


There’s an old joke that I remember from when I was a kid. It started when my dad asked, “When is a door not a door?” I looked at him blankly (a look I’ve since perfected over the years) until he came up with the punchline, “When it’s ajar,” at which point he would convulse in mirth. Well, I have one for you, which goes, “When is a kernel not a kernel?”
I will present the answer to this poser in a moment, alongside some really exciting news pertaining to AI on the edge, but first… to bring us all up to speed… let’s start by reminding ourselves that the core of Ambiq’s claim to fame is its patented subthreshold power optimization technology (SPOT). I’ve talked about this before, most notably in my 2022 column: Is Ambiq’s Apollo4 Plus the World’s Most Energy Efficient MCU?
I first heard about subthreshold digital design techniques many moons ago, but only in the context of relatively simple product implementations, such as wristwatches. I was blown away when I discovered that the folks at Ambiq were utilizing this technology to design entire ultra-low-power processors.
In a crunchy nutshell, in conventional CMOS design, transistors switch between fully off and fully on states using supply voltages well above Vth (the threshold voltage at which a transistor just begins to conduct current), which is typically 0.8V to 1.0V for modern MCUs. Ambiq’s SPOT circuits, in contrast, operate in the subthreshold region—typically around 0.3–0.5 V—where current flow is exponentially smaller. This reduces active and leakage power consumption by an order of magnitude or more, while maintaining functional digital logic through careful transistor-level design and adaptive biasing.
In a later column, SPOT Platform Gives Ambiq’s Apollo510 MCU an Unfair Low Power Advantage, we were introduced to the Apollo510 microcontroller. This first member of the Apollo5 family flaunts an Arm Cortex-M55 core with Helium (M-Profile Vector Extension, MVE) support. This little beauty provides unrivaled energy efficiency, boasting 300 times more inference throughput per joule, and is built to handle advanced artificial intelligence applications, including speech, vision, health, and industrial AI models. More recently, Ambiq introduced its Apollo510B, which also boasts a dedicated Bluetooth Low Energy (BLE) 5.4 radio for effortless wireless connectivity.
We’re still setting the scene. The focus for Ambiq’s chips is AI in embedded space and at the edge where the “internet rubber” meets the “real-world road.” Sad to relate, the data scientists who create most of the AI models typically come from the laptop world, if not the server world. They are used to running things in Python, not C. They like to have a file system, which isn’t guaranteed in embedded space (where no one can hear you scream). They are also used to having large amounts of compute, memory, and power, so you can only imagine their reaction when they find themselves in the “no fun zone.”
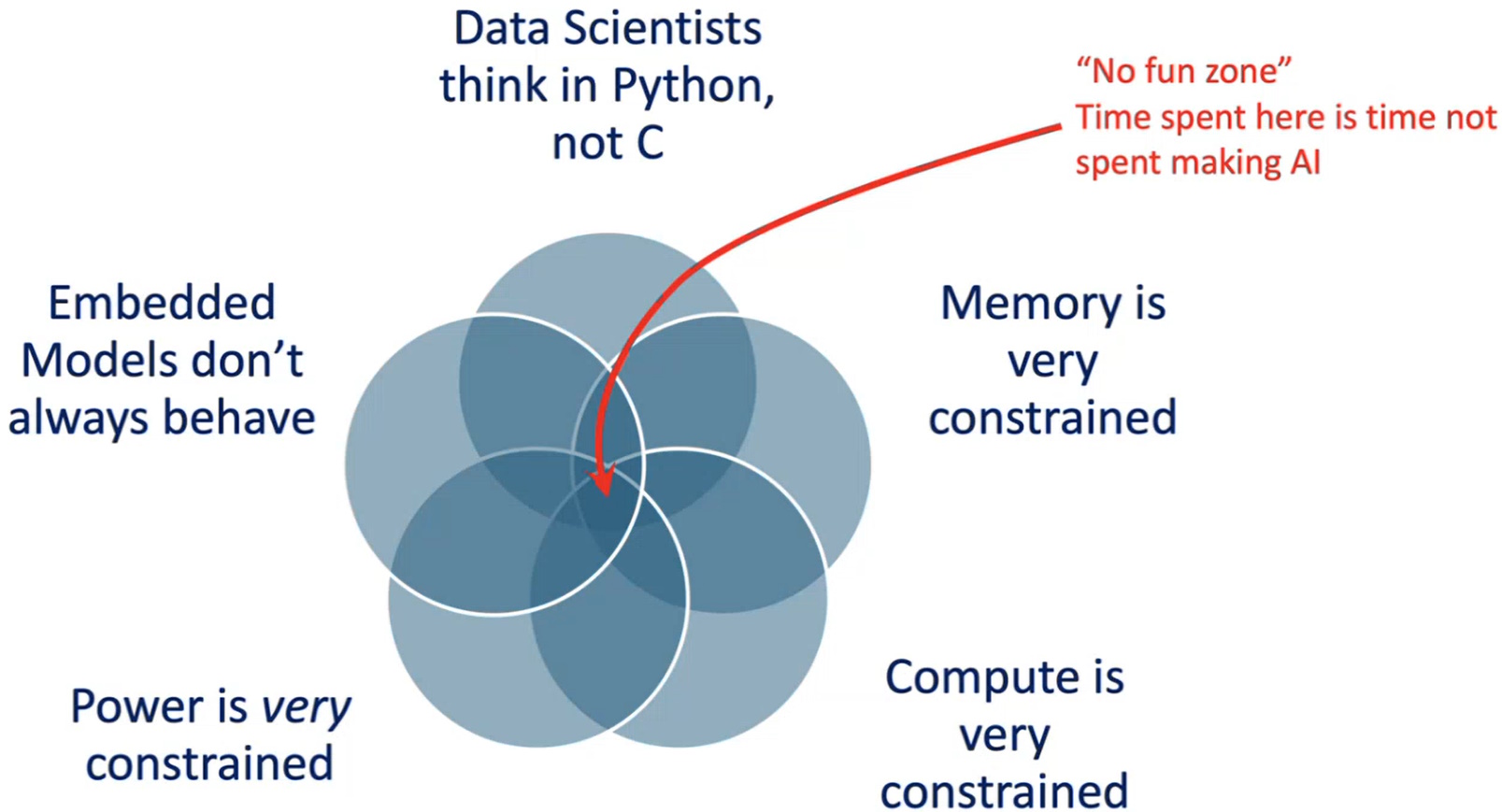
Embedded environments make AI harder (Source: Ambiq)
One thing that makes their lives easier is Ambiq’s open-source AI SDK / development toolkit, neuralSPOT. This is designed to simplify the development and deployment of AI (inference) models on Ambiq’s ultra-low-power Apollo family of SoCs. neuroSPOT is OS-agnostic (it can work without depending on a specific operating system) and is intended for real-time AI on edge devices.
Let’s look at this from the perspective of data scientists (bless their little cotton socks). With neuralSPOT, they can still “do their stuff” on their laptops. The trick is that they can also have one of Ambiq’s evaluation boards plugged into the laptop via USB. Now they can deploy that model, test it as if it were on their laptop, profile it, and ensure that the performance, memory utilization, and everything else are as required.
Speaking of deployment, we also have neuralSPOT AutoDeploy. This is a utility within the neuralSPOT SDK that automates the steps involved in converting a TensorFlow Lite (TFLite) model into a deployable, profiled, and optimized binary for an Ambiq device. It’s intended to reduce hand-crafted steps, ensure consistency, and speed up iteration.
However, none of the above is what I set out to discuss. I was just chatting with Carlos Morales, VP of AI at Ambiq, who was kind enough to bring me up to speed with the latest and greatest happenings that will shape the next wave of AI at the edge. The hot news here is Ambiq’s recent introduction of two new edge AI runtime flows: HeliaRT and HeliaAOT.
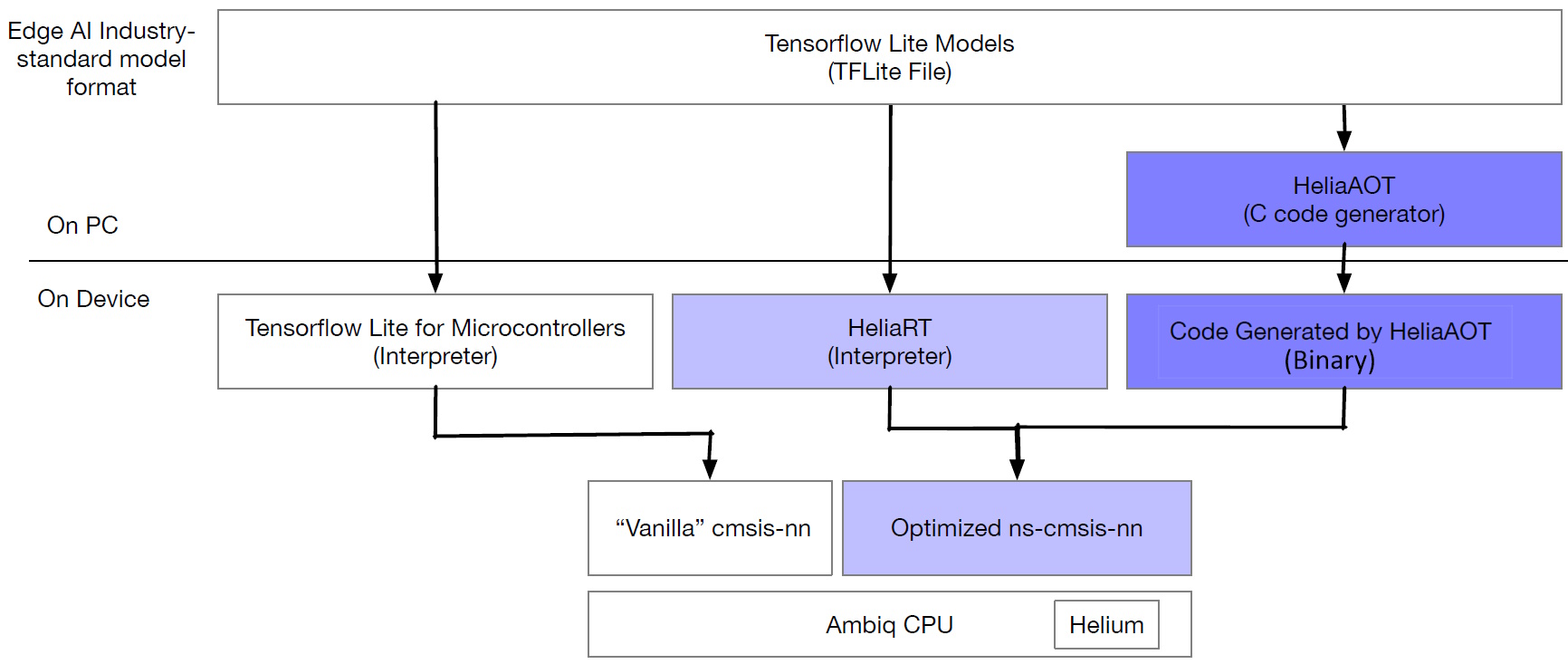
Alternative runtime flows (Source: Ambiq)
“But what is an edge AI runtime?” I hear you cry. I’m glad you asked. It’s the bit of code that executes the model on the end device (in the case of edge AI, “executing the model” means “performing inference”).
Let’s start with a traditional flow. At the “top” (well, at the top of the above diagram), we have an AI model in the industry-standard TensorFlow Lite (TFLite) format. At the “bottom,” we have the processor that will be executing the model—our Ambiq processor with Helium extensions, in this case.
Conceptually, sitting just above the processor, we have a library of kernels. This brings us back to our “When is a kernel not a kernel?” question. In the embedded world, the term “kernel” typically refers to the core part of an operating system (OS)—that is, the part that manages tasks and threads, handles interrupts and timing, and coordinates resources such as memory. However, in AI/ML/DSP circles, the same word refers to a math routine (e.g., convolution, multiply–accumulate).
For the purposes of these discussions, we can think of a kernel as a low-level math function that performs a fundamental numerical operation used inside an AI/ML model—typically on tensors (multi-dimensional arrays of numbers).
In conventional Arm space, the basic kernel library is known as cmsis-nn (where the “nn” stands for “neural network”). The reason this is annotated as “vanilla” in the diagram above is that the people who created and maintain this library of kernels need to accommodate everyone, which means they largely end up with generic optimizations.
Now observe the block marked “TenserFlow Lite for Microcontrollers (TLFM).” This is an edge AI runtime in the form of an interpreter, approximately 30KB in size. By “interpreter,” we mean a program that reads and executes code directly, line by line or instruction by instruction, instead of compiling it into a binary first. It’s this runtime that decides which kernels to use from the cmsis-nn library.
In the case of HeliaRT, the folks at Ambiq basically forked the open-source TFLM and then optimized the heck out of it. At the same time, they forked the cmsis-nn kernel library to form their own ns-cmsis-nn equivalent (where “ns” stands for “neuralSPOT”) and optimized the heck out of that also. Remember that the creators and maintainers of TFLM and cmsis-nn want to make everyone happy. By comparison, the folks at Ambiq aren’t concerned with making anyone happy… apart from their own customers, of course.
What this means for users, at least for Ambiq’s customers, is that they can swap out the TFLM they are already using, plug in HeliaRT, and everything will automatically run much faster. “How much faster? I hear you plaintively cry. “Five times faster or more!” I exuberantly reply.
Consider the chart below. Each comparison is normalized to show the TFLM at 100%. Even in the case of industry-standard benchmarks (VWW, KWS, and IC), which everyone optimizes for, HeliaRT is ~2 to 5% faster, and this improvement increases to 500% or more in the case of real-world models.
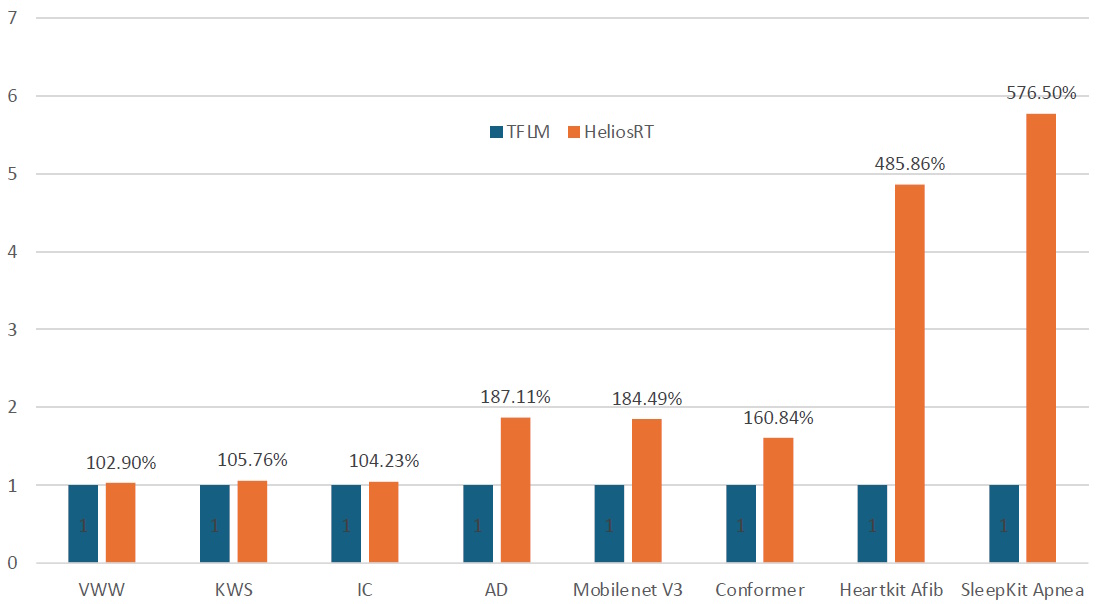
Performance increase with HeliaRT (Source: Ambiq)
But wait, there’s more, because the chaps and chapesses at Ambiq have also introduced HeliaAOT, where “AOT” stands for “Ahead of Time.” This accepts the same TFLite model as the other flows, but converts it into C. Users love this because it means they can merge this C code with their other C code, and it appears just like any other C function, rather than a “black box” that requires an interpreter.
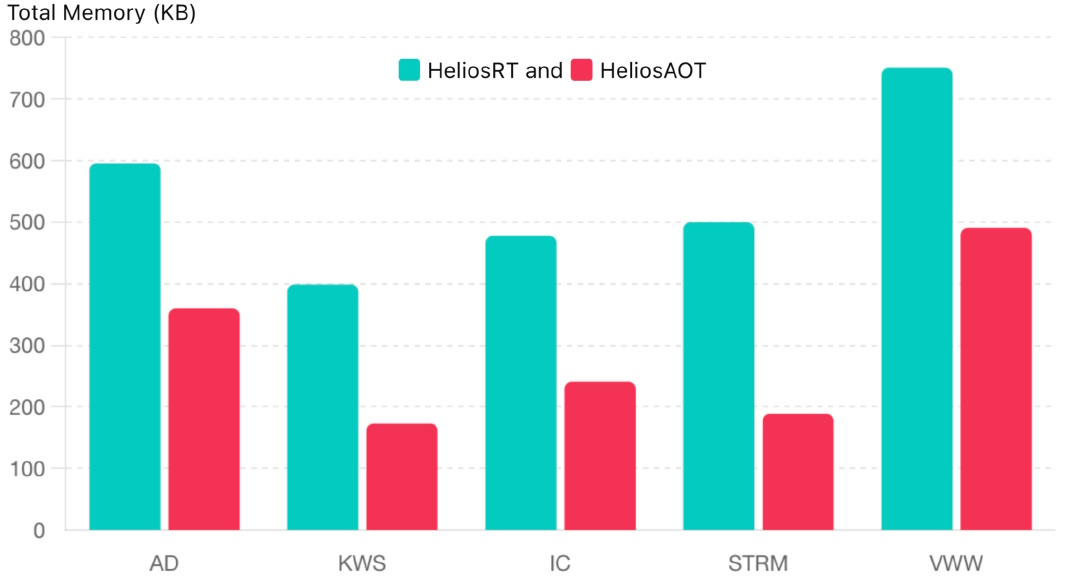
Total memory usage by model and build (Source: Ambiq)
This HeliaAOT flow offers the same or better performance as the HeliaRT flow, but with a much smaller memory footprint.
While we’re here, it would be remiss of us to neglect the concept of “granularity.” In fact, there are two aspects to this—memory granularity and execution granularity. Let’s start with memory. In the case of an embedded interpreted runtime, memory ends up being treated as two “big blobs” (I hope I’m not being too technical). That is, all the weights will be stored on one type of memory (be it MRAM, TCM, SRAM, or PSRAM). Similarly, all the model RAM will be stored in TCM, SRAM, or PSRAM. By comparison, in the case of HeliaAOT, you have the flexibility to put the weights and model memory associated with different layers in the most appropriate type of memory.
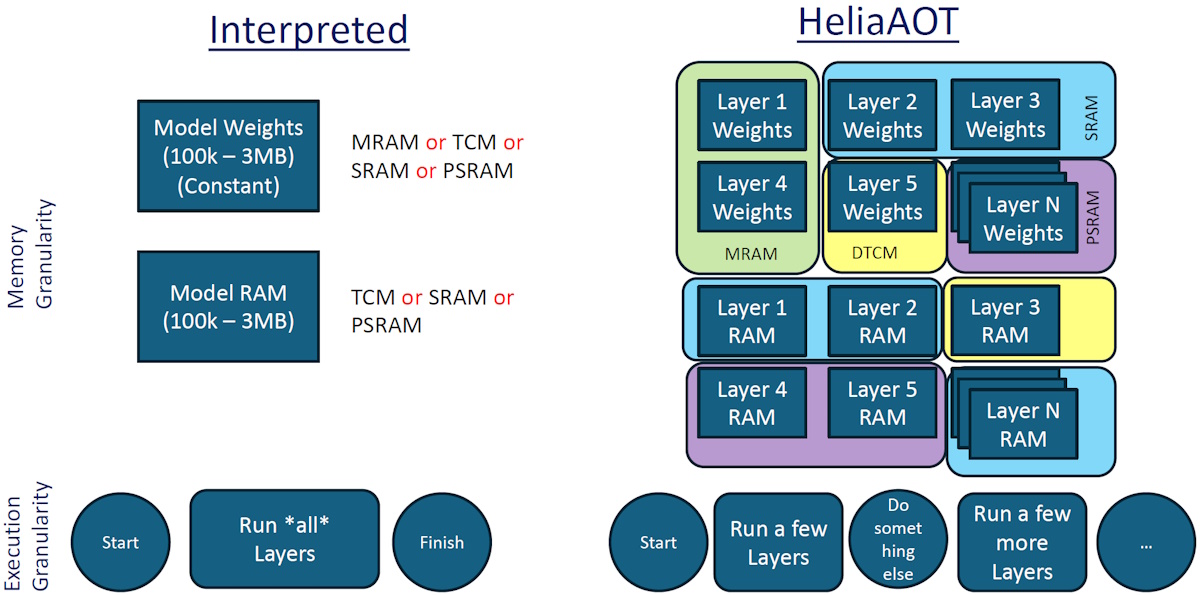
Granularity is good (Source: Ambiq)
Now, let’s consider the concept of executable granularity. Typically, embedded and/or edge devices do not run only one model at a time—most of them run multiple models simultaneously. Well, I say “simultaneously” with “air quotes” because an interpreted runtime requires that you run each model to completion before switching to the next. This might not be so bad if each model consumes the same amount of time, say 1ms, but it’s less than efficacious if one model consumes 50ms while the others all take 1ms to 5ms, for example.
In the case of HeliaAOT, each model is just a bunch of C calls (well, the machine code associated with those C calls), which means you (or your operating system, if one is present on your device) can switch back and forth between models as desired.
There’s so much more to talk about—I fear we’ve only scratched the surface of this topic—but I don’t wish to outstay my welcome, so I think this would be a good time to pause and ponder what we’ve learned so far. As always, I’d love to hear your thoughts on all of this.


Very Cool Beans — I just heard that, only a few days after I posted my column, Ambiq’s SPOT platform was named one of TIME magazine’s best inventions of 2025 (https://ambiq.com/news/ambiq-spot-platform-named-one-of-times-best-inventions-of-2025/).
Coincidence? I think not (well, that’s my story, and I’m sticking to it!)