


We’ve spent quite a bit of energy talking about various communication patterns for use in the Internet of Things (IoT). There’s the ever-popular publish/subscribe (P/S) for sending data around, and then there’s request/reply (R/R) for controlling devices.
And we’ve blithely referred to data being sucked into the Cloud for more processing before commands are sent back down to devices. But we haven’t looked in any detail at how data gets from the local infrastructure (perhaps a gateway) into the Cloud. It turns out that this is where two very different worlds meet, as described by RTI with their recent release of Connext DDS 5.2.
The world we’ve spent most of our energy on is what they refer to as “Operational Technology,” or OT. This is where data flits about amongst network nodes with fixed, limited resources. Some of that data may be used to influence machine activity or settings, so it needs to move around in as close to real time as possible. If a fire alarm detects smoke but takes even 30 seconds to decide to sound the alarm, much damage could be done.
The world of the cloud is a much different, much more traditional IT environment. It’s a bank of resources that vary over time. A message that comes in is targeted at an application that’s running – but it may be running on numerous servers. Utilities help to decide where to send the message when it comes in; load balancing figures prominently in that decision.
Living In a Virtual World
This isn’t about targeting a specific machine – at least it doesn’t have to be. Depending on the setup, applications are being increasingly abstracted away from machines. The least flexible arrangement is so-called “single-tenant” servers, where a given server is “owned” not only by a specific application, but also by a specific user. It means you get an entire machine to yourself. Which is wasteful if you’re not using up all of that machine’s available cycles.
So “multi-tenanting” enables other users to share your machine. If a particular “cloud” is dedicated to a particular application – let’s say it’s an EDA simulation environment – then all the servers have access to the same applications, and the question is whether simulations for two different (and probably competing) companies should be running at the same time on the same hardware.
Part of the concern with a shared server, of course, is whether any information can leak from one user to another. Improved virtualization and “container” schemes are under development and deployment to provide better isolation not only between users, but also between applications – and even between operating systems (OSes).
So, in theory, a single server could be running multiple OSes hosting multiple applications serving multiple users each. But, of course, if a specific box to which you send a really important message gets really busy handling requests, then it’s going to take a while before it can get to your message. So, to scale resources, this box’s setup can be replicated – lots of identical boxes running similar stuff. At any given time, you might be dealing with any of the servers.
This is, of course, how HTTP works – and it’s why RESTful applications can work well here. With a RESTful application, there’s no implied lingering state. Each message is self-sufficient. If that weren’t the case, then let’s say that message 25 was processed by server 12 and created a state that will affect how message 26 is processed. For that to work, then either that state has to be replicated across all servers to keep the state coherent, or message 26 has to go specifically to device 12, it being the only one with the desired state. It’s easier if there is no lingering state; then messages 25 and 26 can be processed by totally different servers and there are no state coherency issues.
Queue Me Up
This creates the need for a new message pattern: Queuing. And the thing is, it’s not just about establishing a queue of messages for a server; it can be a case of replicating messages and placing them in a number of queues, with those queues being kept coherent and negotiating with each other over which machine will finally handle the message.
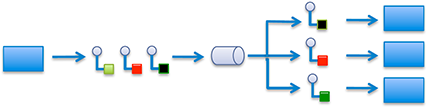
Figure 1. Queuing Pattern. The circles-with-tails represent messages; the sideways barrel is a queuing service/load balancer. Blue rectangles are applications (not servers).
(Image courtesy Real Time Innovations)
When a message comes in, it’s critical that only one application instance process it. These messages often reflect transactions (like business transactions – not necessarily in the sense of database atomic transactions). If you want to record a sale, you want to be sure that it happens only once. Double-dipping leads to bad optics if discovered by nosy auditors…
IT characteristics are quite different from OT characteristics in important ways. Latency is much higher, and data is typically intended to move at “human” speed, not “machine” speed, to use RTI’s wording. Someone may be calling up a report or trying to analyze trends. Speed is important – especially when crunching numbers in service to Big Data – but it’s different from the near-real-time requirements of many OT functions.
There are server-oriented messaging and queuing protocols that are already well established. AMQP is one that we looked at briefly in our survey earlier this year, and, compared to protocols like MQTT, it’s giant. But for IT folks, it’s natural – chock-full of features and robustnesses and reliabilities that would completely overwhelm an IoT edge node. You’ll also hear about “MQ” (message-queuing) systems like RabbitMQ or ActiveMQ. Similar deal: it’s IT.
It turns out that in RTI’s prior DDS implementations, when messages needed to go to the Cloud, they would ride over HTTP. As we’ve seen, HTTP already plays nicely with IT ways of doing things, so it was easy simply to leverage that pre-existing resource.
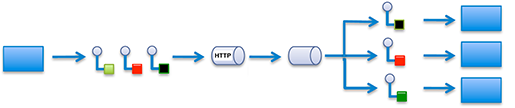
Figure 2. Here messages are sent to the Cloud via HTTP.
(Adapted from image by Real Time Innovations)
But in their latest release, they’re bypassing HTTP and going direct with a queueing service. In fact, they’re closing the loop with a request/reply-over-queuing sort of mashup. As you can see from the figure below, it’s like the first figure above, except that a new response message is generated and sent back to the sender.
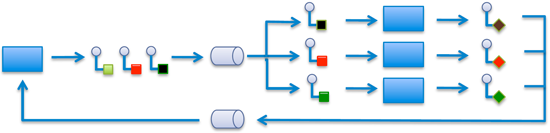
Figure 3. Symbols same as above, but note the right side, with new response messages (diamond tail instead of square tail).
(Image courtesy Real Time Innovations)
RTI claims this as the first full edge-thru-cloud platform. Removing HTTP eliminates a layer of translation for greater efficiency. They say that it also makes it easier to be flexible with the fog-cloud boundary, keeping low-latency computations local to the network while shipping harder, less timely calculations or storage up to the Cloud.
More info:


How do you connect the IT and operational technology (OT) worlds? How do your IoT Things talk to the Cloud?