


The Holy Grail for the Internet of Things (IoT) is that any machine can talk to any other relevant machine and, notwithstanding possible different transports and operating systems and underlying hardware, they’d be able to understand each other at the higher semantic level.
Today we’re going to talk about one approach that’s slowly being unveiled for consideration by various standards bodies. The question is, is this a grail or just a grail-shaped beacon?
This activity boils down to getting agreement between machines on what things are, what their attributes are, and how they are all represented. From a practical standpoint, we’re specifying the contents of the payload of whatever transport protocol we’re using. Bear in mind, it’s not just the structure of the payload: it’s the way actual notions are represented at the machine level. It’s critical that this be independent of the specific transport used; it should work with something simple like MQTT or something RESTful like CoAP or something complex like AMQP or DDS.
But this means that machines have to understand All Things, which means that someone has to define an Ontology of Everything. There are actually projects already underway to do this sort of thing (Google “ontology of everything” and see all the stuff that comes up).
Today’s focus is on a new initiative by a company called ControlBEAM, largely embodied in the guy behind its ideas, one Doug Migliori. And part of what’s required for their BEAM protocol is, perhaps not a complete ontology to get it off the ground, but a methodology for building and extending an ontology that could, in the end, encompass “everything.”
As if defining everything weren’t hard enough, they’re proposing a top-down hierarchical ontology, which means not only things and their attributes, but also their relationships to other things that may be “parent’ or “child” entities of the things.
Of course, natural language initially looms as an obvious barrier to this. It can’t be an English-centric thing. Heck, even if it were, you’d still run into issues. An obvious example to me is the fact that, if you have a Thing defined for a city street, then you would have a child thing called “pavement.” But in the US, the pavement is the covering on the bed of the road (asphalt or whatever); in the UK, “pavement” means what we in the US call a “sidewalk.” In other words, never tell your kids to go play on the pavement unless you know which version of English they speak.
So an English-centric version, in addition to annoying (at least) speakers of other languages, would fail interop because not even English-speaking humans can interoperate unambiguously using English. Instead, each thing to be included in the ontology needs to be reduced to a machine number – a GUID (or UUID), or globally (universally) unique identifier.
The methodology for building an ordered, universally agreed ontology comes with two parts. The first part is the hardest, frankly: it’s establishing so-called “entities” for everything. If you think in object-oriented terms, an entity is like a class: it doesn’t describe how any specific thing works, but it does build a template for how all things of that class should behave.
Each entity gets a GUID. And entities don’t cover just the obvious things like “washing machine” or “grommet.” They also include infrastructural concepts like “memberships,” which establish the roles of people (which form another entity) and “domains” (both generally and literally: “com” would be one domain, with its own GUID, as would a university).
Within this definition, each entity has attributes – and, you guessed it, each attribute gets a GUID. But this is all abstract. It’s like defining the schema of a relational database (RDB). It’s necessary for building the data store, but it has no actual data in it.
That’s the second part of defining the ontology: each instance of an entity, which they call an “object,” also gets a GUID. And the values of attributes associated with that object get GUIDs. In effect, you might think of a table listing the objects associated with an entity. Each column head (for attributes) has a GUID; each row head (for each instance) has a GUID, and the entries all are GUIDs as well.
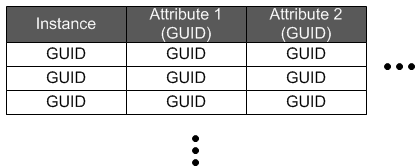
This becomes very much like populating an RDB schema with actual data. Further with the RDB analogy, and, in keeping with the hierarchy, each entity would likely have a “parent” field so that you could establish 1:1 and 1:? relationships. (?:? relationships would have to be built separately by analytics tools.)
I’m not quite sure if this allows the same level of relationship building as can be done with an RDB, but it’s at least partway there. To be clear, however, this system doesn’t depend on any particular type of data store – RDB or other. It’s layered above, abstracting away both the method of store and the organization of that storage. (Meaning that rules have to be established for mapping a data store to the ontology.)
Defining All the GUIDs
Here’s the challenge, however: who’s going to define this stuff? The plan is twofold. Let’s start with the easier one: actual objects, assuming the entities are in place. Anyone can define these as they crop up. (“Anyone” actually meaning “any computer.”) If you’re starting a message about a specific object, then your computer will create a GUID for that instance and for any attributes you specify. If someone else further adds attribute values to the object, then their machine will create those GUIDs. Regardless of how far these objects travel, they will keep the GUIDs assigned at their creation.
So populating actual objects is, if you will, crowdsourced. But what about the entities themselves? Can you imagine if those were crowdsourced? Everyone would have their own definition, and you’d have to have some way of looking to see if one were already defined, and then, even if it were, if someone didn’t like the existing definition, they might define a different variant. Hello chaos!
Well, that’s not what’s proposed. This needs to be done in a coordinated fashion, not by the hoi polloi. The idea here is to have registrars – currently proposed to be the top-level domain (TLD) registrars (the folks that already manage top-level internet domains) – manage this. It doesn’t have to be those guys, but they’re already in place, and it would be easier than defining an entire new organization. They haven’t agreed to it yet – it’s still an early proposal – but it answers an obvious question.
The TLD registrars (or, failing that, whatever organization were anointed or created) would build and maintain the entity definitions and publish them in dictionaries. (How the job would be distributed amongst the various TLDs is a detail that would presumably need to be worked out.)
Calling these “dictionaries” brings to mind one other aspect of what needs to be managed: what to call things. A table consisting only of GUIDs might satisfy the minimal needs of a machine, but when it comes time for a human to interpret this stuff, we need something friendlier. But this brings us right back to that language issue. Which words do you use for things? Including, which English words, given regional variants (which all widely-spoken languages have).
So the dictionary will also need to include the terms for things in all languages. No small task. And, given the possibility of doing some machine creation of entities from sub-entities, it would also need some set of rules for how the language works. For example, using an example from Mr. Migliori, you could combine “sales,” “order,” and “item,” each of which would have a defining entity, to get a “sales order item” entity. Problem is, as written, this depends on the way English works.
To make this work for Spanish, for example, you’d need a rule that builds this concept more or less in the reverse order:dede. Having toyed with natural language translation ideas myself in the past, this is intriguing, but it has to be proven that it can be done for all languages. Some languages use particle words or prepositions (like “de” in Spanish) to define relationships; some use affixes; some use cases (and some have many more cases than others). Having discovered myself how differently languages can operate, I don’t see it as given that you can define such rules easily and then represent those rules in a manner that the machine can understand and act upon. But they could prove my cautions to be needless.
When Up and Running
So that describes the general notion; how would it work in practice? The structures would be embodied in a service that, ideally, would be modules in operating systems and browsers. Much of the interaction would be on a peer-to-peer basis. Anything too complex for simple edge nodes to compute might be referred to the Cloud for resolution. Access to specific pieces of data would be provided by subscriptions (which are themselves objects). These subscriptions could be very specific, defining the objects and attributes that would be viewable by a given person.
And this all raises the question, “What’s the business model?” Clearly this wouldn’t all be free; where’s the money, and, in particular, what does ControlBEAM get out of it? The proposal at this stage is that the TLD registrars would pay license fees to ControlBEAM, and developers would pay license fees to the TLD registrars for access to the reference architecture and the metadata dictionary.
It also raises the questions, “What’s the status? Is this a done deal?” It is by no means a done deal. Mr. Migliori has had a number of discussions with different organizations that are working on standards for the IoT. While ZigBee doesn’t appear to be one of them (at least, not yet), I point them out as having perhaps the closest thing to what this covers, in the form of “clusters” (previously, “profiles”). But that’s still very far from what the BEAM protocol proposes.
The IPSO Alliance has been working on what they call Smart Objects. OASIS’s OData group has been considering abstracting payloads in HTTP or REST for compatibility with other transport protocols. Mr. Migliori has had conversations with representatives of these two organizations as well as of the IIC and The Open Group. I contacted all of these individuals seeking comment; representatives from The Open Group declined comment in the interest of remaining vendor-neutral; it was bad timing for the IIC rep, and he declined comment. As of this time, I haven’t received a response from the others.
In general, Mr. Migliori says he’s received what he has felt is positive feedback and encouragement to contribute the ideas to the various groups (the above and the group standardizing DDS). Which means it’s very early days for BEAM.
I did exchange emails with Geoff Revill. You may recall that he was the gentleman with whom I had a discussion regarding interop for the previously published interop article. He was encouraged that this moves in an interesting direction, although he saw issues with scaling and the fact that it originates with a human-centric top-down ontology rather than a machine-centric bottom-up one.
In fact, he’s been involved with another long-standing work, particularly within the military, to establish a thorough, scalable interop methodology, and those efforts are maturing. In the near future, we’ll provide a look at how their approach works. As you might imagine, it’s different from BEAM.
Alternatives notwithstanding, If other groups and individuals have similar “nice, although…” reactions, then it’s likely that, in the process of being worked by the organizations, it will morph. I suppose there’s the risk that there might be a different evolution of the proposal in the different groups. If that happens, some harmonization will be necessary or else it will completely miss the point.
So this becomes another thing we’ll need to keep an eye on in the future. As if we didn’t have enough already…
More info:



What do you think about the BEAM protocol for establishing semantic interop?