data path—the Z80 actually featured a 4-bit ALU at its core (see also A 4-Bit CPU for the 21st Century).
I’m unfamiliar with the PPS-4 and PPS-8 architectures, but I’m sorely tempted to learn more, especially since I just learned that Adam Osborne, the creator of the hugely successful Osborne 1 (which introduced the “luggable computer” category and was one of the fastest-selling machines of its era), described the PPS-8’s architecture as “most unusual… more powerful… also one of the most difficult to understand.” High praise indeed! We should all aspire to create an architecture of this ilk.
But we digress…
As per my aforementioned 4-Bit CPU for the 21st Century column, I’m currently captivated by the concept of creating a novel 4-bit CPU architecture of my own (one whose convoluted complexities would have Adam Osborne giggling with glee). In this case, I’m happily unconcerned with mundane issues like performance and power consumption. Instead, my main design criteria are that my implementation must be (a) educational, (b) interesting, and (c) involve a lot of light-emitting diodes (LEDs) (I’m a modest man with simple needs).
In contrast, I was just chatting with Brandon Lucia, Professor at Carnegie Mellon University and Co-Founder and CEO of Efficient Computer. Unlike me, this company’s mission is to create extremely efficient, high-performance, low-power processors.
Deep in the mists of time, about a decade ago—back when today’s data-driven AI workloads were still more commonly referred to as machine learning (ML)—a small group of computer architects found themselves increasingly frustrated. The team, which would later form Efficient Computer, wasn’t trying to build the next desktop or server processor. Instead, they were asking a much harder question: How do you perform meaningful computation in environments where energy is brutally constrained?
Think systems intended for use in outer space. Think battery-powered devices that must last for years. Think platforms so energy-starved that computation can happen only in short bursts. In all these regimes, the usual assumptions about processor architectures simply collapse.
So, the team did what good researchers do: they started by measuring. And what they found was, frankly, shocking. Consider a simple instruction like A + B. One might reasonably assume that most of the energy consumed while performing this operation goes into… well… adding the two numbers. In reality, roughly 99% of the energy is spent on everything except the addition itself: fetching the instruction, decoding it, moving data around, reconfiguring internal circuitry, and generally paying what amounts to an enormous architectural “overhead tax” (sad face).
This wasn’t an implementation problem. It was a model problem stemming from the fact that most of today’s general-purpose processors—whether CPUs in servers or CPUs embedded inside microcontrollers—still trace their lineage back to the von Neumann architecture or its close cousin, the Harvard model. Fetch, decode, execute, and repeat, repeatedly. Although this model has served the industry incredibly well for decades, it’s also spectacularly ill-suited for extreme energy efficiency. Ultimately, it was this realization that became the “seed crystal” that grew into Efficient Computer.
Fast-forward to today, and the industry’s response to rising computational demand has been… “enthusiastic,” to say the least. We now see a steady stream of chips that pair one or more general-purpose CPUs with highly specialized accelerators, most commonly neural processing units (NPUs), that promise eye-watering gains like “100X” or even “1000X faster.”
The problem isn’t that these claims are false; rather, that they’re incomplete. What often gets quietly “swept under the rug” is Amdahl’s law, which reminds us that the overall speedup of a system is fundamentally limited by the portion of the workload that cannot be accelerated. In other words, you can make part of the code arbitrarily fast, but the rest still matters. I tend to think of this as the computing equivalent of the “a chain is as strong as its weakest link” proverb.
Consider realistic real-world edge-computing environments such as robots, industrial controllers, and automotive sensor-fusion systems. These applications don’t rely solely on neural networks. They are a messy mix of DSP pipelines, control loops, optimization routines, signal processing, logic, safety checks, scheduling, and—yes—some AI or ML. If half of that workload runs on a shiny parallel NPU and the other half runs on a ratty old sequential CPU, the best possible outcome is a 2X overall speedup. Even if you make the NPU infinitely fast, you still can’t do better than that.
Developers discover this the hard way. They’re lured by tempting promises of orders-of-magnitude gains, only to find that large chunks of their code quietly fall back onto the CPU, where efficiency and performance collapse right back to where they started. Not surprisingly, they find this to be frustrating, confusing, deeply unsatisfying, and lots of other “-ings” too numerous to mention.
The Efficient Computer team’s conclusion was simple but radical: you can’t optimize part of the application and call it a win. If you want real gains, especially in energy-constrained systems, you need to accelerate everything!
That insight led the folks at Efficient Computer to a bodaciously bold goal: to design a truly general-purpose architecture that could efficiently handle all the computation found in complex cyber-physical systems—DSP, control loops, optimization, sensor fusion, analytics, and AI/ML—without shunting half the workload onto a power-hungry legacy CPU.
The result is a fundamentally different approach to computing, embodied in the company’s first commercial silicon: the Electron E1.

The Electron E1 (Source: Efficient Computer)
At the heart of Electron E1 is what Efficient calls the Fabric with a capital “F” (that’s how good it is!). Rather than a single instruction pipeline, the Fabric is a 12 × 12 spatial array of tiles, each capable of hosting computation. Instructions are placed onto tiles and remain there—often for long stretches of time—while data flows directly between them over an on-chip network composed of simple wires and multiplexers, rather than power-hungry buffers. Within the Fabric, Electron E1 employs a 32-bit datapath that natively supports integer arithmetic at multiple widths (32-, 16-, and 8-bit) as well as 32-bit floating-point, thereby enabling everything from control logic and DSP to numerically sensitive workloads to execute efficiently on the same architecture (Efficient also evaluated lower-precision floating-point formats, but customer feedback consistently favored FP32 for its robustness and ease of porting real-world applications).
The reason I used the “spatial” qualifier in the preceding paragraph is to emphasize that where an instruction runs matters and that computation is mapped to physical locations on the chip, not just to an abstract collection of identical resources.
In turn, this leads us to Efficient Computer’s toolchain. This centers around effcc, which unpretentiously stands for “Efficient Computer Compiler” (the effcc moniker is intentionally reminiscent of gcc or clang and is intended to feel familiar rather than exotic).
From a developer’s point of view, effcc behaves like a conventional compiler: you feed it a high-level front-end representation, and it produces an executable. Under the hood, however, effcc does something very different: instead of compiling to a sequential instruction stream, it maps the program into a spatial dataflow representation, assigns instructions to tiles, and generates both code and configuration for the Fabric.
I bet I know what you’re thinking. You’re thinking, “What did he mean by ‘high-level front-end representation’ in the preceding paragraph?” You may also be thinking, “Oh no, not yet another esoteric new programming language to learn!”
Well, fear not, my brave, because the guys and gals at Efficient Computer have you covered. In Efficient Computer’s toolchain, effcc is the back end that targets the Fabric, but it’s fed by a host of familiar language and framework front ends, the key ones being as follows:
- C and C++: The primary front ends today, and the ones most embedded developers will gravitate toward first. You write ordinary C/C++, compile it, and effcc handles mapping it onto the Fabric.
- Rust: Supported as a front-end for developers who want stronger safety guarantees and modern language features, especially attractive in safety-critical and systems code.
- TensorFlow: Allows machine-learning workloads defined in TensorFlow to be compiled and executed directly on the Fabric, rather than being offloaded to a fixed-function accelerator.
- PyTorch: Widely used for ML development and experimentation. Models can be compiled through effcc and run alongside non-ML code on the Electron E1.
- ONNX: Serves as a neutral interchange format, making it easier to bring in models trained in different frameworks (including quantized models such as INT8/Q8).
The important point here isn’t just that these front ends exist; it’s why they exist. The lads and lasses at Efficient Computer aren’t asking developers to rewrite everything in a new proprietary language. Instead, they let engineers start from the ecosystems they already use, then rely on effcc to perform the hard work of mapping those programs onto a spatial dataflow architecture.
But I fear we are in danger of wandering off into the weeds. Returning to the Fabric, a tile isn’t limited to executing just one primitive operation at a time, because effcc can fuse multiple operations together—such as unpacking data, performing a multiply-accumulate (MAC), and repacking the result—into a single composite operation on one tile, allowing complex instruction sequences to execute in a single cycle with extremely high efficiency.
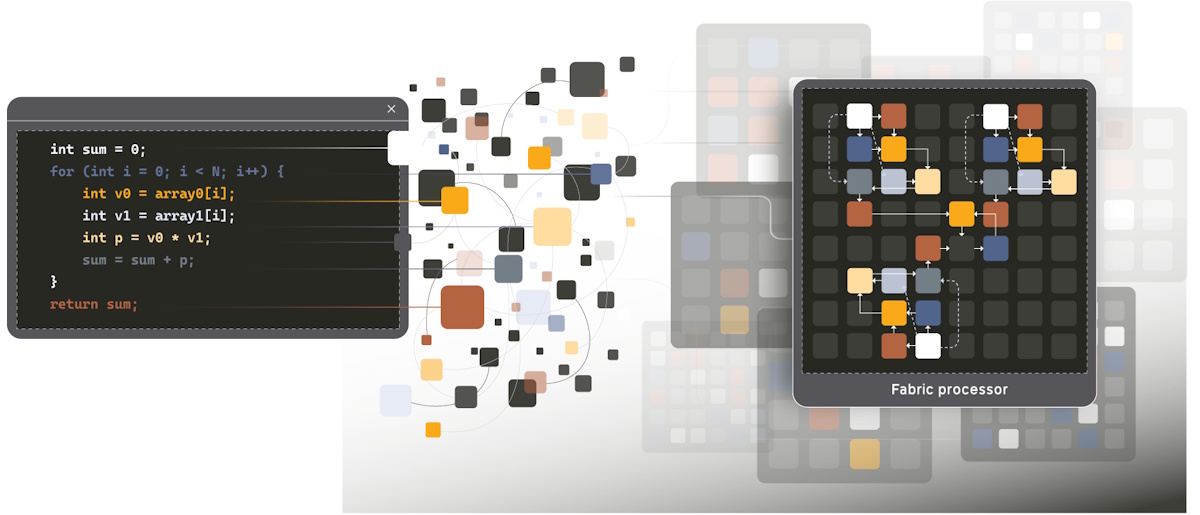
Mapping front-ends to Fabric (Source: Efficient Computer)
It’s also important to note that this is not about reconfiguring the entire chip on every clock cycle (I’ve been there, done that, bought the T-Shirt, attended the play, and got the tattoo). The compiler maps chunks of the program onto the Fabric and keeps those configurations in place as long as possible. When a new phase of the program is needed, the next configuration can be streamed in incrementally—bit by bit (not literally, but you know what I mean)—while the current one finishes its work, effectively pipelining reconfiguration behind execution.
The Electron E1 itself is a full System-on-Chip (SoC). Alongside the Fabric, it integrates on-chip SRAM, non-volatile MRAM (notably radiation-tolerant), and a rich set of I/O interfaces. Code and metadata live in MRAM; execution happens on the Fabric; data flows efficiently without the traditional fetch–decode–execute tax. No external memory is required.
The payoff is substantial. Efficient Computer reports one to two orders of magnitude improvement in energy efficiency compared to conventional general-purpose processors while remaining fully general-purpose. DSP? Control? Optimization? AI and ML? Everything runs on the same architecture, with no architectural cliff where performance suddenly falls off.
Even more intriguing: this approach isn’t limited to tiny edge devices. In principle, the Fabric can scale from deeply embedded systems to data-center-class computing, but that’s something for the future. Returning to the here and now…
All this architectural cleverness would be academically interesting but commercially irrelevant if it couldn’t be placed into developers’ hands. That’s why the folks at Efficient Computer recently unveiled their Electron E1 Evaluation Kit (EVK)—which they just demoed live at CES 2026—marking the transition from “interesting new architecture” to something engineers can actually sit down and use.

The Electron E1 Evaluation Kit (Source: Efficient Computer)
At its core, the EVK is refreshingly straightforward. The Electron E1 SoC (the device sitting in the middle of the board) really is the whole show: processing, on-chip SRAM, non-volatile MRAM, and I/O are all integrated. The evaluation board exists primarily to make our lives easy (I like that), breaking out interfaces, enabling accurate power measurements, and providing extensibility. Plug it in over USB-C, load your compiled program, and you’re running directly on the Fabric.
“This all sounds extremely interesting, but what about security?” I hear you cry. That’s the same question I posed to Brandon, who responded as follows
Efficient Computer enables hardware-rooted secure boot by cryptographically binding each program binary to a customer-owned identity, with authenticity established through digital signatures and enforced by the Electron E1 using a public-key hash permanently burned into on-chip OTP. The effcc Compiler SDK compiles source code into a final executable, hashes the binary, and packages it with a customer-generated signature and public key in a secure metadata header stored alongside the program in MRAM. At boot, the Electron E1 loads the metadata and program from MRAM, validates the public key by comparing its hash to the OTP value, and verifies the program signature against a hash of the full payload. Only when all checks succeed does the Electron E1 allow execution, ensuring that only authorized and untampered software can run.
Well, that certainly answers any questions I had on the security front. Returning to the EVK… what makes this particular offering particularly compelling is that it exposes the entire programming model, not just a carefully curated accelerator demo. Developers can bring real applications in the form of messy, heterogeneous workloads that mix DSP pipelines, control logic, optimization loops, and AI/ML inference, and see how they map onto the Fabric using Efficient’s compiler and tooling. This includes familiar workflows, like C and C++, standard debugging via GDB, stepwise execution, breakpoints, and visibility into program behavior, even though execution is spatially distributed across dozens of tiles.
In other words, this isn’t an “AI-only” sandbox. It’s a way to evaluate whether a fundamentally different general-purpose architecture can replace the CPU-plus-accelerator juggling act that so many embedded and edge systems rely on today.
With the general availability of Electron E1 targeted for 2026 (that’s as tight as I can tie things down at the moment), the introduction of the EVK marks the moment when a decade of architectural frustration, intense research, and painstaking iteration finally transitions into tangibility.
The chaps and chapesses at Efficient Computer didn’t simply set out to build a faster accelerator or a cleverer co-processor. Instead, they were determined to remove the hidden energy taxes baked into how we’ve been computing for generations. The Electron E1 Evaluation Kit is the first real opportunity for the rest of us to explore what computing looks like when those taxes are stripped away. I don’t know about you, but I, for one, am tired of paying taxes!


The Efficient guys are trying to do two things at once: in-memory computing and heterogeneous computing. The in/near-memory stuff is also being done by SpiNNcloud with SpiNNaker2 and others, and there are a number folks doing specialized processors (and you can use FPGAs).
Should you feel like joining them, you might want to check out –
https://www.youtube.com/watch?v=Bh5axlxIUvM (no code changes in-memory computing)
https://patents.google.com/patent/US9923840B2/en (how to implement it)
https://patents.google.com/patent/US10999214B2/en (the security piece)
https://patents.google.com/patent/US12206442B2/en (faster thread moves)
https://cameron-eda.com/2020/05/25/amdahls-law-revisited/
https://chipletsummit.com/proceeding_files/a0qVV000000Jrmz/20250122_A-103_Cameron.PDF
Unfortunately Efficient have refused to engage with me about how deploy this kind of stuff, although that’s what we have been discussing at OCP for years.
https://www.opencompute.org/documents/ai-polymorphic-architecture-specification-v1-0-1-pdf
Hi Kev — thanks for your comment — I’ll reach out to the folks at Efficient to see if they’ll respond.