


While watching the unending array of Internet of Things (IoT) discussions, it occurred to me that something important was missing from the conversation.
When we talk about the IoT and all the data and all of the messaging protocols required for sharing the data, we’re talking only about one direction of data flow: sensing, and then transmitting the sensor results somewhere else. But a true automated system – whether home or factory or farm – also involves the reverse: making the edge nodes do something. A world of sensors does little good without accompanying actuators unless all you’re trying to do is publish metrics or analytics.
My instinct is to call this reverse channel “control.” As in, sensors observe and actuators control. A natural pairing. In some of my discussions, however, I became aware that “system control” can have a very specific different meaning related to administrative tasks on an embedded system. And I found that attempting to “redefine” control for the purposes of a conversation didn’t always work – we were always at risk of talking about a different kind of control.
So I’ll start by saying that, for the purposes of this article, I mean “control” to refer to the network-level operational act (not device-level maintenance or administrative act) of making some node in the network do something – take action or change a setting. From that standpoint, even a sensor can be subject to control commands if its settings are to be changed.
I’d love to come up with a better word than “control,” but I can’t think of one.
As a couple of examples, let’s say that a thermometer is set to sample the temperature every 10 minutes, but, for some reason, you need finer gradations. So you change the period setting (perhaps temporarily, perhaps not) from 10 minutes to 5 minutes. Or let’s say that a vibration sensor is showing an atypical vibration signature, perhaps indicating that a mechanical failure is imminent. You want to send a command to the machine that causes it to shut down in a graceful manner to avoid damage and injury before the failure occurs.
That’s the intent of “control” for the next few pages.
Natural Communication
Here’s what’s been bugging me about control. With all the focus on distributing sensor data, we’ve been presented with messaging protocols that follow the publish/subscribe (P/S) pattern. Not all of them do, but many do.
And that makes sense for sending data around. While request/respond (R/R) – especially in the RESTful case – makes some sense with respect to possible connection failure, the nice thing about P/S is that the sensor or sender doesn’t really have to worry about who’s listening to the data. Just keep posting it and let the brokers (or whatever is managing the P/S lists) handle subscribers. It has an arms-length, anonymous quality. Which is great when untold numbers of other nodes might be gobbling up the data.
Control, however, feels very different. I mean, imagine a military boot camp where the drill sergeant orders a cadet to do a better job polishing his shoes by writing it on a whiteboard somewhere, and everyone walks by the whiteboard reading it and deciding whether it applies to them. At the very least, it’s inefficient. It’s indirect communication. And if Private Scuffy doesn’t happen to pass by, he won’t get the message at all.
What would seem more effective would be to have direct face-to-face communication, where Sergeant Drillbabydrill gets right up in Scuffy’s grills yelling at 130 decibels that his shoes are a disgrace and that he needs to fix that pronto.
Trying to control a piece of machinery by posting, “By the way, if any of you is node 465B, you need to shut down now cuz you’re about to explode” on a “public” forum seems likewise inefficient. A point-to-point approach (the machine equivalent of face-to-face, I guess) would seem to be better – a message directly from the sender to the target edge node.
Literally trying to manage this in a pure, anonymous P/S system would mean that every edge node would have to have a topic for itself and then subscribe to it. The sender would have to know all of the topic names for all edge nodes so that it could publish a control message with the topic of the intended receiver. Feels messy.
Two patterns suggest themselves more naturally to this: remote procedure call (RPC) and R/R. RPC (“remote method invocation”, or RMI, in Javaland) effectively means executing a function on the target node as if you were in the node itself. R/R is your classic browser-like “Please give me data”/”OK, here’s your data” approach, where the request and the response are two distinct operations (not just a function return value).
One difference between these two patterns is the nature of what happens while awaiting a response. Traditional RPC is like calling a function in a program: it’s blocking. In other words, the calling program will wait until the response comes before moving on to the next line of code. This is also referred to as “synchronous.”
RPC can also be non-blocking, or “asynchronous,” in which case, after the call, host program execution continues in parallel with the execution of the call in the remote node. A notification of completion is sent to a specific variable created for that purpose (assuming acknowledgment of completion is desired – more on that in a bit).
Frankly, asynchronous RPC starts to look a lot like R/R. PrismTech’s Angelo Corsaro also notes that few programmers are really comfortable dealing with concurrency, and so synchronous RPC is more common than asynchronous.
Details aside, what this suggested to me was two coexisting channels: a “sense” or “observe” channel in one direction, implemented as P/S, and a “control” channel in the other direction, implemented as R/R (or RPC/RMI). And I had a few conversations to try out this idea – at the very least to find out what’s done in the real world.
Forcing P/S to Allow Point-2-Point
You may recall from our survey of messaging protocols that one company, Real Time Logic (RTL), actually came up with their own proprietary SMQ protocol – for this specific reason. Their focus is super lightweight, meaning something like DDS wouldn’t fit. MQTT would have been preferred – but, with MQTT, there’s no easy way to address a specific node, because the nodes are all anonymous.
RTL’s solution was to define a protocol that placed an ephemeral device ID in sent messages so that a listener could respond and address the sending node directly. Essentially, there’s a return address in the message. That at least provides a way to get back to a node once you’ve received a message from it, although it’s still P/S.
I asked why there couldn’t be a separate channel for control using an existing R/R protocol (like CoAP). CEO Wilfred Nilsen brought up a couple of issues with that.
The first has to do with the edge node’s firewall: it sees the edge node as a client, and anything outside is a server – and only clients can initiate sessions. That works fine for the sensor sending out data, since, in that case, the edge node is the sender. But an outside node couldn’t easily open a session to send in a control message.
To handle this more effectively, the edge node would need to open both channels – the P/S channel for sending out data and then the R/R channel for receiving commands. But that brings up the second issue: it may well require two separate TCP sessions, which would be inefficient for a tiny device. So their proprietary SMQ protocol seemed to them to be the better solution.
On the other end of the complexity spectrum, DDS also operates using a P/S model. And the kinds of large-scale networks that might deploy DDS are extremely likely to need to distribute commands. How does DDS handle it?
The answer is, by using P/S – disguised as R/R or RMI. Both RTI and PrismTech offer RMI and R/R patterns, but both patterns are wrappers around the underlying P/S foundation. The messy bits I alluded to above? They happen, but they’re hidden from the programmer.
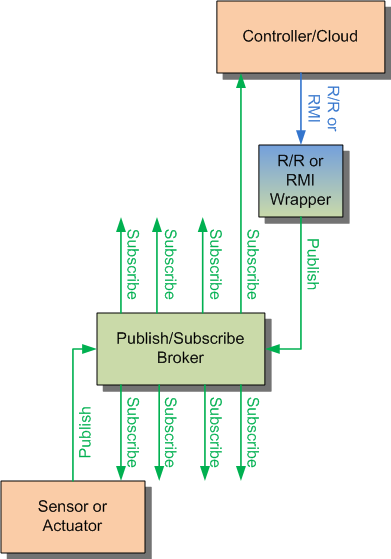
RTI noted some benefits of using P/S. For one thing, you can identify a group of actuators that need to be addressed and target them all at once, using that group as the topic. If a single device in that group (or some random combination of individual devices) is to be the sole recipient (not the entire group), then its device ID can be included as a key; the edge nodes can filter the keys for their ID.
You may notice here that, by some magic, the sender in this case is supposed to know the device IDs of its targets for use as keys – something that wasn’t possible with MQTT (or else SMQ wouldn’t have been necessary). How does that happen? By the magic of discovery, a feature DDS supports. This is mostly a real-time thing; as nodes come and go from the network, notifications arrive, allowing any subscribers to such notifications to manage their own lists.
The practical benefit of this is the use of multicast. Without P/S, instructions to 15 valves to close would require serializing 15 individual point-to-point messages. Using P/S allows multicast to send to those 15 targets with one message.
It also allows other observers on the network to monitor what’s happening. The good version of this enables an airplane-black-box-like capability for system health and forensic use. (The dark version of this makes the data available to unwelcome lurking nodes, but then again, that should never happen because you’ve done security, right?)
DDS also offers durability – meaning that late-arriving nodes can get caught up quickly on what their settings should be and what subscribed data they might have recently missed.
It helps to think of all of this in the data-centric way: edge-node settings are part of the data model – the state of the network. So issuing a command is tantamount to requesting a state change. Any response confirming such change then reflects the new actual state of the system. This allows the requested state and the actual state to coexist as distinct entities during the transition from one stable state to the next stable state.
Did I Get Through to You?
That response thing is yet another nuanced aspect of sending a command. Private Scuffy has a rather simplistic response pattern that consists of three words, “SIR YES SIR!” No matter the command, the acknowledgment is the same. (I’d love to see the Sarge’s face if Scuffy replied, “ACK!” I can hear the retort now: “Who are you, Bill the Cat??”)
But what does it really mean? Given the command, “Seems you need some practice polishing, so here’s a toothbrush and there’s the floor of the latrine. I WANT TO SEE THAT FLOOR SHINE,” the appropriate response doesn’t really do much except assert submissiveness. Does it mean, “I hear you”? Does it mean, “The floor is now clean”? What if the toothbrush breaks? There’s intentionally no wiggle room in “Sir yes sir” that allows something more nuanced, like “Am attempting but a toothbrush malfunction has interrupted progress. Sir.”
Another analogy is the oft-noted difference between acknowledgment in Western and Japanese oral communication. In one case, “Yes” tends to mean, “I agree with your statement”; in the other, “Hai” tends to mean, “I have heard what you said.” Misinterpreting one for the other can lead to awkward moments.
Let’s say that you need to send a command to shut down a complex piece of machinery. In order to shut down gracefully, let’s further assume that the machine must complete a cycle that it’s currently in the middle of, eject the products of that process, and then shut down various pumps and motors in a carefully prescribed order.
When you send that single “shut down” command, a quick acknowledgment doesn’t tell you much – it simply says that the message has been received. That might be a useful bit of information, but it leaves a lot to the imagination. Can I now proceed under the assumption that the machine has shut down? Or, if it takes a longer time to shut down, when is it safe to assume that it’s complete?
RTI’s David Barnett says that they don’t assume: they provide several levels of response (some of which are part of the DDS standard, some of which are proprietary). First is, “Message received.” Next is, “The application has read the data in the message.” This is different from the first one because the first one comes from the communication layer, not the application itself. Just because the messaging protocol got the message doesn’t mean that the application has seen it. The final response is the application saying that it has finished executing the message.
That whole notion of completing a complex assignment, like the machine shutdown, may take a single instruction (“shut-down”) and translate it into multiple local messages instructing the various parts to implement their roles. So there may be multiple back-and-forth messaging locally before the system finally asserts back to the commanding officer, “Mission complete, sir.”
The application may also send back progress reports so that the commanding officer doesn’t have to wait with breath bated until the whole thing is done.
So the upshot of all of this is that P/S does end up getting used for control – disguised as something else. It’s just that not all P/S protocols (ahem… MQTT?) have the features that make possible effective control. On the other hand, DDS is a pretty bulky beast for super tiny machines.
If you can’t afford DDS, then you’re left with a couple of choices. Perhaps fake it with MQTT (overlaying your own device-identifying payload at the application level?); use SMQ (or invent something similar); or use CoAP, which uses an R/R pattern. The latter would come at the expense of liberal data publishing, but it’s all part of the tradeoff game.



How do you handle sending commands in resource-constrained systems?