


It’s like Manifest Destiny all over again (hopefully without the dark side). There’s an inexorable move to the cloud for computing – and yet all the pieces aren’t in place yet to make it ridiculously easy to get secure cloud connections. So today we discuss three different stories about moving to the cloud. One is EDA-related; the others apply to automotive and the Internet of Things (IoT).
Rolling Rolling Rolling Your Own
Part of what’s happening is the gradual move from roll-your-own cloud implementations to products that abstract away a lot of the fiddly bits. We start, in fact, with a discussion I had with eSilicon at DAC in June. They embarked on a project to move to the cloud a while back, with a proof-of-concept implementation in place in early 2018. They were doing this completely on their own – with, of course, the collaboration of the resources they were using.
The problem they were solving was typical: wrestling with the capital requirements for buying enough compute power to handle peak loads in-house. This is the classic motivator for moving to the cloud, and yet they didn’t want to change the way their designers used the tools; the move to the cloud should be opaque to them.
At present, they’re a Google house. There’s nothing strategic or limiting in the implementation – they could use, for example, Amazon if they wanted or needed to for the sake of some customer. The machines they use aren’t multi-tenanted – that is, any machine they commandeer is dedicated only to them, with one exception: preemption. They get a 70% cost reduction by using machines that might get preempted. Within the first 24 hours, they may get preempted; after 24 hours, they will get preempted. But it’s the entire machine, not just a virtual machine, that gets preempted.
You may, of course, note that many EDA jobs can run for longer than 24 hours. If you get kicked off and have to start over, well, you may never finish, since you’ll always run over that 24-hour mark. For this reason, they use checkpointing so that, if they are booted for a bit, they can pick up close to where they were and finish the job.
As to how they manage files, they’ve used Elastifile, whom we covered last year. This allows NFS usage while in process, with object storage for archiving. But there’s a lot of NFS data when uploading a new job, and they were concerned that folks who were simply trying, for instance, to get a license, would be stuck waiting for all that data. So they created two separate VPN tunnels: one for control data (like licenses), and the other for the NFS data. They’ve also been looking at Oracle’s Grid Engine, but there are some missing features there that are being worked on. eSilicon may move over to Grid Engine in the future.
They also found that there was a fair bit of static data – stuff that didn’t change during processing, like PDKs and the tools themselves, that they could provision natively in the cloud environment so that they weren’t spending so much time synchronizing.
Some potential clients of eSilicon are going to care where the data and computing take place. Sensitive designs have to be in a particular country – they can’t happen just willy-nilly anywhere in the cloud. But they have built in the ability to specify a location to ensure that they don’t run afoul of any such requirements.
So far, they’ve had no problems with any EDA tools in the cloud. They can transfer licenses with no problem. That said, it’s not like this is an, “OK, we’re done, we can move on” thing. This space is evolving quickly, which means change will be needed. ESilicon doesn’t see this cloud setup thing as secret sauce; it’s just a productivity and capital-management tool for them. So they’re not wedded to the specific way they’re doing things now. They can move as the industry moves.
Building Their Own TCP-Lite
Meanwhile, DH2i has announced a product for remote connection into the “virtual” network that they build. But we should step back and take a look at the bigger picture, since it involves their new DxConnect product and an existing DxOdyssey product. Their operating assumption is zero trust. Yeah, they’ve got trust issues. Let’s start with the problems they’re trying to address, of which there are three.
- First of all, the standard way of making a computer service remotely available is the well-known port number thing. You open a port that others expect to use – creating a security threat.
- TCP provides some useful functions, but it’s a heavyweight protocol. In addition, all traffic goes through a controller – and that includes the data itself, not just metadata. The controller doesn’t do anything specific with the payloads; they merely pass through. But this becomes another potential attack point.
- Finally, the typical way of connecting “securely” is through a virtual private network (VPN). The problem is that this provides access to the entire network on which the desired resource resides. By giving access to that resource, you’re also potentially allowing someone to roam around on that network, looking for other resources to which they perhaps should not have access.
The way DH2i has handled this is first by replicating the key TCP features – segmentation-and-reassembly (SAR) and retry – over UDP/DTLS. They leave the other TCP capabilities behind, making for a faster, lighter-weight connection. They don’t use VPNs, which operate below layer 4 of the OSI networking model; they do everything on layer 4.
The issue of open ports is handled by a Matchmaker service that they provide. No well-known ports are left open. Indeed, ports are open – as they have to be for anyone to get access – but which ports are used for what is dynamic; they’re not well known. Devices tell the Matchmaker which port they’re using, and the Matchmaker then helps one device to try to find another. Unlike the TCP controller situation, no payload data flows through the Matchmaker. Even authentication between the two sides of the connection happens directly; the Matchmaker is used only for keeping track of ports in use.
Of course, you might think that any open port is a risk, which, in the limit, it is. But they’re not advertised. You can’t find out which ports are open without scanning – or hacking the Matchmaker. Even then, the data is encrypted using a proprietary DxOdyssey format, making any accessed data meaningless.
Meanwhile, they have narrowed the granularity of access. Unlike a VPN, which simply places you on the network and wishes you good sailing, they create a software-defined perimeter. You can grant access by user, group, device, or some combination thereof; access can be given to a network, a specific device on a network, a specific container in a device, or a specific application only.
DH2i has three diagrams showing how privileged users, service meshes, and edge devices, respectively, can leverage DxConnect.
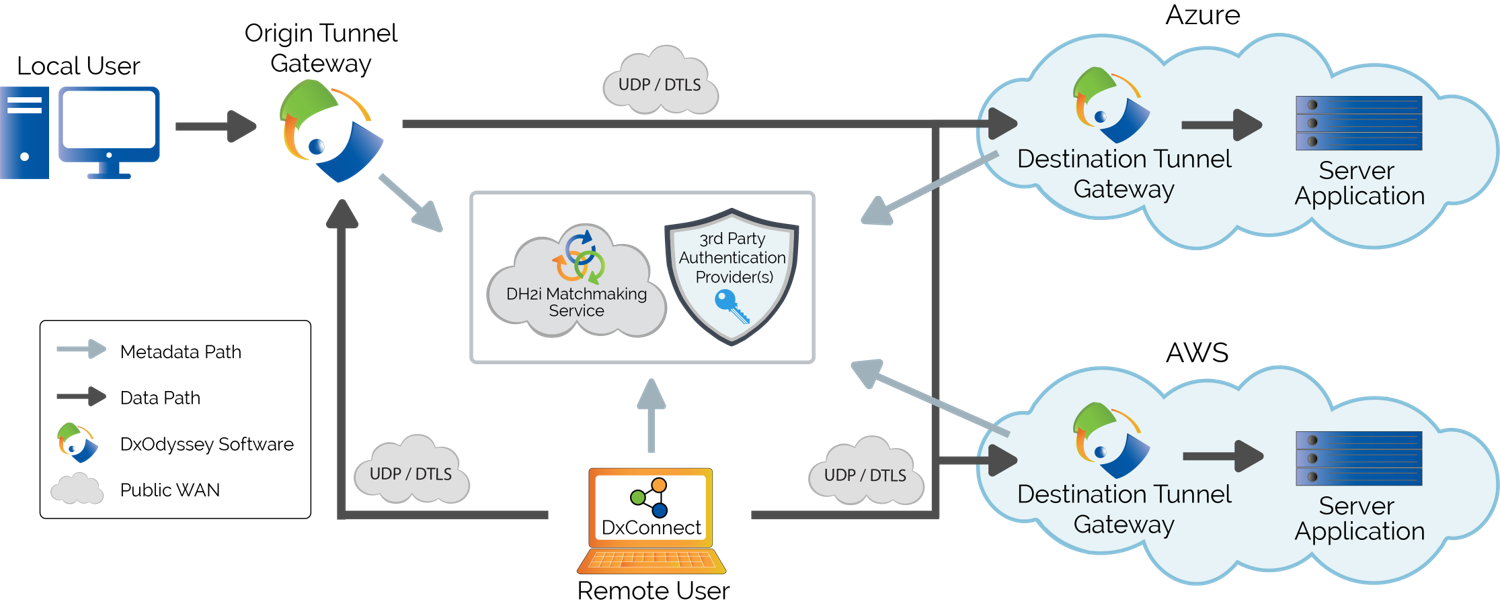
(Click to enlarge; image courtesy DH2i)
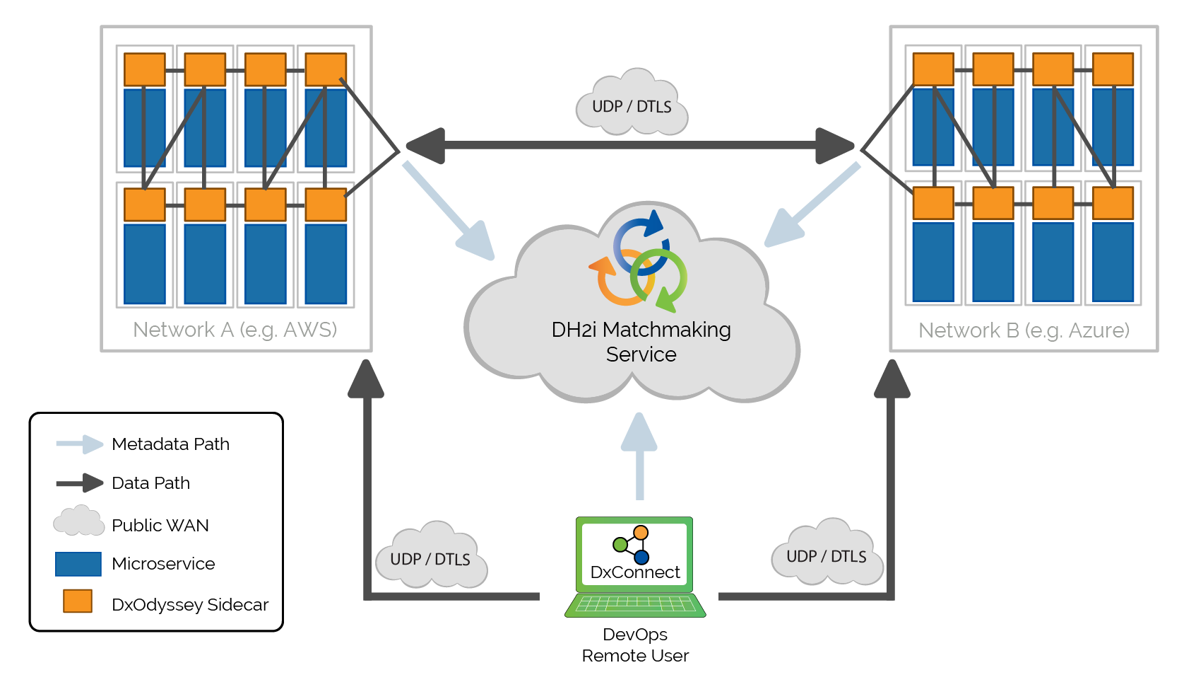
(Click to enlarge; image courtesy DH2i)
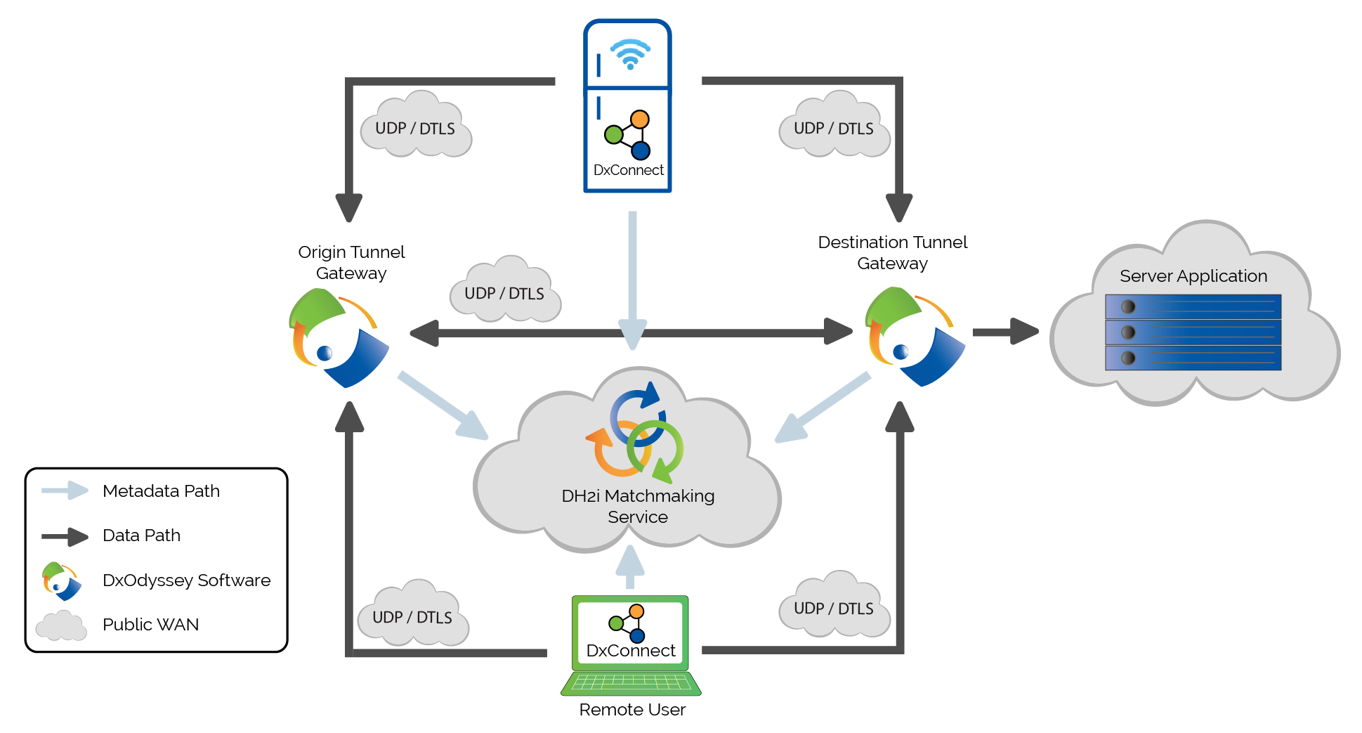
(Click to enlarge; image courtesy DH2i)
How to Communicate All the Data?
Finally, we take another step in the direction of automotive autonomy. We looked at Excelfore’s eSync product last year, but that established simply how the car can talk to the cloud (or vice versa). But how do you manage all of the data going up to the cloud in a world where a car may drive through iffy – or missing – connections?
That’s what their recently announced eDatX product handles. You ideally want all the data in its rawest, most granular format for later analysis. This involves two activities: aggregation and analytics. The former is about getting all the data together; analytics is about learning something from the data. They consider data viewing and reporting as “analytics-lite.”
Their focus is on aggregation and analytics-lite. But here’s the thing: let’s say you’re aggregating all the data, spewing it up into the cloud as fast as you can – and you lose the connection. Now what? The data is still coming in unimpeded, and now it’s starting to pile up with nowhere to go. Once the connection is re-established, can you ever catch up again? Will you end up losing some data outright?
DH2i allows some local compaction of data if it starts to accumulate too much. And by compaction, I don’t mean zipping it up. Essentially, you’re doing some filtering or pre-analytics to reduce the volume of data you’re going to send up. Exactly how that compaction is done is determined by the company using the service.
Yes, you’re losing some data by reducing it. But you do so strategically. Without this, when the rolling buffers that hold the data roll over and start overwriting data that hasn’t been transmitted yet, then you’re simply throwing all kinds of stuff out with no rhyme or reason to what you give up.
They do this by sending the data from the rolling buffers into local storage, from which the data is sent to the cloud. The storage may be central or it may be attached to a device. If it’s central, then eDatX manages it. If it’s within the device, then the eSync Agent has drivers to access the local buffer. You can specify rules for compaction, and those rules act on the data in that storage. If the data is local to a device, then the eSync Agent lets those rules be applied locally through an interface that’s custom to each device.

(Click to enlarge; image courtesy Excelfore)
To be clear, this is an all-software solution. There is no hardware; it relies on the hardware already in place, creating drivers as necessary.
And so we have more EDA in the cloud, we have a new more secure way to access the cloud, and we have a way to send data to the cloud even with a squirrely connection. All part of making this cloud thing stronger and safer.
More info:
eSilicon’s DAC presentation (with Google)
Sourcing credit:
Don Boxley, Co-founder/CEO
Thanh “OJ” Ngo, Co-founder/CTO
Mark Singer, Director of Marketing, Excelfore
David Marshall, Enterprise Architect, Global IT, eSilicon




Today we saw eSilicon’s experience in the cloud; DH2i’s new means of establishing secure, precise connections, and Excelfore’s approach to uploading data when connectivity isn’t guaranteed. What do you think about these things?