


In the fall of last year, I made a stab at proposing a structure for what I perceived as the Internet of Things (IoT). I later realized that there are bigger differences than I had appreciated between the various IoT incarnations: consumer, industrial, and maybe even enterprise (I haven’t really dug into that last one yet). So the first “IoT Breakdown” really applies only to the Consumer IoT (CIoT).
But there’s a word floating around lately, one that has traditionally been used in the description of networks, that got me thinking again. I first noticed it when discussing the Hyperweave technology, which brings WiFi directly to sensors. And I started hearing it again in the last few weeks of conferences.
That word is “edge.”
I’m going to propose an alternative way of thinking about this, but before doing that, let’s review what the “edge” is to different folks. It’s about the question, “The edge of what?”
For the longest time, cellular and global networking folks would talk about the edge (not to be confused with EDGE, a transitional mobile phone technology between old GSM and 3G). To them, there was this giant core network with unbelievable volumes of data zipping about at unconscionable rates. Think of it as a big post office or FedEx operation, with packets coming in from innumerable local nodes and being aggregated into carts and then into trucks and then into bigger trucks or airplanes and sent to a few central locations for further distribution.
Of course, the analogy breaks a bit, because real packages, when combined with bigger packages, all have to go to the same location; you don’t intermix truck contents as you go. Internet packets, on the other hand, can be individually routed as they go – it’s just that these are monstrously huge, fast routers near the middle of the core.
Real packages may go all the way to the core’s center (one of a few key hubs) before starting their trek back out towards their destination. Internet packets: maybe or maybe not. But along this trip, at some point they leave the “local” realm (that might be the farm in a rural setting or a “metro” network in an urban one) and enter this core network. And on the way back out, at some point, the packet has left the core and is now in the local distribution network for final delivery.
This boundary between the core and the local was called the “edge”: the edge of the core.
Today, however, the term is being used in a different – and more intuitive – way: referring to the very outer edge of an IoT network, where remote sensors lie. While this seems more like a true edge, it’s confusing because the IoT also has this notion of “core” and local. It’s just that the core is usually referred to as the “cloud.” So by the old definition, the edge would be the local/cloud boundary; by the newer definition, it’s the outer edge of the whole shebang.
There’s another word that furthers this discussion: “fog.” This is a concept from Cisco, the idea being that some of what we think of as happening in the Cloud may happen locally, reducing the amount of data transmitted to the Cloud.
The “fog” concept is “clouds on the ground,” although it applies not as well to the Bay Area version of fog, which is usually the marine layer, which, more often than not, just looks like low clouds. It applies better to “ground fog,” or what Californians refer to as tule fog (“too-lee”; a common type of bulrush, taken from a Nahuatl name). That may sound like picking nits (and, in fact, it is), but it’s that kind of question that pervades some of the discussion of where fog and cloud differ.
In sorting through this, I find it helpful to consider that there are two broad categories of activity in the IoT:
- Operations: the ongoing business for which the network was established. I see three sub-activities here:
- Sensing/information gathering: detecting and reporting something about the environment or situation or individual;
- Decision-making: deciding what to do about the data (the decision might be “nothing”);
- Actions: the result of the decision; might be machine actuation or sending out a notification, for example.
- Management: information and adjustment of the network; here I see two broad sub-activities:
- Analytics: reporting of information on how the network is working or what data has passed through the network. Especially in the latter case, this may involve decision-making on the part of whoever is viewing it, but it’s done on the human scale. The operations’ “decision-making” is done automatically by computers of some sort.
- Control: This is where a human makes some change to how the network operates. It might involve, for instance, making a change to business rules that govern decision-making.
I suppose I should include one more category: sending all our data to the marketers for better advertising, since we know that’s what this technology is ultimately all about, but I won’t get distracted with that.
Sensing happens locally, almost by definition. Management happens most frequently in the Cloud – simply because remote access is pretty much required for that to be broadly useful. Actions will be taken locally if they involve machine actuation; it’s less clear where they happen for notifications – it depends on where the decisions are made.
And the decision-making is the step that’s the biggest question mark for this whole thing. There are two possible characteristics we could use to define decision-making: “Where does the decision get made?” and, “What kind of machine is used to make the decisions?”
The “where” characterization really comes down to one question: how is the data to and from the decision-maker communicated? Does it stay on a local network, or does it enter that “core” network for delivery to the Cloud?
The “what type of machine” characterization deals with whether a server (or, more typically, server farm) is used to compute the decision, or whether it’s made by some smaller “gateway.” We’ll come back to that in a minute.
The communication view of things is probably the most obvious, and, the more I think about it, the more I see Saturn (sort of) in the architecture. There are simply two concentric rings. Or rather, one circle surrounded by a ring.
The circle is the Cloud, which I’m defining as a set of computing resources accessed by leaving the local network and traveling through the core network. The outer ring is the local domain. The boundary between them is the older notion of “edge.”
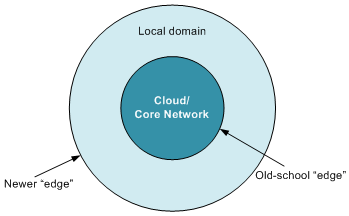
And, to me, the crux of the whole “fog” discussion comes down to one question: what is the width of the outer ring? (As there are no natural units for expressing that width, this becomes a hard question to answer in a concrete fashion, but, to me, anyway, it simplifies how I view the problem.)
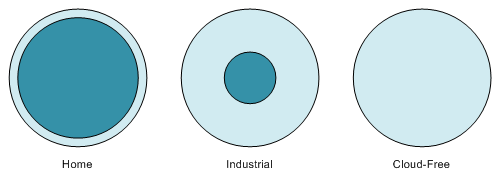
- For CIoT – largely home – installations, most of the data goes to the cloud for sale to others decision-making. Some things may stay local: for instance, you might want your door lock to work even when the power or internet connection is down, so you might keep that communication local (and minimal).
- Industrial IoT (IIoT) setups, however, involve copious amounts of data, much of which stays local, being filtered by gateways and routers. There the outer ring is much wider.
- Just for comparison: with a Cloud-free installation, the inner circle would shrink to nothing.
This ring structure is defined by the communications – local vs. core – but then we’re faced with the question of what fits into each circle. You might think that our communications definition simply brings this along with, but it’s not quite that easy.
There are two things that characterize the Cloud: it’s a bunch of servers that you connect to remotely. I’ve highlighted the two key words. Our focus so far has been on the “remotely” characteristic. But what if it’s the “server” bit that really matters? After all, part of the justification for the Cloud is that it can offload more sizeable computations from the Thing at the edge, which has limited resources. By pushing calculations to the Cloud, you make Things less expensive and less power-hungry, and that spurs adoption.
But does it matter whether the server is remote or local?
With the IIoT, we’ve talked about the gateways that help with the decision-making process. These gateways typically aren’t of the computing scale of a server. You might think of them as routers with extra cycles and the ability to host non-routing applications. So those are definitely in the outer ring.
But if the hard problems get deferred to a local server farm, without entering the “core” network, should that still be modeled as being in the cloud – the center ring – or in the outer ring? I haven’t come down with a hard answer on that one (and I encourage your opinions below), but I’m leaning to saying that local servers go in the outer ring, even though they act as a cloud.
Why? I’ve come to that by asking the question, “Does it matter whether the server is local or remote?” Just like a well-designed user interface, such an architectural feature should be transparent to the user. The user should never have to think about where the calculations are happening, making this an academic discussion.
Except for one thing: latency. Each step away from the sensor involves latency. But there’s a big jump when you hop onto the core network to get to a remote server. And there are times when that latency matters. For industrial control, for example: you might need something closer to real time for some actions. So to me, because of this latency distinction, I tend to revert to the communication network as defining the difference between the inner and outer rings.
And yet, even so, it’s not completely cut-and-dried. Yet one more characteristic of the Cloud is that it’s owned by someone else; you’re merely buying services from the server owner. You would own a local server farm yourself. But… what if you own your server farm, but it’s located in a different place? Meaning that, to get there, your data needs to hop onto the core network to get to a different country, for example? Now your private server farm looks more like the Cloud than a local server farm.
So, to summarize, I would place entities thusly:
- Outer ring:
- Sensors and actuators
- Gateways and routers
- Local (really local) server farms
- Inner circle:
- Commercial Cloud
- Private server farms that aren’t local
In a home installation, the outer ring is narrow because it contains only sensors and actuators and maybe some limited local intelligence. In an industrial setup, the outer ring is typically wider because it also includes gateways and routers – and is wider yet if it includes local servers.
It’s a pretty simple model – almost simplistic – and yet I personally find it useful in abstracting the overwhelming details that can take over when discussing an IoT setup. Whether you also find it helpful, well, you can let us know below.



What do you think about this IoT architecture concept? What items would you put in the outer ring or the inner circle?
Good post.
[[And the decision-making is the step that’s the biggest question mark for this whole thing. There are two possible characteristics we could use to define decision-making: “Where does the decision get made?” and, “What kind of machine is used to make the decisions?”]]
The question regarding where to make decisions is relevant, and the answer is likely “it depends”.
One thing left out is “perspective”, beyond proximity of local (less hops/latency) vs capacity of centralized (compute power) – the farther you move away from an event the broader your perspective, as decisions can be modeled against the big picture and benefit from more data points.
The question then shifts to global vs local optima, and this becomes a factor of use-case. Is it better to make a faster decision locally then wait for a context-enhanced decision? Demands for immediate local action can be tempered by remote decisions to balance a broader system.
So this becomes a systems-of-systems architecture.
As to how analysis happens, it won’t be done by bloated application middleware stacks. Middleware itself needs to be re-invented to support distributable and elastically scalable reasoning.
Excellent thoughts. While keeping local computation light is obviously a consumer consideration, there’s so much crowdsourced data being brought to bear in the decisions – or so the promise is – that the cloud is the only place to do that (CloudSourcing?).
I’ll be curious to see whether all that information and complexity can be boiled down into decisions that feel natural to users, rather than the, unfortunately, all-too-common “Nice try, but you got it wrong” results of prior (and some current) attempts.