


I recall seeing the very first Mad Max movie in 1979. In this torrid tale, a dystopian near-future Australia is facing a breakdown of civil order. Max (no relation) is a police officer who turns into a vigilante, which isn’t surprising when you see what he sees and experiences. All I can say is that the final scene is so powerful that it’s as fresh in my mind as when I saw it 50+ years ago.
The pace picked up in Mad Max 2, which was released as The Road Warrior in the United States. By this time, civilization has collapsed, and the world has descended into barbarism. Mad Max 2 was my favorite, closely followed by Mad Max 3, which was released as Mad Max Beyond Thunderdome.
I especially remember the scene in Mad Max 3 where Max has to relinquish his weapons before entering Bartertown, and he proceeds to unload an astonishing stash of hardware.
I feel a bit like this myself whenever I’m obliged to empty my pockets and divest myself of any tools and metallic objects for some reason. At first glance, I appear harmless enough, but my untucked Hawaiian shirts disguise a technoglumptious trove of tactical treasures. In addition to a couple of knives, I invariably carry a tape measure, flashlight, multimeter, and pocket toolkit secreted about my person. I joke that I’m prepared for the forthcoming zombie apocalypse, but I fear I’m not entirely joking, because the zombie apocalypse is really a metaphor for societal breakdown. But we digress…
It wasn’t until 20 years after Mad Max 3 that we were treated to Mad Max: Fury Road in 2015, and then we had to wait almost another decade before Furiosa: A Mad Max Saga arrived in 2024.
“This is all very interesting,” I hear you cry (or not, as the case might be), “but what does this have to do with me?” Well, if you’ll settle down and stop being so impatient, I’ll tell you.
I was recently chatting with Alex Liu, SVP of Product and Business at FuriosaAI. Naturally, I had to ask about the origin of the company’s moniker. Alex admitted that the company’s founder and CEO is a big fan of Mad Max (again, no relation), and he was inspired by the energy of the Furiosa character, seeing the kind of grit and momentum he wanted the company to embody.
At this point, you may be wondering whether FuriosaAI builds post-apocalyptic armored vehicles. In fact, the company builds something arguably more useful in today’s world: a data-center inference accelerator called RNGD (pronounced “Renegade”). And yes, this name is entirely intentional.
But this isn’t just another “we built a faster GPU” story. FuriosaAI isn’t trying to make a slightly shinier graphics processor. Instead, it’s arguing that GPUs—as magnificent as they are—were never architecturally intended to be the long-term engines of AI inference.
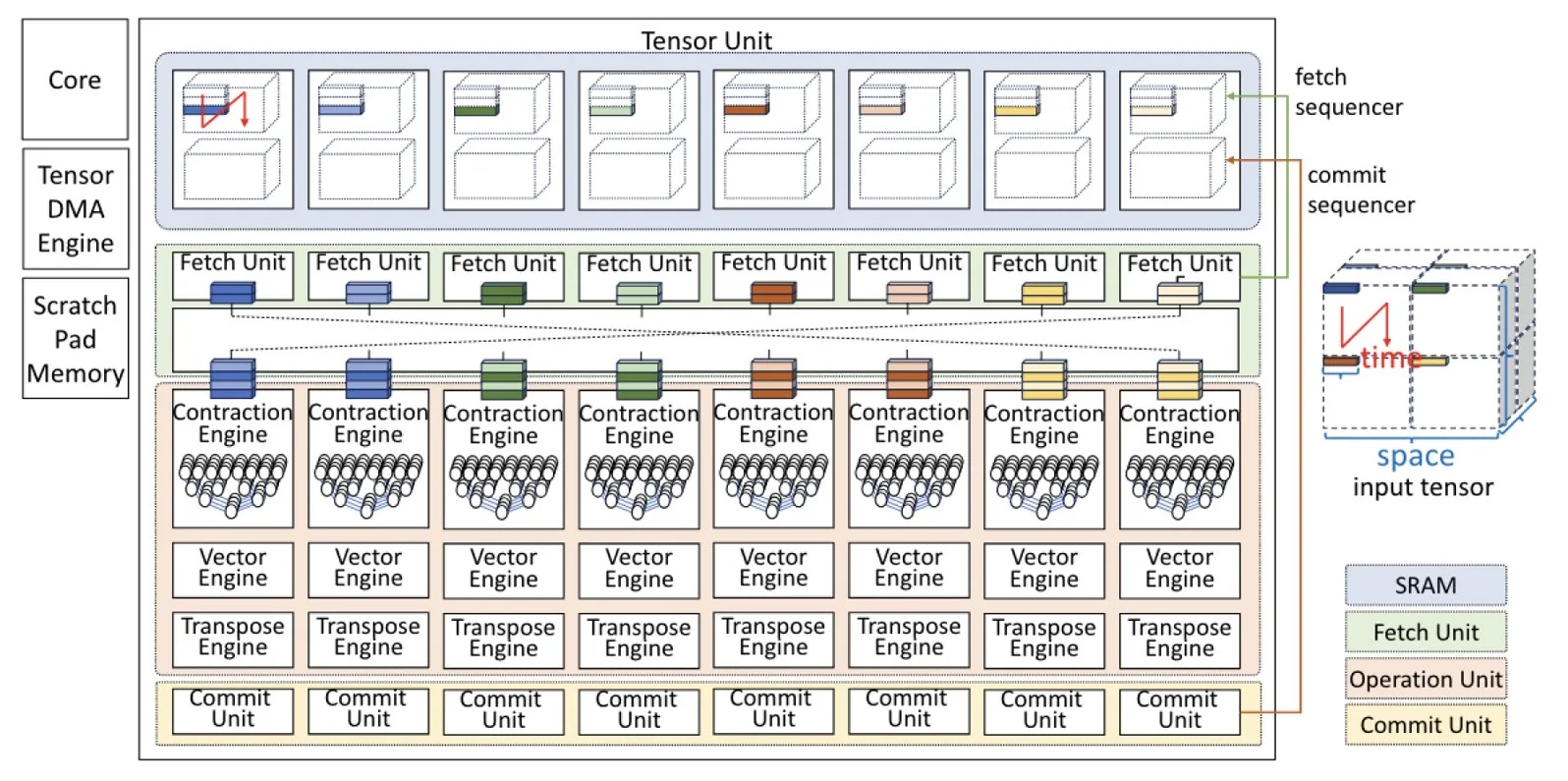
In a crunchy nutshell: GPUs were born to push pixels, but AI needs to push tensors. Furiosa’s position is that if tensor operations are the fundamental primitives of modern AI—especially transformers and large language models—then hardware should be designed around tensor contraction, not matrix multipliers bolted onto SIMT graphics architectures.
But what’s “tensor contraction” when it’s at home? Well, at its heart, a tensor contraction is just a multiply-and-sum over a shared dimension—a glorified matrix multiplication extended into multiple dimensions, if you will (or even if you won’t). If matrix multiplication is the two-dimensional case, then tensor contraction is the full multidimensional generalization. Since modern AI models are built almost entirely from these operations, Furiosa decided to treat tensor contraction—not graphics threads, not CUDA cores, not even matrix multiply—as the fundamental primitive of its hardware.
This philosophy gave birth to the company's Tensor Contraction Processor (TCP) architecture. Coming at this from a slightly different direction, most commercial AI accelerators—including GPUs—ultimately reduce workloads to matrix multiplications. The guys and gals at Furiosa have taken a different path. Instead of mapping tensor contractions onto fixed matrix units, TCP treats tensor contraction as the native execution model.
This may sound like a subtle distinction, but it changes everything. Modern AI workloads— particularly large language models (LLMs)—are fundamentally structured as multidimensional tensor contractions. By designing hardware that “thinks” in tensors from the outset, the chaps and chapesses at Furiosa claim they can maximize data reuse, reduce unnecessary data movement, execute deterministically, and avoid dynamic cache chaos.
The deterministic aspect is especially interesting. GPUs rely heavily on dynamic scheduling and complex cache hierarchies. The TCP, by contrast, is compiler-scheduled and pre-orchestrated. Data movement and compute are coordinated in advance, reducing stalls and improving predictability. In the AI era, moving data often costs more power than manipulating it. The TCP’s architecture addresses this uncomfortable truth.
(Source: FuriosaAI)
It’s important to note that this is not an edge play. Many AI chip startups aim at the edge (cameras, robots, drones, smart appliances), but the RNGD is unapologetically a data center inference accelerator.
Fabricated in a 5nm process, the TCP chip operates at roughly 150W thermal design power (TDP). This means the cooling system must continuously remove 150 watts of heat to prevent the chip from overheating. Since nearly all of the electrical power consumed by a processor is converted into heat, TDP is closely related to power consumption, but it’s specified from a cooling perspective, not an electrical one. Why this matters is that a 150W TDP means the TCP can run in standard air-cooled servers and fits within typical enterprise rack power budgets.
While much of the AI arms race has drifted toward 600W+ GPUs and liquid-cooled superpods, Furiosa is explicitly targeting existing air-cooled enterprise data centers.
The folks at Furiosa package the TCP as a PCIe accelerator card or an 8-card, 4U rackmount server. Eight cards plus host overhead consume roughly 3kW per server. This means you can stack five of these servers in a standard 15kW air-cooled rack. In turn, this translates to approximately 20 peta-operations per second (INT8 equivalent) per rack, all without liquid cooling or infrastructure retrofits.
Alex told me that raw FLOPS are increasingly meaningless in the context of inference economics. Furiosa focuses instead on Tokens Per Second per Watt (TPS/Watt)—a metric that maps directly to operating cost in production LLM environments. In production validation with LG AI Research, RNGD demonstrated 2.25X better performance per watt as compared to deployed NVIDIA GPU infrastructure. Meanwhile, under rack-power constraints, Furiosa claims 3.5X greater throughput per rack compared to H100-based systems.
Benchmarks always depend on conditions, of course. But what’s notable here isn’t the marketing multiple—it’s the framing. The bottleneck in modern AI infrastructure isn’t math; rather, it’s power, cooling, rack density, and total cost of ownership. RNGD is engineered around these constraints.
Another distinction is that FuriosaAI is not YAPPS (“Yet Another PowerPoint Startup”). The company began in 2017 and now employs roughly 200 engineers, many with deep semiconductor backgrounds. And RNGD is in mass production, with thousands of units already delivered via manufacturing partners including TSMC and ASUS. In the AI accelerator space, the gap between architectural theory and shippable silicon is enormous. Furiosa has crossed that chasm.
What’s that you say? You want to see a video? Well, perhaps one of the best videos breaking down FuriosaAI’s technology and architectural approach is the Microchip Breakthrough No One Expected offering from Anastasi in Tech.
But wait, there’s more, because hardware alone doesn’t win inference deployments. With its SDK, Furiosa is clearly targeting production environments:
- Hybrid batching and intelligent prefill/decode scheduling
- Prefix caching for RAG and agentic workloads
- Native Kubernetes support with an NPU operator
- Distributed inference framework
- Rust-based OpenTelemetry integration
- Drop-in replacement compatibility for vLLM
- OpenAI API compatibility
In a market dominated by one very large GPU vendor, calling your architecture “Renegade” might sound theatrical, but FuriosaAI isn’t trying to out-GPU the GPU. Instead, it’s arguing that inference has different physics than training, and that deterministic tensor-native execution can deliver better infrastructure economics than brute-force scaling of graphics-derived architectures.
If GPUs are the muscle cars of AI, Furiosa is trying to build a vehicle tuned specifically for long-haul logistics, optimized not for peak horsepower, but for sustainable throughput under real-world constraints. In a world increasingly constrained by power budgets rather than transistor budgets, this may prove to be a surprisingly efficacious (if a tad rebellious) strategy.

