


[Editor’s note: this article has been updated at the end. In addition, new information from more recent products meant a change to the current used and the update model.]
The wild and wooly world of wireless is still bubbling with new things. We’ve become accustomed to three contenders for short- to medium-range wireless: WiFi, BlueTooth, and ZigBee. And we saw before that there is a profusion of longer-range, lower-power protocols vying for primacy.
Well, today the plan was to look at a couple of new protocols (or, at least, new to us) that are based on shorter-range familiar technology. One, from Synapse Wireless, shares the bottom of its stack with ZigBee; the other, a new WiFi variant newly branded as HaLow, shares the top of its stack with conventional WiFi. But I still have questions outstanding to the WiFi folks, so we’ll have to push that off to some other time. So today we look at SNAP.
Synapses firing
At its root, in the PHY layer, Synapse’s approach uses the same radio standard, IEEE 802.15.4, that ZigBee uses. But above that, it sports a proprietary protocol they call SNAP. Synapse provides an unusually detailed list of FAQs on their website; most of what follows is derived from that.
There appear to be a couple of motivations for developing a new protocol. First, they claim that SNAP is streamlined, leading to a particularly low-latency solution that can be implemented with low-cost chips. But it also uses TCP/IP (including multicast), making it naturally suited to the overwhelmingly dominant amount of IP-based network traffic. Historically, ZigBee has not accommodated IP-based traffic, although, as we saw, that changed with ZigBee 3.0.
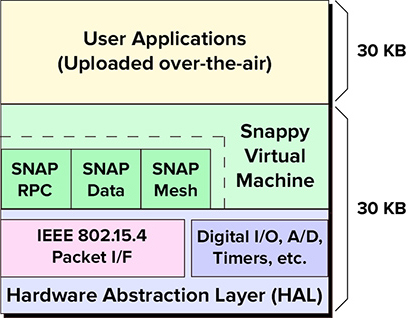
(Image courtesy Synapse Wireless)
SNAP is characterized by a peer-to-peer dynamic mesh, the point being that no failing node can cause the network to fail. The mesh uses routing (as opposed to flooding) to direct messages to their destinations. If a node goes down, then it can automatically route around the missing node (as long as there are other nodes within wireless range). Each hop contributes 15 ms to the overall message travel time. There is a default limit of 5 hops, but that can be changed to pretty much anything.
The overall size of the mesh can be up to 16 million nodes, with 64,000 networks and 16 channels. These limits are typically set by address spaces and, depending on the setup and the environment, can be best-case scenarios that other limitations end up short-circuiting.
Keeping messages from dropping under the eaves
Security is handled a bit differently from some of the more familiar protocols. The most secure option is to use AES128. That’s a symmetric (that is, not public/private-key) approach; every node has to have the same key. That doesn’t mean that it’s a global key for everything SNAPpy; presumably each network would have a different key that you define when you set up the network.
We’ve suggested before that asymmetric encryption has benefits over symmetric in that each node has its own key, so cracking the key in one node tells you nothing about the key in another node. Using that logic, it might seem that the mesh has weaker security with all nodes having the same key. But let’s picture a scenario where the mesh uses public key exchange instead, with each node having its own key.
That exchange process would need to take place between all pairs of nodes within range of each other. Each node would have to maintain a table of passwords for all neighbors. (Let’s not even think about what happens if the network reconfigures itself…)
Then, when it comes time to send a message to all neighbors, in the way that meshes tend to do, well… you can’t. Only one neighbor – the one with the key you used – would understand the message. Instead, in order to achieve the effect of broadcasting to every node in range, you’d have to resend the message individually for all of those nodes, each time with a different key. Yikes!
Now here’s a twist on this: with SNAP, the routing information in the message isn’t encrypted. This helps with latency, since, while the message is being passed from node to node, no decryption is necessary, which keeps latency from bogging down. (I don’t know if this adds a security vulnerability…)
So this addresses the broadcast scenario: the basic routing information isn’t locked by the key, so everyone local can get it. Only the final consuming node would need to unlock the message payload. Except… if that node wasn’t in direct range of the sending node, then there was no key exchange between the sender and receiver, so the sender wouldn’t know which key to use. Unless, of course, instead of in-range pairwise exchange, you did every-node-to-every-node-in-the-whole-network exchange. Yeah, yuck. So having a single password for every node in the network is starting to sound better and better.
That discussion may be Mesh 101 to those of you who have already thought this through. Which wouldn’t have been me, prior to a few minutes ago. But there’s nothing SNAP-specific about it.
SNAP also has its own proprietary security scheme, but they are open about the fact that AES is more secure. The SNAP security might be OK if there’s not much to guard, but, as we’ve noted in the past, it’s often not about the node when someone breaks in. It’s very likely to be about getting onto the network and finding gold somewhere else on the network.
So if you’re going to downgrade your security for simplicity, you have to make sure you’ve taken the entire network into account. If there is – or if sometime there might be – a trove of email addresses or credit card numbers attached somewhere else reachable, then you’ve got to tighten things down.
If two networks are running within listening distance from each other, Synapse lists three ways to keep the traffic separate: use a different network ID, use a different radio channel, or use a different key (which you would presumably do anyway). Not sure about the last one, since it feels messy to rely on failed decryption as a way of segregating messages. More to the point, that keeps one network from snooping on another.
Synchronizing watches
Any network that wants to participate in the Internet of Things (IoT) must prove its low-power bona fides. Synapse’s modules can be permanently active, in which case they draw about 20 mA. They say this equates to about 125 hours (roughly four+ days) using AA batteries. In sleep mode, however, they pull less than 2 µA. If they wake up once a minute for 300 ms, then Synapse says that those same batteries will last for 10,000 hours, or about 14 months.
This sleep thing can get tricky with a mesh, however. If left to their own devices, it’s pretty much impossible to guarantee that all nodes will awaken at the same time. They might do so close to the time when the network was initialized, but the longer the network runs, the more each node is going to be dancing to its own private drummer, waking up when it wants, with nary a consideration of its neighbors.
So how do you arrange for an entire network to be awake at once at any given time (or within any given time window)? I submitted this question to Synapse, and, to date, I haven’t received a response. So I’m left to speculate and, as a useful exercise, to think through what the possibilities might be. (And I’ll update if I get more info.)
The reason you sleep is to save power, and one of the biggest power hogs in the node will be the radio. So it’s not like you can keep the radios on and buffer any incoming messages for processing when the rest of the node awakens. When the node is asleep, it’s as dead to the world as your Uncle Albert at 3 AM, minus the deafening snore.
So the question is, if you’re going to synchronize wake-up between nodes, how would nodes know to wake up? There are two high-level scenarios I can imagine. In one case, everyone is programmed to awaken after some pre-determined interval. In the other, some trigger starts the wake-up process.
The latter case is enabled by the fact that each node has signals that allow some local hardware – a sensor or button or something within the node itself – to wake the node up. If that wake-up means a message has to be sent, then the rest of the network needs to wake up to propagate the message. Let’s take these scenarios in turn.
The first one, where all nodes awaken at a given time, sounds good, but it relies on all the clocks running at very much the same rate. The problem is, the longer the interval, the more the clocks will get out of synch. You might simply write this feature off, since more precise clocks are also much more expensive. But Bluetooth has the same problem in a phenomenon they refer to as “window widening.”
The idea is that a receiving radio has to be on and stable before the sending radio releases its message into the wild (plus or minus the speed of signals in air). Both nodes may be programmed to awaken at the same time, but, in the worst case, the receiving node’s clock is going to run at the slow end of the spec and the sending node’s clock will run at the fast end of the spec. So the longer the time between wake-ups, the more time the clocks have to diverge, and the greater the risk is that the sender speaks before the receiver is awake.
This sets up a process by which nodes have to awaken earlier and earlier the longer they run in order to ensure that they don’t miss a message (this is the “widening of the window”). But it also establishes a maximum sleep time, or else, after some long time, you’d hit the degenerate case of never being able to go to sleep.
So, bringing it back to our mesh, in the fixed-interval scenario, you could put a limit on the length of the longest allowed sleep interval. At that point, everyone wakes up, and, even if there is no message, they re-synchronize clocks, and the process starts over as they go to sleep.
You could also have the sender resend the message some fixed number of times, just in case the first one (or two) was missed. This would narrow the window, at the expense of the extra awake time and power required to send a message multiple times. (Acknowledgments wouldn’t work well, since you’d need to track them for all nodes in range to know whether they’d all received the message… doable but messy, especially if the network is reconfigured.)
In the second scenario, there’s no fixed interval; there’s a trigger. The problem is, how can one node wake up all the other nodes without a wireless trigger (since their radios are asleep)? You could connect a wire, but… nah. It would seem to me that this would have to be done in conjunction with interval wake-ups. When one node is triggered locally, it would have to wait until the next wake-up session to send its message.
Synapse may have some other way of doing this that I haven’t thought of, but this is what happens when my brain isn’t directed to a specific answer.
Both applications and firmware can be updated over the air. (In the past, you could update only applications, which play atop the firmware, over the air. But if you wanted to update the firmware itself, you needed to be physically present to update the nodes through their serial ports. Their website is being updated to reflect the change.)
What about range? How far can your signal travel? This is, of course, determined by the physical layer, which is the same as that used by ZigBee. So it would be natural to assume that the range is the same as ZigBee’s. Synapse claims 3 miles open-field. Two walls cut the distance to 1.5 miles; four walls cut it to 0.75 miles. (Yes, wall construction and materials will matter… your mileage may – no, will – vary…)
Finally, one of the things that Synapse claims as a differentiator for their technology is their development environment. Apps are written using Python scripts. From a single console, you can view and update all of the nodes. If you really want to access the network remotely, then you can run SNAP Connect on a local computer (one that’s in range of the network) and then access that computer from somewhere else. SNAP Connect will forward your instructions on to the network or pull network information in and display it wherever you are.
So that’s SNAP in a nutshell. If I get a deeper dive on HaLow than the press releases contain, I will follow up.
UPDATE:
I received more details from Synapse clarifying the question about having all of the nodes sleep and awaken at the same time. As it turns out, this isn’t as much of a specific “mode” as some of the literature might make it seem. There are a number of ways of implementing this, and what I outlined above might be one such implementation. What they’ve seen more, perhaps, involves setting one node as a master. That master instructs all of the other minion nodes to go to sleep for a specified period.
This being a dynamic mesh, if something happens to the master node, then a new master must be selected. In other words, the code must have a succession plan.
The other interesting issue is what happens when the nodes all awaken. They’re all (or some) going to want to report in, telling all about everything that happened while they were asleep (and, in particular, that really creepy dream that they can’t banish from their heads). If they’re all talking at once, then no one can understand anything thanks to the massive RF demolition derby that has everyone colliding with everyone else.
So some folks use CDMA techniques to code each node so that multiple nodes can communicate on a single frequency and still be discriminated.
All of that said, there’s no one right way to do this; these are simply examples.
I also inquired as to whether Synapse is planning to submit SNAP to a standards body. The answer at present is that they do not have such plans.
More info:



Does this wireless protocol from Synapse Wireless provide features you haven’t found elsewhere?