

While multicore took a while to take root in the embedded world, it’s now relatively commonplace. But the most accessible style of multicore is homogeneous: all cores the same. Combine that with a shared memory configuration, and this becomes easy because you can use a symmetric multiprocessing (SMP) solution out of the box from your favorite OS. It treats the multiple processors as a group as if they were a single processor. It can do so because the processors are all the same and they all have the same view of memory.
But that’s not how all systems work. Increasingly, folks are wrestling with heterogeneous systems, which have different processors, each of which might have its own OS instance running (or perhaps even no OS at all, so-called “bare metal”). While there might be some shared memory, it would typically be for message passing between processors. For the most part, each processor would have its own memory (or portion of memory) privately allocated.
(Just to clear up some potentially confusing terminology here, homo-/heterogeneous refers to the hardware architecture; SMP and its counterpart asynchronous multiprocessing (AMP) refer more to the software architecture, including the OS. SMP has a single OS instance managing the entire bunch of processors, and, as such, requires a homogeneous configuration. But a homogeneous configuration can be run as AMP if some of the processors have their own independent OS instances running. AMP systems can also include SMP components. At least, that’s how I see it…)
AMP/heterogeneous systems are harder to manage because each processor is aware only of itself. For the most part, no OS instance has system-wide scope (unlike SMP). So things that are easy with SMP become hard with AMP.
An easy example is bring-up: who’s in charge to make sure that all processors are synchronized in their operation? Typically, each processor comes up and holds at a so-called “barrier,” but which processor looks around, deems the system stable and ready for launch, and releases the barrier?
Much of that is system design work to assign that “master” processor, but then you need a programmatic way of implementing the decision. And the catch is that, because each processor is out of scope for any other processor, there’s no obvious logical way for one processor to control the others. There’s no “super-process” that has everything in scope.
This is what Mentor Graphics is trying to address with their recent multicore announcement. Now, to be clear, Mentor makes a lot of tools for a lot of things, including both silicon implementation and embedded systems. This announcement was not about how to create a multicore SoC; it was about how to implement software on an existing heterogeneous architecture.
There were three fundamental components to their announcement, addressing several different AMP challenges:
- remoteProc: this is a set of functions that allows one processor to control another. In particular, it allows for a well-coordinated system-wide boot sequence, with one processor controlling the life cycles of others.
- rpmsg: this allows intercommunication between processors (so-called inter-process(or) communication, or IPC). The figure below shows this interacting through the hypervisor, although no hypervisor is required. They’ve also optimized an MCAPI implementation, which can be layered over this.
- Improvements to their CodeSourcery tools to allow visualization of the different processes/processors in a clear and synchronized fashion (a challenge if you just run something like gdb on each core and then try to make sense out of the independent results).
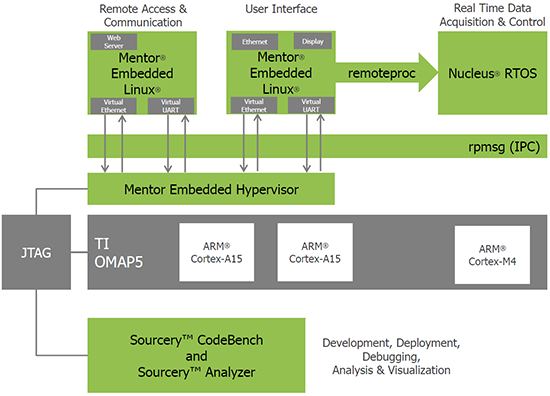
Image courtesy Mentor Graphics
They did a cleanroom implementation of these functions to ensure that they could be used with proprietary software without exposing that proprietary software to GPL license restrictions (which would otherwise require making source code for that proprietary stuff public).
They have it integrated into their tools for ARM processors and available as libraries for bare-metal setups. They don’t have an integrated version for non-ARM processors; the libraries could be used, although they haven’t been validated on anything but ARM. It’s not that they think it won’t work on non-ARM; they just seem to feel that ARM is all that matters, so it’s where they’ve spent their energy. (I’m assuming that if something else blew up huge, they’d invest more energy there…)
You can find out more in their announcement.


