

Multicore systems can be a b…east to verify code on, depending on how you have things constructed. Left to, say, an OS scheduler, code execution on your average computer is not deterministic because of the possibility of interruption by other programs or external interrupts. So it becomes nigh unto impossible to prove behavior for safety-critical systems.
Lesson #1 from this fact is, “Don’t do that.” Critical code for multicore must be carefully designed to guarantee provably deterministic performance. But lesson #2 is, when tools claim to analyze multicore code, you have to ask some questions to figure out exactly what that means.
Which is what I did when LDRA announced new multicore code coverage analysis. This kind of analysis invariably involves instrumentation of source code, which, by definition, exacerbates concerns about determinism. So what does this mean in LDRA’s case?
I got to spend a few minutes with one of their FAEs, Jay Thomas (yes, they were actually trusting enough – of both of us, frankly – to let an FAE talk to press) to get a better understanding of what’s going on.
First of all, the scope of the analysis is coverage – determining whether or not a particular piece of code got executed. This is conceptually done by adding a bit of code to (i.e., instrumenting) each “basic block.”
A basic block is a straight-line set of code statements without any branches. Because there are no branches, then if you enter the block, you know that every line in that block got executed. I suppose, thinking out loud here, that if you put the extra instrumented code at the start of the block, then an interrupt or an unscheduled stop might invalidate the proof; if you placed the instrumentation at the end of the basic block (in blue in the figure), then, by reaching it, you can reasonably assert that you had to have executed the prior instructions to get there.
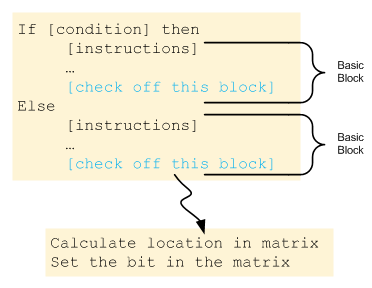
The coverage is tracked in a scoreboard-like matrix, and so “checking off” a block involves setting a value in a position of the matrix that corresponds to the block just executed.
The challenge here is performance. A straightforward “index into a matrix” operation involves calculation of target addresses each time. This may sound trivial, but, apparently it adds up. And multicore makes it worse, not only because you might expect such new programs to be bigger, but because now you have the possibility of collisions. We’ll talk about collisions in a second, but let’s first address performance.
In order to reduce this computational overhead, LDRA implements code that pre-calculates destination addresses at compile time. I haven’t seen exactly how that works, but the effect is analogous to changing an indirect store to a direct store operation. This apparently saves lots of time during program execution.
That aside, let’s return to the collision question. There’s one big scoreboard for the entire program, not for each core. So two cores might try to write at the same time – an impossible situation for a single-core system. There’s some nuance to this, since you might think that memory controllers should hide the fact that two memory requests are made at the same time.
There are lots of ways to design a scoreboard, but for compactness, LDRA packs bits. The memory controller can manage separate words or bytes (or whatever its granularity is), but it can’t manage bit-packing. So if two cores attempt to set bits that happen to be packed into the same word, then there’s an unresolvable collision. And performance means that you don’t want one to be waiting around until the other finishes. (And I can’t imagine what the ugly performance impact would be if you naively tried to spawn separate non-blocking terminal threads for each of those writes to unblock the testing of the code…)
The way LDRA deals with such collisions is to abandon an attempt to check a bit in a word that’s already in use by some other check-off. First come, first serve. In fact, first come, only serve.
This means that, even though the instrumentation says to “check off the block,” it may not actually happen if you collide with a different core checking off a different block. For this specific instance, you could consider this a “false positive.” In other words, if you immediately used the resulting bit values to determine whether or not the block got covered, it would say that it didn’t get covered, when in fact it did – it’s just that the logging operation failed.
This is conservative behavior: critically for mission-critical software, it won’t create a false negative. Said differently, coverage tracked in such a way might be better than indicated; it won’t be worse. That’s important to know.
But still, false positives aren’t fun. No one wants to go through a list of “fails” only to find that they weren’t, in fact, fails. It takes a long time to do the analysis, and you end up with this long exception list that just feels… messy, especially when you’re trying to build confidence in the code.
There are two solutions to this issue. The first is to do nothing – literally. Embedded programs love loops, so you may fail to check off a block during one loop iteration; no problem, you’ll probably hit it the next time. For this reason, even though an individual write might indicate a false positive, by the time you’re done executing the entire program, most of those will likely have disappeared.
But there still could be some stragglers remaining. In order to deal with that, LDRA provides control over how many bits get packed into a word. If you make each word sparser, then there are fewer possible collisions. The limit is to have one word per matrix cell. At that level, the memory controller can manage the collisions, and you’re good to go. The cost, of course, is the size of the matrix.
You can find more in LDRA’s announcement.


