


Years ago, my brother was visiting relatives in Austria. As the story goes, the family was aristocratic once upon a time, and, while that didn’t devolve into riches and status (or even awareness of that fact) for my family, it was still part of the relatives’ mindset. Which gave them a sense of entitlement and “natural” superiority.
So when my brother was describing the California climate, within which he had lived for most of his life, and where you go from, oh, say, April through October without rain – a climate distinctly different from central Europe, he got a simple response: “Not possible.” And that was that. No amount of data or convincing would get them to believe such nonsense.
ProPlus may have a similar sense of frustration with respect to their NanoSpice Giga tool. They claim that it provides full SPICE accuracy at speeds rivaling and beating Fast SPICE tools. Of course, that’s ridiculous, right? I mean, they don’t call it “Fast” SPICE for nothing. And so, according to ProPlus, there’s been a tendency by the press and others to dismiss this claim outright. “Not possible.”
I’m not here to bear witness to the accuracy of the claim, since I haven’t run it myself, but it is a story worth hearing; you can decide for yourself if it sounds possible. And ProPlus has now provided data that, until now, they had kept confidential as a requirement of their customers. But before we jump to that, let’s review why their claim may appear outrageous – and why they say it isn’t.
Seeds and Stems*
Let’s face it: full-on SPICE is compute-intensive. It’s chock-full of matrix math, and using a full solver takes time. And what’s the time-honored way of speeding up algorithms? Parallelization, of course. But, apparently, that wasn’t easy to do. Some time back, ProPlus did a parallel SPICE implementation against predictions that it wasn’t doable. Their approach involved a way of splitting up the matrices (they referred me to “domain decomposition,” which, at a quick glance, seems related to the notion of resolving boundary interactions between “shards” in big-data computing approaches).
That said, in a separate DAC conversation, Silvaco claimed to have been doing parallel SPICE for years, so this may not be a ProPlus-only thing. But, then again, parallelization isn’t what sets NanoSpice Giga apart; it’s part of the story, but an older part that pre-dates the NanoSpice Giga tool, which was released last year.
By improving the matrix math they used in ways they’re not disclosing (in addition to parallelization), they claim to have left Fast SPICE in the dust. How can that be?
Fast SPICE gets its name and speed from the fact that it doesn’t use a full matrix solver. There are two characteristics that speed it up. First (and probably most obviously), it uses table lookups instead of solving directly. Clearly, looking up a value in a table is faster than doing some fancy calculation.
Of course, SPICE works in the world of real numbers, which form a continuous domain. Tables can’t do that – you have to pick a finite number of points to put in the table, and, if you want to look up a value that’s not in the table, you have to go to the closest entry or try to interpolate. Which makes Fast SPICE less accurate than full SPICE.
But when you’re trying to get your design done, having that faster turn-around helps you to move forward, with full-chip analysis providing sign-off-level accuracy (with hopefully not too many glitches to repair) before you commit to masks. Traditionally, that last bit can take a long time, so you don’t want to have to do it too often.
The second characteristic of Fast SPICE is that the algorithm is “event-driven,” according to ProPlus. While this has presumably contributed to calculation speed in the past, ProPlus says that it isn’t scaling well: “Event-driven SPICE is hitting the wall.”
So perhaps part of the story here is about SPICE getting faster while Fast SPICE hits an asymptote. Notably, the new matrix math that ProPlus says speeds up their solver doesn’t apply to Fast SPICE.
Anechoic Chamber
All of this sounds, on its face, perfectly reasonable. If this were any other tool, you’d expect the usual marketing claims and counterclaims to be aired, with folks weighing in using actual numbers. If the tool provider is lucky, the marketing messages will bounce around in an echo chamber, heard and re-heard until they stick. But, in this case, it would seem that there’s been no echo. (Or very little.) Why would that be?
First, history has a role. ProPlus says that, once upon a time, a bevy of new startups promised the moon with new SPICE improvements that they were never able to deliver. BSD was the only survivor of this wave of claims and failure. So the well has been poisoned. “Yeah, we’ve heard that before. Thanks but no thanks.” Or, more succinctly, “Not possible.”
I’ve personally tried to market in a poisoned well before, and it’s really difficult to get people to pay attention. They just assume that you’re every bit as doomed to failure as the last guys. This can be really hard to overcome – although it can be done through patience and dogged determination. Your situation can be dramatically improved if you have data that proves your case.
And that’s the other problem: the data that ProPlus had was considered proprietary to the customers they worked with. Even when we talked at DAC, they said that they couldn’t provide any benchmark data.
I have to confess that, having worked in the tools world years ago, my immediate instinct was, “Don’t you have independent data of your own that you can publish without compromising a customer?” But those thoughts stem from simpler times, when applications departments could simply gin up a circuit. These days, we’re talking full-chip analysis, and these are no small chips, approaching a half-billion elements in the circuits they disclosed.
So it’s no big surprise that any tool company would turn to its customers, who are building chips for a living, for confirming data, rather than trying to do their own full chip. And folks making chips are notoriously cautious about others getting an advance sniff of what’s going on. So they lock everything down.
That said, it still makes it really hard to prove your story if you can’t share data. Well, apparently ProPlus went back to renegotiate (or something), and they came back with some data. I don’t know how they resolved the issue; I just know that I got an email with actual data in it. Huzzah! The data came in the form of graphs, and I’m not at liberty to share the graphs, but I can share the data from them.
Here are three different views of their performance gains versus Fast SPICE. (None of the comparisons is versus another full SPICE tool.) All are for memory chips.
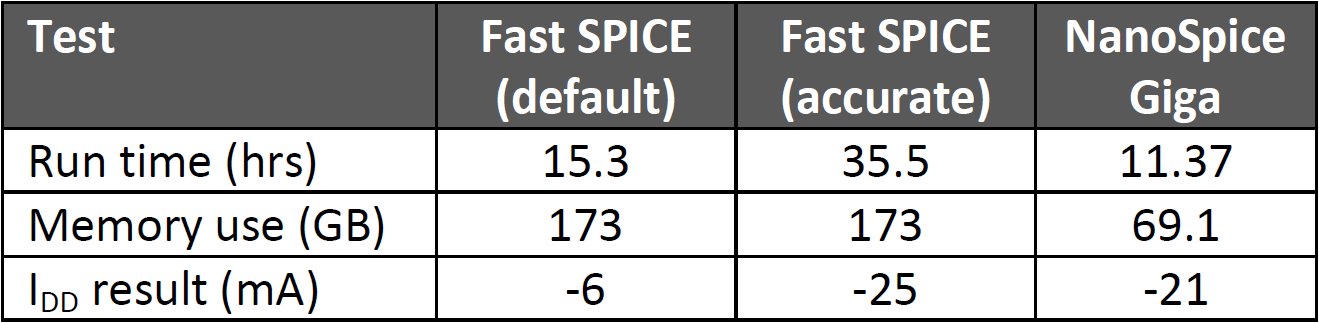
- An SRAM chip with 495 million elements, analyzing IDD during a write cycle. They compared NanoSpice Giga against Fast SPICE, in both default mode and accurate mode. NanoSpice Giga run time was less than even default-mode Fast SPICE, and memory consumption was cut by more than half. The resulting calculated current was around 16% different from the “accurate” Fast SPICE result.
- A series of DRAM circuits, ranging in size from 3.8 million to 115 million elements. NanoSpice Giga achieved DC convergence for all of them; Fast SPICE got convergence for none of them. Claimed run times are 2 – 10 times faster (although the graph makes it look more like 2 – 9).
- Ten NAND flash circuits, all with roughly 3.9 million elements. NanoSpice Giga is anywhere from 3 – 5 times faster, with accurate calculation of charge pumps.
So there you have it. The story, plus some data. Assuming this data wasn’t totally rigged (which would be silly, since they’d be found out pretty quickly), at least we can move past the “not possible” response. It’s certainly not the end of the discussion, but at least a discussion is possible.
*Obscure reference: herbs are leaves, spices are seeds and stems (and other parts of plants). Why, what did that phrase make you think of?
More info:



What do you think about ProPlus’s full-SPICE speed claims?