

The scope display clearly showed 58.0 Gbps. I was curious. I was expecting a 56 gig demo – you know, the next official step in the traditional “doubling of the data rate” that we get with each process node in FPGA transceivers. The last node sported 28Gbps SerDes transceivers, so, clearly, this time we should be dealing with 56. I started to ask about the discrepancy, but somehow I knew the answer already:
“Yeah, but this one goes to 58!”
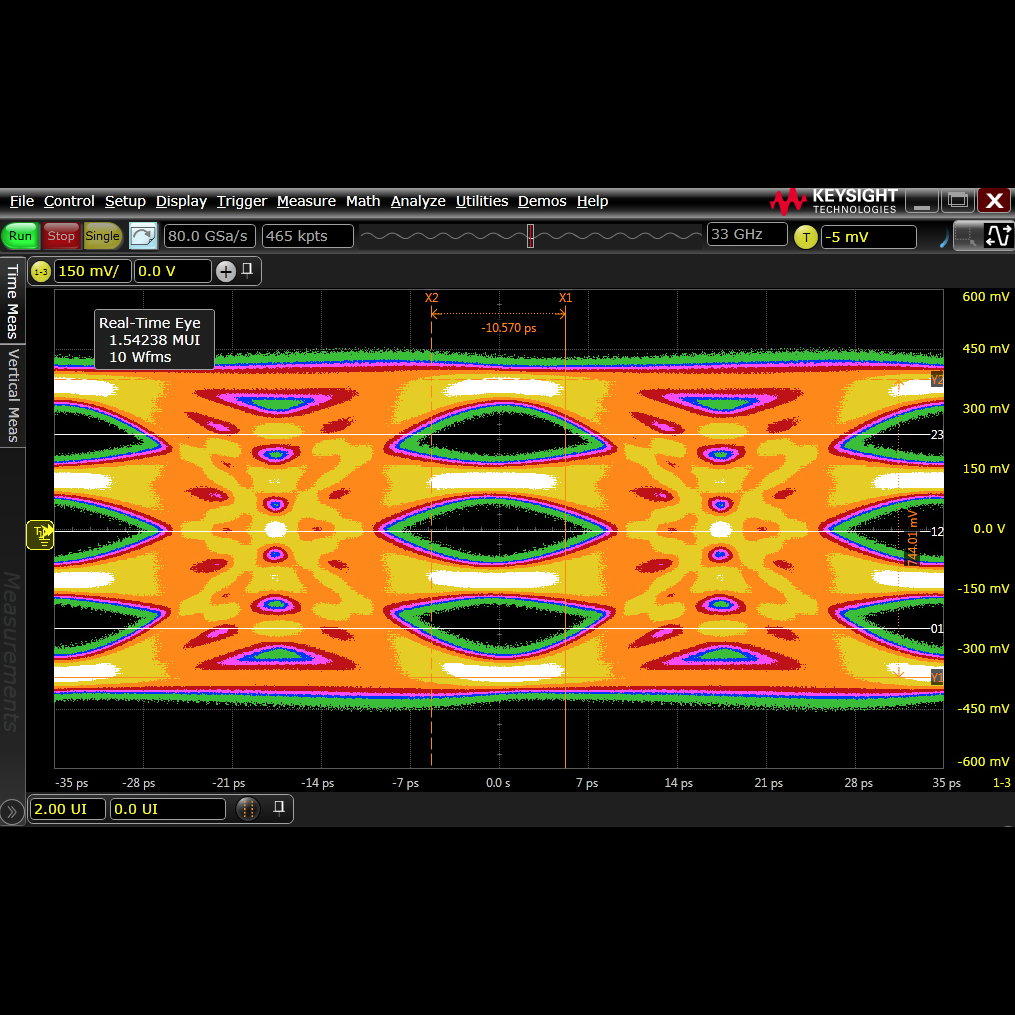
I was distracted, though, by another issue. There was a serious problem with the eye diagram. I was expecting to see a nice, round hole in the middle of the eye, devoid of trace data over billions of cycles, indicating that we most certainly, definitely, for sure could always tell the difference between a zero and a one as each bit came blazing down the pipe. But, this time, I did not see that familiar eye. Instead, I saw three of them, stacked vertically. Three big, distinct holes in the trace data, delineating four distinct values.
Bye Bye Binary
Traditionally, multi-gigabit SerDes is encoded with NRZ (non-return-to-zero) encoding, which is a fancy way of saying “binary with no in-between ‘rest’ voltage.” We fire those zeroes and ones out of the “trans” part of the transceiver just as fast as the “ceiver” part on the other end of the line can manage to distinguish between the two.
At 28Gbps, the industry did a really good job, managing (as the name implies) 28 billion of the suckers per second with a nice hole in the eye diagram proving that we could tell the difference. The problem is, when we try to double that frequency and do things the same way, the wheels come off pretty spectacularly. Signal integrity issues that could be mitigated at 28Gbps become a lot less mitigatable when you double the clock rate. Our same old boards, connectors, and backplanes pretty much stop working altogether. We end up needing a lot of new stuff.
So, what if, instead of doubling the clock frequency, we send twice as much data each cycle? No, not by using 2 lanes of 28 gig – that’s cheating, and that would still be officially 28 gig. What if, instead, we sent two bits of information on each cycle rather than one? Enter PAM-4 encoding. PAM-4 (Pulse Amplitude Modulation) has four discrete voltages that represent the four possible values. The eye diagram, therefore, has three distinct eyes separating those four values. This allows us to keep the baud rate the same, but send twice as much data through the pipe.
Diving into the rationale a bit – as we increase the baud rate, naturally the horizontal dimension of our eye gets smaller. The eye starts to close as the ratio of the interval to the jitter gets lower. By operating at half the frequency, the total vertical opening is larger. So, if you have the dynamic range to do PAM-4 well, it’s a win compared with doubling the frequency with NRZ.
It is estimated that, somewhere around 35Gbps, there is a crossover point where PAM-4 outperforms NRZ. Since we are now jumping from 28 Gpbs to 56 Gbps, we have reached that juncture. Now, channel loss drives the need for the switch from NRZ to PAM-4.
In our recent demo in the super-secret labs at Xilinx (OK, the labs aren’t really all that super-secret, but bear with us here), we got a hands-almost-on demo of Xilinx’s new 56 Gbps transceivers (the ones they will be using to supersede the 32.75 Gbps GTY transceivers that are their current speed champs) operating at the one-upper speed of 58 Gbps. Why 58 instead of 56? Well, what happens if you’re running at 56 gig and you need just a little bit more? Or maybe just because they tried it and it worked – and so, when you’re giving a demo, why not? Or maybe they already knew that Altera was planning 56 Gbps…
Our demo included the transceivers pushing a clean 58 Gbps through a connection channel that introduced 40dB loss. That’s impressive, and it’s a big deal for people plugging line cards into backplanes. It means you may get to keep the same backplanes, and double your speeds, by simply plugging in new line cards. Or, if you happen to want to go 58 Gbps, even more than double your current speeds. Of course, there are still implications with crosstalk and so forth that you’ll have to consider, and it’s not realistic to think that all 28-gig backplanes will be plug-in upgradeable to 56 gig. Your mileage may vary.
The demo we saw did not yet include the transceivers on a working FPGA. We were watching a test chip with the same transceivers that are planned for the next generation. Still, seeing clean eyes and essentially zero-bit error rates at these data rates is impressive.
The basic strategies for achieving success with PAM-4 at these rates are similar to what we’ve seen before: transmitter pre-emphasis and receiver equalization. For 56 Gbps PAM-4, though, it’s the receiver that has the heaviest burden to carry. The 9dB or so of vertical space you lose by switching from NRZ to PAM-4 is hard to recover, and the raw data before equalization over most channels is sobering, to say the least. Nothing that really resembles an “eye” can be seen. But the DSP in the automatic equalization strategies of the Xilinx receivers is remarkable, and the recovered signal is clean as a whistle.
If you’re planning to implement the probably-upcoming really, really fast Ethernet standards like 100G, 400G, or even (gasp) Terabit Ethernet, and you don’t plan to replace every single component in your system, these transceivers may be able to help. Once they’re actually available to the public, that is.
A few years ago, Xilinx made a clear change in their transceiver strategy, relying much more heavily on digital implementation of the signal correction circuitry. Now, we are seeing a clear payoff from that strategy as the company is hitting their goals with considerably better agility than in generations past. Next, we’ll be excited to see these new fast-talking marvels in some upcoming ready-to-sell FPGAs.



10 thoughts on “This One Goes to 58!”