


Seems that news of the improved performance of EDA tools comes in waves. We covered some Mentor stories recently; this time it’s Cadence’s turn. And there are three things to talk about – all related to verification.
Speeding Simulation
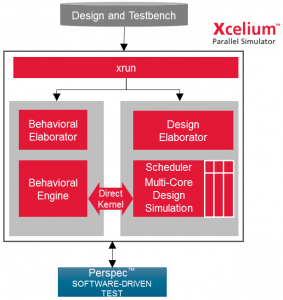
Let’s start with the venerable art of simulation. Cadence points out that, many years back, simulation involved live execution of scripts – which took too long. So the era of compiled simulation began, and, well, that’s pretty much where we’ve been for a while. Cadence’s Incisive simulator is part of that generation.
What strategies might be available for speeding things up yet further? Kevin Morris pointed out last week that the ultimate solution – hardware acceleration – is unlikely. Design logic, as implemented in prototype boards and emulators, might be accelerated in hardware, but EDA algorithms aren’t likely to go that route.
Hardware provides the ultimate parallelization of operations; if that’s not available, then the midway point between what we have now and what we won’t have would be software parallelization.
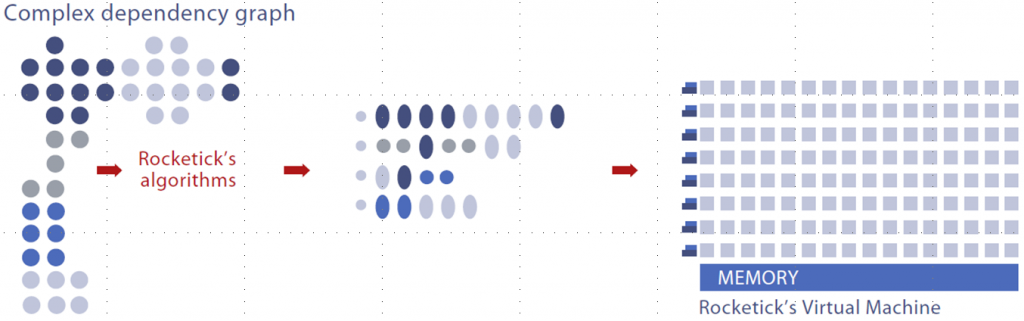
Simulation has long been thought difficult to parallelize. After all, it’s event-based. And events beget events beget events. Which means a huge, long tree of dependencies, traceable all the way to the first event. With logic, we think in terms of “cones of influence”; there’s also a “cone of effect.” Yeah, they’re just extended versions of the notions of fan-in and fan-out. Well, such cones exist with events as well, with each event having predecessors and successors whose number grows the farther you get from the event.
Of course, that doesn’t mean that there’s only one such cone, with an entire simulation ultimately commencing with a single ur-event (although it’s possible). The event cone of influence provides for multiple branches leading to an event, and each of those branches represents a chain of event dependencies. But, apparently, digging through simulation algorithms and figuring out how to identify and resolve all those dependencies has historically been written off as unlikely to succeed.
That’s where RockeTick came along – acquired by Cadence. They were able to organize dependencies in a way that supports significant multicore simulation.
(Image courtesy Cadence)
The result is something of a three-pronged acceleration effort. The first prong is the existing Incisive simulator; the second involves optimizations to that code that have, on average, resulted in a doubling of performance. The third element, then, is the RockeTick technology, which takes that performance and further enhances it over multiple cores.

(Image courtesy Cadence)
Note that this isn’t distributed computing, where multiple boxes share the load; it’s all within a single box. There would otherwise be too much data communication between boxes. The performance numbers they’re reporting involve 6 – 18 cores within the same unit.
(Image courtesy Cadence)
And those parallelization numbers boast a further 3 – 10x performance speed-up. That’s on top of the 2x achieved through optimization.
As a result, they’ve completely rebranded their flagship simulation product as Xcelium.
Speeding Prototyping
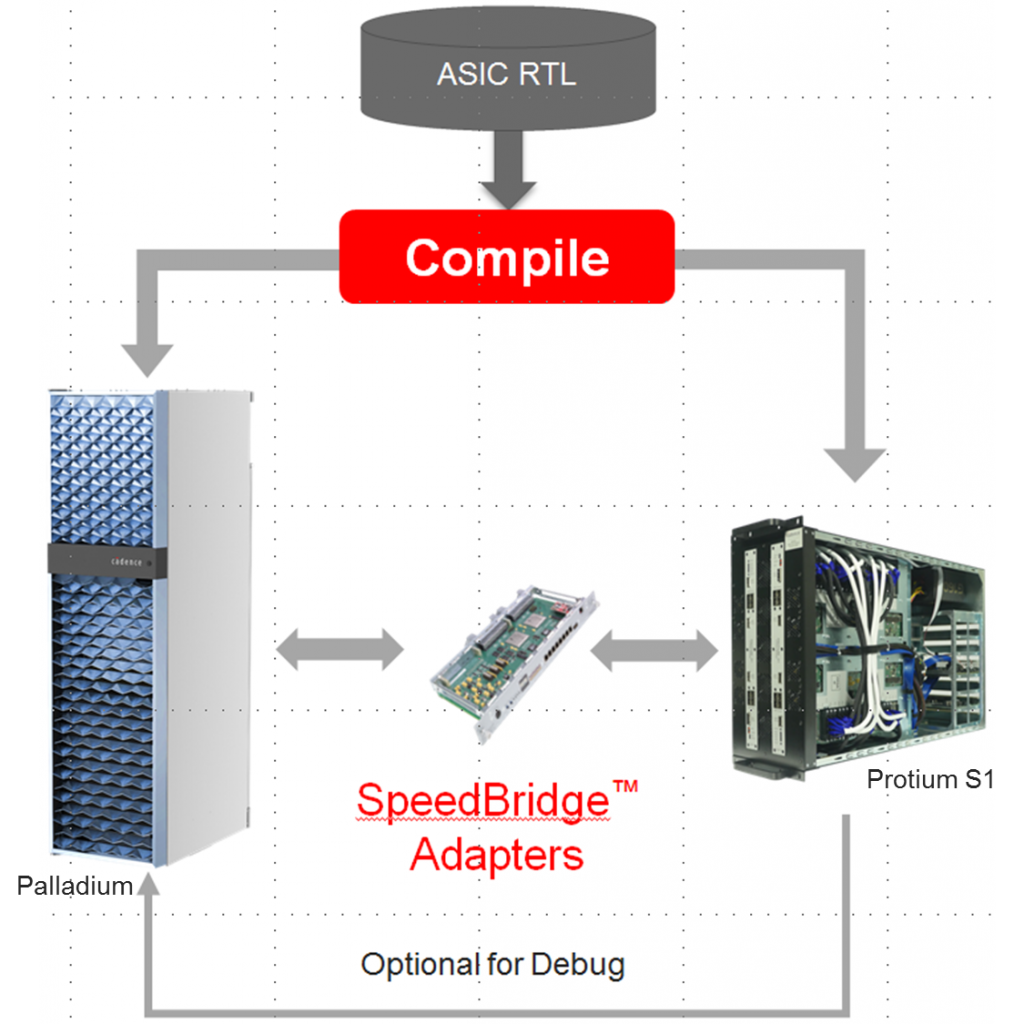
Meanwhile, on the prototyping side of the verification world, Cadence has released a new version of their FPGA-based system, Protium S1.
And really, at the end of the day, this seems like a performance release. Their messaging includes lots of ways they say that Protium and Palladium (their emulation system) work together – in particular, sharing a single compilation flow.
(Image courtesy Cadence, modified to label systems)
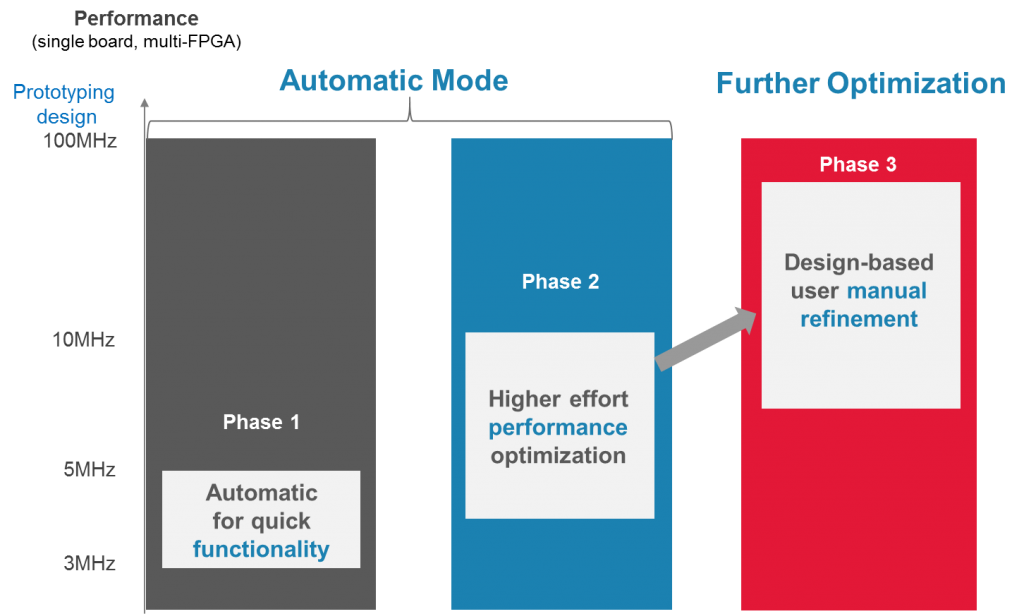
But much of that applies to the existing offerings – with a variety of improvements yielding higher performance. They say that an initial Protium S1 compile can get you from 3- to 10-MHz performance with no manual intervention. If you roll up your sleeves and apply some muscle, you can get up to 100 MHz. In addition, capacity has been increased to 600 million gates.
They identify three stages of bring-up. The first two are automatic; the last involves manual optimization. The difference between the first two is how long you want compilation to run. Phase 1 gives a quick turn to confirm whether basic functionality is correct. Once you’re comfortable that there aren’t major gotchas, then you can dial up the “try harder” knob for higher performance – again, hands-off. Both of these phases are more or less for verifying the hardware.
(Image courtesy Cadence)
Once that’s done, you can spend the effort to get better performance for use in executing software. Yeah, it’s functionally correct after Phase 2, but if you can give the software guys something that can run their code up to 10 times faster, they’ll like you a whole lot more, since they’ll be more productive.
Speeding DRC
Finally, we turn our attention to a very different kind of verification: making sure your physical design implementation hasn’t violated any of the bazillions of rules placed upon aggressive-node layouts. And the story here is, once again, one of parallelization – but for a different problem with very different constraints. It’s the story of Pegasus.
Unlike simulation, DRC checking involves an extraordinary number of “simple” operations: “Here’s a geometry, and here’s a rule to check. (And here are any dependencies that might apply.) And… go!”
Done on a single machine, it would take a long time to check out a full chip. Since last-minute changes (ECOs) mean completely re-running DRC verification so that you can demonstrate a clean bill of health when you tape out, a run that takes forever can threaten the deadline.
And this assumes a normal beefy EDA-ready monster server. Imagine trying to do something like this on cloud-based systems, which don’t have nearly the same muscle.
So Cadence has abstracted this notion of “tasks” in a way that lets them dispatch the tasks – with those three elements (geometry, rule, dependencies) – to a “machine.”
- That machine could further leverage threads, meaning that it could accept and execute multiple tasks at the same time.
- It could be any machine on a network that’s been identified as part of the run set. That network can be heterogeneous, meaning that it doesn’t have to consist of identical (or even similar) machines.
- That network could be an internal farm, a private cloud (meaning dedicated boxes, not multi-tenanted), or a public/third-party cloud.
Yeah, there’s that cloud thing. As we’ve seen before, everyone’s nervous about family jewels in the cloud. In this case, the scheduler would remain with the user. It’s the only part of the system that will see the entire design. In fact, they say that simply sending the entire physical design into the cloud would take a ridiculously long time, and that’s without even starting computation.
So all servers conscripted into the effort see only the specific tasks they’ve been assigned. And everything stays only in active memory – there’s no disk storage used – further improving security. If you were trying to snoop the design somehow, you’d have to capture all of the billions of tasks and somehow reassemble them in order to derive any value from that effort. Oh, and did I mention that they use a binary format for those tasks?
One of the implications of this arrangement drives how the scheduler assigns tasks. It’s not uncommon in structures like this to provide some buffer space – a FIFO or queue – in the compute servers; the scheduler can then load up each one with a few tasks so that the servers can keep working without ever coming up for air.
First off, such queues often use disk space, and that’s eschewed here.
But, even from a performance standpoint, yeah, the server now has to ping back and say, “OK, ready for another one” and wait until new marching orders arrive, which might seem inefficient. But, on the other hand, it occurs to me that pre-assigning tasks based on how full a queue is may not give the best performance due to what I’ll call the “immigration line effect.”
Any of you that travel internationally will know what I’m talking about. You are disgorged from your plane, and, like a giant human baitball, you go streaming to the immigration check, which, in many airports, has several booths, each with its own line. So as you approach, you have to choose: which line will I join?
If you’re like me, you probably join the shortest line – literally, the queue that is least full. Shortly after committing, you realize that there’s a reason this line is shortest: there’s some issue with the person at the head of the queue. A language problem, a papers problem, something – and it’s holding everyone up. And most everyone else noticed this and avoided that line, but, oh no, not clever you! And you stand motionless as all of the losers in the long lines speed past you.
The point being: if tasks aren’t all equal in terms of how much effort they require, then just because a queue is less full doesn’t mean that it has less cycles of computation stored up.
So, both for the sake of avoiding disk storage and possibly for performance, it makes more sense for the scheduler to assign a task only to a server that is available now to work on that task, not to a server that will, at some indeterminate time in the future, be available to work on that task.
Of course, one of the risks inherent in the use of janky-by-design cloud servers is machine failure – which means that a job in process would need to move to another machine. In this one exception to the no-hard-disk rule, they encrypt that content.
Other than that, they avoid using disk storage by applying a stream-processing model. Compute machines can advertise to the scheduler whether or not they’re available to handle another task, and the scheduler will send tasks only to available machines. There is no queue or buffer in the compute servers; there’s only the task being actively worked.
The impact of all of this is that they’ve improved full-chip DRC performance by as much as 10x, making full runs executable in hours instead of days. They’ve also demonstrated scalability to 960 CPUs (bearing in mind that one “server” may have multiple CPUs).
More info:



What do you think of Cadence’s verification updates?